Y a-t-il un modèle dans ce chaos ? Essayons de le trouver ! Apprentissage automatique sur l'exemple d'un échantillon spécifique. - page 21
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
J'ai supprimé deux années supplémentaires de cet échantillon et la moyenne de l'examen est déjà passée à -485 (elle était de 1214) et le nombre de modèles qui ont dépassé la limite des 3000 points est passé à 884 (il était de 277 la dernière fois ).
Cependant, les résultats sur l'échantillon de test se sont détériorés, passant d'une moyenne de 2115 à 186 points, c'est-à-dire de manière significative. Qu'est-ce que cela signifie ? Y a-t-il moins d'exemples dans l'échantillon d'entraînement que dans l'échantillon de test ?
Le nombre moyen d'arbres est passé de 10 à 7.
La rupture du zéro sur le graphique a déplacé la distribution de l'équilibre vers le centre.
Sur quoi se fonde l'affirmation selon laquelle le résultat doit être similaire au test? Je suppose que les échantillons ne sont pas homogènes - ils ne contiennent pas un nombre comparable d'exemples similaires, et je pense que les distributions de probabilité sur les quanta diffèrent quelque peu.
Traine. Je parle de données pour lesquelles il existe de bons modèles. Si vous introduisez 1000 variantes de la table de multiplication dans l'apprentissage, les nouvelles variantes qui ne correspondent jamais à la trace (mais qui se trouvent à l'intérieur des limites de la trace) se calculeront également assez bien. 1 arbre donnera la variante la plus proche, une forêt aléatoire fera la moyenne des cent variantes les plus proches et donnera très probablement une réponse plus précise que celle d'un seul arbre.
Si des prédicteurs réguliers peuvent être trouvés pour le marché, alors l'OOS sera également similaire à une trace. Mais pas comme aujourd'hui, où plus de la moitié des modèles sont négatifs et un tiers sont positifs. Tous les modèles réussis sont devenus ainsi par hasard, à partir d'une semence aléatoire.
La semence ne devrait modifier que légèrement le succès du modèle et, en général, tous les modèles devraient être réussis. Or, il s'avère qu'aucun modèle n'a été trouvé (surentraînement ou sous-entraînement).
Il n'intervient que pour contrôler l'arrêt de l'entraînement, c'est-à-dire que s'il n'y a pas d'amélioration sur le test pendant l'entraînement sur le train, l'entraînement s'arrête et les arbres sont supprimés jusqu'au point où il y a eu la dernière amélioration sur le modèle de test.
On comprend alors pourquoi les tests sont également bons. Il s'agit essentiellement de s'adapter au test. J'ai arrêté de le faire pour 1 formation. Je fais de la valvulation vers l'avant, je colle tous les OOC ensemble, puis je choisis les meilleurs hyperparamètres du modèle (profondeur, nombre d'arbres, etc.) parmi les nombreuses variantes d'OOC collés. Je suppose que l'examen sera à peu près le même que le collage sélectionné de tous les OOC. Dans cette variante, sur 5 ans, je me suis entraîné une fois par semaine, ce qui représente des centaines d'entraînements et de morceaux.
Apparemment, je n'ai pas clairement indiqué l'échantillon que j'ai utilisé - il s'agit du sixième (dernier) échantillon de l'expérience décrite ici, et il n'y a donc que 61 prédicteurs.
Les stratégies primitives, en particulier dans les zones de marché plat.Vous avez choisi ces 61 prédicteurs sur plus de 5 000. Mon nombre total est inférieur et le nombre de prédicteurs sélectionnés est inférieur. Et lorsque l'on ajoute un prédicteur à la fois, après 3 ou 4 prédicteurs sélectionnés, l'ajout d'autres signes ne fait qu'aggraver le résultat sur l'OOS.
En général, je peux ajouter plus de prédicteurs, parce que maintenant ils ne sont utilisés qu'avec 3 TF, à quelques exceptions près - je pense que quelques milliers d'autres peuvent être ajoutés, mais il est douteux qu'ils soient tous utilisés correctement dans la formation, étant donné que 10000 variantes de semences pour 61 prédicteurs donnent une telle dispersion....
Et bien sûr, il faut présélectionner les prédicteurs, ce qui accélère la formation.
S'ils sont tous à peu près identiques, il est peu probable que l'on trouve quelque chose qui améliore sérieusement le résultat. Vous pouvez essayer de nouvelles données ou des indicateurs uniques.
Le filtrage préliminaire est également un travail de longue haleine, l'ajout d'une caractéristique à la fois est beaucoup plus long, même jusqu'à 3 caractéristiques, et si c'est jusqu'à 10, cela prend plusieurs jours. Mais cela n'a aucun sens, après 3-4 caractéristiques, il n'y a généralement pas d'amélioration. Parfois, il y en a, mais l'augmentation est faible. Il n'y a pas eu de percée dans ce domaine (dans mes expériences, quelqu'un pourrait en trouver).
Il est logique que les valeurs aberrantes soient des valeurs aberrantes, je pense simplement qu'il s'agit d'inefficacités, qui devraient être apprises en éliminant le bruit blanc. Dans d'autres domaines, les stratégies primitives simples fonctionnent souvent, en particulier dans les marchés plats.
Le tableau du bas est rentable, mais en 5 ans, il n'y a eu que 2 périodes en 2017 avec une forte croissance (apparemment il y avait une forte tendance prévisible), le modèle a gagné le plus d'argent sur ces 2 périodes. Et ce serait bien d'avoir une croissance uniforme dans le temps. Je désactiverais un tel modèle après un mois d'inactivité.
Vous pouvez bien sûr créer un EA - en attendant les cygnes blancs. Mais je préférerais un trading actif.
Si l'on retranche deux années supplémentaires à cet échantillon, la moyenne à l'examen est déjà passée à -485 (contre -1214), et le nombre de modèles dépassant la limite des 3000 points est passé à 884 (contre 277 la dernière fois ).
Cependant, les résultats sur l'échantillon de test se sont détériorés, passant d'une moyenne de 2115 à 186 points, c'est-à-dire de manière significative. Qu'est-ce que cela signifie ? Y a-t-il moins d'exemples dans l'échantillon de formation similaires à l'échantillon de test ?
Le nombre moyen d'arbres est passé de 10 à 7.
La rupture du zéro sur le graphique a déplacé la distribution de l'équilibre vers le centre.
Pouvez-vous poster les fichiers du premier message, je veux aussi essayer une idée.
Traine. Je parle de données pour lesquelles il existe de bons modèles. Si vous soumettez 1000 variantes d'une table de multiplication à des fins de formation, les nouvelles variantes qui ne coïncident jamais avec la trajectoire (mais qui se trouvent à l'intérieur des limites de la trajectoire) seront également bien calculées. 1 arbre donnera la variante la plus proche, une forêt aléatoire fera la moyenne des cent variantes les plus proches et donnera très probablement une réponse plus précise que celle d'un seul arbre.
Si des prédicteurs réguliers peuvent être trouvés pour le marché, alors l'OOS sera également similaire à une trace. Mais pas comme aujourd'hui, où plus de la moitié des modèles sont négatifs et un tiers sont positifs. Tous les modèles réussis sont devenus ainsi par accident, à partir d'une graine aléatoire.
La semence ne devrait modifier que légèrement le succès du modèle et, en général, tous les modèles devraient être réussis. Il s'avère maintenant qu'aucun modèle n'a été trouvé (qu'il s'agisse de surentraînement ou de sous-entraînement).
Personne ne prétend qu'avec de bonnes données, tout fonctionnera parfaitement. Mais comme il est impossible d'obtenir de telles données, il faut réfléchir à ce que l'on peut tirer de ce que l'on a.
Le fait qu'il soit possible d'obtenir des modèles efficaces de manière aléatoire, qui seront efficaces sur de nouvelles données, m'amène à me demander comment réduire ce caractère aléatoire, c'est-à-dire s'il existe des métriques régulières pour les segments quantiques, sur lesquelles le modèle a été construit de manière cohérente. En d'autres termes, nous parlons de métriques supplémentaires autres que l'avidité de la cible. Si de telles dépendances peuvent être établies, alors les modèles peuvent également être construits avec une plus grande probabilité de succès. Bien entendu, cela devrait fonctionner sur des échantillons différents.
Je comprends alors pourquoi les tests sont bons aussi. Il s'agit essentiellement de s'adapter au test. J'ai arrêté de le faire pour 1 étude. Je fais le valving vers l'avant, je colle tous les OOCs ensemble, puis je choisis les meilleurs hyperparamètres du modèle (profondeur, nombre d'arbres, etc.) parmi les nombreuses variantes des OOCs collés. Je suppose que l'examen sera à peu près le même que le collage sélectionné de tous les OOC. Dans cette variante, sur 5 ans, je me suis recyclé une fois par semaine - ce qui représente des centaines d'entraînements et de morceaux d'OOS.
L'essentiel est de ne pas séparer la dernière section de l'examen.
Ajuster des hyperparamètres et évaluer le résultat sur quoi ? Je pense qu'il s'agit du même ajustement avec un élément de moyenne, si nous suivons votre logique.
La logique de CatBoost est que s'il est impossible d'améliorer le modèle (par Logloss), il est inutile de poursuivre l'entraînement. Dans ce cas, il n'y a aucune garantie que le modèle s'avère bon, bien sûr.
Eh bien, ce sont les 61 que vous avez choisis sur plus de 5000. J'ai à la fois le nombre total et le nombre de ceux qui ont été sélectionnés. Et quand on ajoute 1 à la fois, après 3-4 sélectionnés, l'ajout de caractéristiques supplémentaires ne fait qu'empirer le résultat sur OOS.
Non, je ne les ai pas choisies - je les ai retirées du modèle lors de l'entraînement sur tous les prédicteurs.
Je considère généralement le prédicteur comme un ensemble de segments quantiques. C'est pour cette raison que je sélectionne des segments quantiques. En général, je peux même décomposer tous les prédicteurs en prédicteurs binaires - le résultat est légèrement moins bon, mais comparable. Peut-être que pour les prédicteurs binaires déchargés, une méthode spéciale d'entraînement est nécessaire.
S'ils sont tous à peu près identiques, il est peu probable que l'on puisse déjà trouver quelque chose qui améliore sérieusement le résultat. Vous pouvez essayer de nouvelles données ou des indicateurs uniques.
Qu'entendez-vous par "à peu près les mêmes", je suppose que vous parlez de métriques ou autres ? Bien sûr, vous pouvez essayer des données différentes, prendre un outil différent par exemple.
La présélection est également un travail de longue haleine, l'ajout un par un prend beaucoup plus de temps, même jusqu'à 3 caractéristiques, et si c'est jusqu'à 10, cela prend plusieurs jours. mais cela ne sert à rien, après 3-4 caractéristiques, il n'y a généralement pas d'amélioration. Parfois, il y en a, mais l'augmentation est faible. Il n'y a pas eu de percée dans ce domaine (dans mes expériences, quelqu'un pourrait en trouver).
La variante dont vous parlez est un jeu de longue haleine, c'est pourquoi je n'y joue pas (enfin, je n'ai pas d'automatisation complète). Mais je ne suis pas d'accord pour dire qu'il n'y a pas d'effet - j'ai fait des abandons dans des groupes, avec la réduction des groupes - le résultat a été positif. Mais je continue à attribuer ces actions à l'ajustement ou au hasard - il n'y a pas de justification pour le choix des prédicteurs.
Le chiffre du bas est rentable, mais en 5 ans il n'y a eu que 2 périodes en 2017 avec une forte croissance (apparemment il y avait une forte tendance prévisible), le modèle a gagné le plus d'argent sur ces 2 périodes. Et ce serait bien d'avoir une croissance uniforme au fil du temps. Je désactiverais un tel modèle après un mois d'inactivité.
Bien sûr, vous pouvez créer un Expert Advisor qui attend les cygnes blancs. Mais je préférerais un trading actif.
C'est pourquoi je suis favorable à l'utilisation d'ensembles de modèles, car je comprends que chacun d'entre eux peut attraper ses propres modèles peu fréquents.
En général, l'objectif est que l'erreur sur la formation et le test soit à peu près la même. Ici, votre examen se rapproche de l'entraînement et du test, c'est-à-dire qu'il augmente, et ils se rapprochent du test, c'est-à-dire qu'ils diminuent. Le surentraînement diminue.
Et selon quelle métrique sont-ils similaires ?
Prenons par exemple la mesure de la précision, soustrayons l'indicateur de l'échantillon de test de celui de la formation, nous obtenons le delta (axe des y), et par x nous regardons le profit sur l'échantillon d'examen.
Il n'y a pas de dépendance particulière, ou quoi ?
Voici deux mesures pour chaque échantillon - les données sont prises au fur et à mesure que de nouveaux arbres sont ajoutés au modèle.
Voici les caractéristiques de ce modèle
Et voici les métriques d'un autre modèle, avec des pertes sur deux échantillons
Voici les caractéristiques du modèle
Il n'est pas pratique de répondre dans le style du forum, en cliquant plusieurs fois sur répondre. Mes réponses sont surlignées en couleur ci-dessous.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> J'ai regardé il y a longtemps comment les quanta sont construits, avec des variantes de base. Tout d'abord, la colonne est triée.
1) par plage, pas pair (par exemple, de 0 à 1 avec un pas de valeur passant exactement par 0,1, totalisant 10 quanta 0,1, 0,2, 0,3 ... 0,9)
2) par centile - c'est-à-dire par le nombre d'exemples. Si nous divisons par 10 quanta, nous mettons dans chaque quantum 10 % du nombre de toutes les lignes. S'il y a beaucoup de doubles, certains quanta seront supérieurs à 10 %, car les doubles ne doivent pas tomber dans d'autres quanta, par exemple, si les doubles représentent 30 % de l'échantillon, ils tomberont tous dans ce quantum. En fonction du nombre d'échantillons dans chaque quantum, la distribution pourrait être de 0,001, 0,12,0,45,0,51,0,74, .... 0,98.
3) il y a une combinaison des deux types
Il n'y a donc rien de très astucieux dans la construction des quanta. J'ai créé ces deux méthodes de quantification pour moi-même. Et comme toujours, j'ai fait quelque chose de la manière que je pense être la meilleure. J'ai peut-être fait une erreur. Et j'ai l'habitude de faire des calculs sans quantification, mais sur des données flottantes.
Si tous les prédicteurs sont binaires, il n'y aura que deux quanta, l'un contenant tous les 0 et l'autre tous les 1.
Vous ajustez des hyperparamètres et évaluez le résultat sur quoi ? Je pense qu'il s'agit du même ajustement avec un élément de calcul de la moyenne, si vous suivez votre logique.
> Je regarde les graphiques d'équilibre et les drawdowns. Je n'ai pas encore réussi à automatiser la sélection. Oui, l'ajustement est destiné à améliorer le collage OOS. Mais pas le modèle lui-même (c'est-à-dire pas la trace), mais la sélection des meilleurs hyperparamètres du modèle.
Que voulez-vous dire par "à peu près la même chose", je suppose que vous parlez de certaines métriques ou autres ? Bien sûr, vous pouvez essayer d'autres données, prendre un autre outil par exemple.
> Tous ces outils sont basés sur les prix et les mashups.
Sur une vieille question.
Sur quoi se fonde l'affirmation selon laquelle le résultat doit être similaire au train? Je suppose que les échantillons ne sont pas homogènes - il n'y a pas de nombre comparable d'exemples similaires, et je pense que les distributions de probabilité des quanta sont légèrement différentes.
> Exemples ici https://www.mql5.com/ru/articles/3473
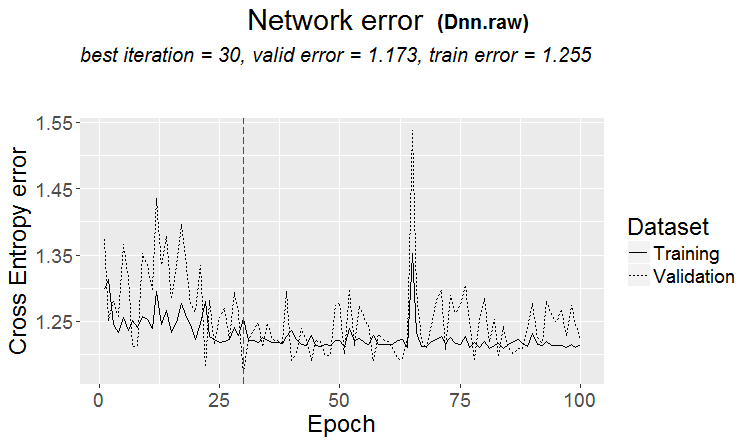
Une bonne variante est lorsqu'un modèle est trouvé : le ternaire et le test ont presque la même erreur
Sur les marchés, il se produit plus souvent quelque chose comme ceci : un bon test, mais après une certaine étape de la formation (dans la figure après la 3e étape), le recyclage commence et l'erreur de test commence à augmenter. Les images se réfèrent aux réseaux neuronaux, mais il y a aussi quelque chose comme ça avec les forêts et les boosts, quand le modèle devient surentraîné.
Selon quelle métrique ces modèles sont-ils similaires ?
Mais cela ne veut pas dire que vos métriques sont mauvaises.
Il n'y a donc rien de très intelligent dans la construction quantique. J'ai créé ces deux méthodes de quantification pour moi-même. Et comme toujours, j'ai fait quelque chose de la manière que je pense être la meilleure. J'ai peut-être fait une erreur. Et j'ai l'habitude de faire des calculs sans quantification, mais en utilisant des données flottantes.
Bien sûr, il existe différentes méthodes, j'utilise environ 900 tables quantiques aujourd'hui.
L'important n'est pas la méthode, mais le choix de la plage du prédicteur dans laquelle la valeur moyenne de la cible binaire est supérieure à celle de l'échantillon (je fixe maintenant un minimum de 5 % plus des critères sur le nombre d'exemples - également un minimum de 5 %), ce qui indique la présence d'informations utiles dans le prédicteur. En l'absence de telles informations, vous pouvez espérer qu'elles apparaîtront dans quelques divisions, mais je pense que c'est moins probable.
En fait, il arrive qu'il y ait une ou deux parcelles de ce type, mais rarement un grand nombre. Dans ce cas, vous pouvez soit ne prendre que ces tracés, soit ne prendre que les prédicteurs avec ces tracés, en choisissant le meilleur tableau quantique.
Personnellement, j'ai vu que les prédicteurs, du moins le mien, n'ont pas de transitions lisses de la probabilité, mais plutôt qu'elles se produisent de manière discontinue et passent à la déviation opposée, c'est-à-dire qu'elle était de +5 et est immédiatement devenue de -5. Je pense même que si ces probabilités sont ordonnées, le modèle sera plus facile à entraîner, car il est entraîné sur des fourchettes. C'est la raison pour laquelle il est judicieux d'exclure les zones non informatives et de séparer les zones conflictuelles.
Si vous rendez tous les prédicteurs binaires, il n'y aura que 2 quanta, l'un avec tous les 0 et l'autre avec tous les 1.
En fait, il n'y en aura qu'un seul - 0,5 :) Mais, de cette façon, vous pouvez décomposer le prédicteur en plages utiles (contenant des informations potentiellement utiles).
> Je regarde les graphiques d'équilibre et les drawdowns. L'automatisation de la sélection n'a pas encore fonctionné. Oui, l'ajustement - pour le meilleur collage OOS. Mais pas le modèle lui-même (c'est-à-dire pas la trace), mais la sélection des meilleurs hyperparamètres du modèle.
C'est compréhensible, mais pas canonique - les métriques du modèle sont également importantes, je pense.
> Tout cela est fait sur des prix et des mashups.
En théorie oui, et cela si vous utilisez des réseaux neuronaux, mais en fait - non - des dépendances trop complexes devraient être recherchées avec différents calculs, pour cela n'ont tout simplement pas la puissance de calcul des utilisateurs ordinaires.
Sur une vieille question.
> Exemples ici https://www.mql5.com/ru/articles/3473
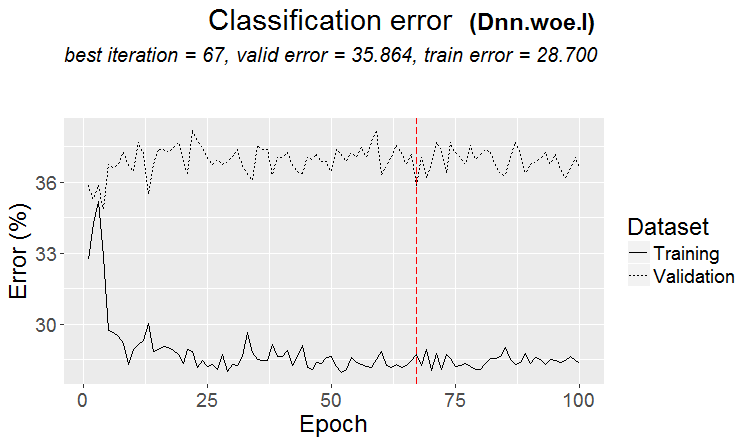
Une bonne variante est lorsqu'un modèle est trouvé : le ternaire et le test ont presque la même erreur
Sur les marchés, il se produit plus souvent quelque chose comme ceci : un bon test, mais après une certaine étape d'entraînement (dans la figure après la troisième), le recyclage commence et l'erreur de test commence à croître. Les images se réfèrent aux réseaux neuronaux, mais il y a aussi quelque chose comme ça avec les forêts et les boosts, quand le modèle devient surentraîné.
La régularité est toujours trouvée - c'est le principe - la question est de savoir si cette régularité va continuer à apparaître ou non.
Je ne sais pas quel type d'échantillon vous aviez. Il m'est arrivé que le test apprenne plus vite que l'entraînement, mais le plus souvent, c'est l'inverse qui se produit et il y a un delta perceptible entre les deux. Dans des conditions idéales, la différence sera faible, bien sûr.
Je peux affirmer avec certitude que les modèles sont sous-entraînés simplement parce que les échantillons ne sont pas très similaires et que l'entraînement s'arrête lorsqu'il n'y a pas d'amélioration.
Un jour, je vous montrerai l'aspect graphique de l'échantillon recyclé - il s'agit de deux bulles séparées par des coins....
Réduisez encore de moitié l'échantillon de formation.
Il n'y a que 306 modèles, le bénéfice moyen par examen est de -2791 points.
Mais j'ai obtenu ce modèle
Avec ces caractéristiques
L'espérance de mat a certes baissé, mais le rappel a augmenté deux fois - à cause de cela et d'un tel graphique avec un grand nombre d'affaires.
De tels prédicteurs ont été utilisés :
Et il y en a 9 de moins que dans l'échantillon - je vais essayer de ne prendre qu'eux et de m'entraîner sur l'ensemble de l'échantillon (sur toutes les lignes de train).
Les scissions ne sont effectuées que jusqu'au quantum. Tout ce qui se trouve à l'intérieur du quantum est considéré comme ayant les mêmes valeurs et n'est pas divisé davantage. Je ne comprends pas pourquoi vous cherchez quelque chose dans le quantum, son objectif principal est d'accélérer les calculs (l'objectif secondaire est de charger/généraliser le modèle de sorte qu'il n'y ait plus de fractionnement, mais vous pouvez juste limiter la profondeur des données flottantes) Je ne l'utilise pas, je fais juste des modèles sur des données flottantes. J'ai effectué une quantification sur 65 000 pièces - le résultat est absolument le même que le modèle sans quantification.
Personnellement, j'ai constaté que les prédicteurs, du moins le mien, n'ont pas de transitions douces de la probabilité, mais qu'elles se produisent brusquement et passent à la déviation opposée, c'est-à-dire qu'elles étaient de +5 et sont immédiatement devenues de -5.
J'ai également remarqué quelque chose comme ceci. Augmenter la profondeur de 1 modifie considérablement la rentabilité, parfois en +, parfois en -.
En fait, il y aura un - 0,5 :) Mais, de cette façon, il sera possible de diviser le prédicteur en plages utiles (contenant des informations potentiellement utiles).
Il y aura une division qui divisera les données en deux secteurs - l'un avec tous les 0, l'autre avec tous les 1. Je ne sais pas ce qu'on appelle quanta, mais je pense que quanta est le nombre de secteurs obtenus après quantification. Il s'agit peut-être du nombre de divisions, comme vous l'entendez.