Les réseaux neuronaux. Questions des experts. - page 3
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Continuer à expérimenter les réseaux neuronaux et arriver à e.... Je ne comprends pas, soit ils sont "idiots", soit c'est moi. J'espère vraiment que c'est moi. Je vous rappelle que je fais tout en statstica. Je me suis découragé à cause de cela. J'ai donné à la grille deux séries, la corrélation entre elles (en direction, pas en amplitude) = 100%, visuellement elles sont les mêmes et la gamme de prix est également à peu près égale. Après cela, j'ai construit l'EMA sur une ligne, mais pas de la première à la dernière barre, mais de la dernière à la première, c'est-à-dire que l'EMA va d'abord et ensuite le prix. J'ai coupé la queue droite (la fin du graphique où l'EMA forme ses valeurs) et j'ai donné la tâche à la grille basée sur la ligne 1, la ligne 2 et l'EMA de la ligne 1 pour me dire où sera l'EMA (avec la même période) pour la ligne 2. J'ai obtenu une précision de 2-005e. Cela semble bon (voire très cool), mais on peut obtenir la même précision avec la formule la plus simple, qui n'a même pas besoin d'être comptée dans une colonne))))). De plus, l'EMA prédite était toute croche et vacillait d'une barre à l'autre. Dyams.... Messieurs les pros, qu'est-ce que je fais de mal ? En fait, cette tâche comporte de nombreux conseils pour la grille et il ne s'agit même pas des prévisions. Des formules banales et simples répètent les résultats des réseaux et même mieux, mais elles sont tellement stupides qu'on ne sait plus ce que les réseaux peuvent faire en principe ? Je veux vraiment croire que je ne comprends pas bien comment les filets doivent être installés et que je fais quelque chose de mal. Je joins une photo.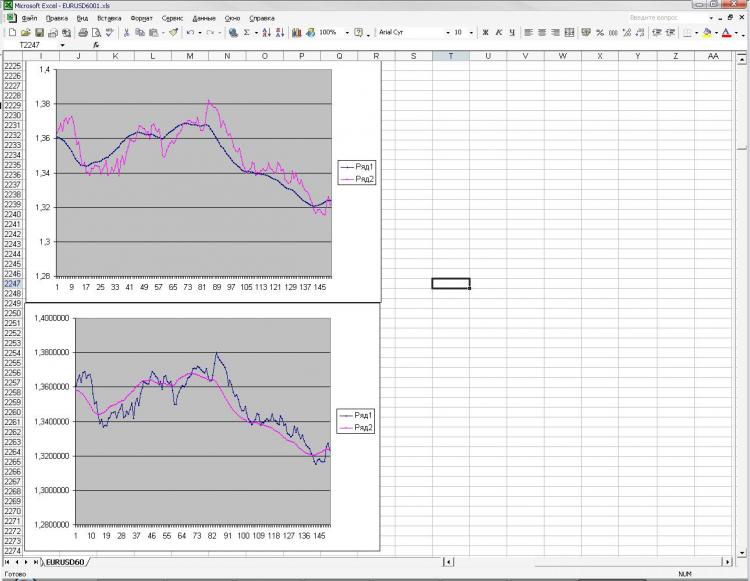
Le réseau avait pour tâche d'obtenir l'EMA de la deuxième image en connaissant l'EMA de la première et également toutes les clauses de la première et de la deuxième ligne. L'EMA va dans la direction opposée (c'était la tâche).
Je suis d'accord, mais nous nous battons pour un profit maximum. Et ici, une erreur minimale ne nous donne pas le bénéfice maximal. Au moins, je n'ai trouvé aucune preuve de cela dans le mien.......
Peut-être que je me trompe.... Je pense que vous devriez chercher d'autres entrées pour le réseau. La répétabilité des entrées n'est pas bonne.
Combien de couches et de neurones ?
1) Ai-je bien compris qu'un réseau neuronal n'est pas capable de reconstruire une fonction si elle est intrinsèquement dynamique comme dans le cas du CAC, même en ayant toutes les données nécessaires pour la calculer, car si la formule est rigidement statique comme dans le cas du LVSS ou de l'EMA, il n'y a pas de problème.
2) Si je me trompe, quels sont les réseaux à utiliser ? Et utilisé MLP dans les statistiques.
3) J' ai entendu dire que les filets automatiques et les filets de conception propre e...., si je puis dire, ne sont pas fondamentalement très différents. Est-ce vraiment le cas?
4) Quels réseaux et quels programmes conseillez-vous pour une application sur les marchés financiers, en particulier pour la tâche que j'ai décrite, c'est-à-dire la restauration des valeurs à partir de toutes les données connues.
Respectueusement, mrstock.
1. Les entrées doivent correspondre à 10 fois la période de la MA la plus lente de l'ACC. La valeur de l'EMA dépend généralement du nombre de barres, dix fois son paramètre Période. Un seul neurone avec une fonction de transfert linéaire est le mieux adapté pour répéter l'EMA. Pour l'ACC, vous auriez probablement besoin d'une autre couche, d'une couche et encore d'un neurone, ce qui n'est pas suffisant.
2. C'est ce qui est considéré comme le plus difficile - le choix du type de réseau et de sa configuration. Si avec l'EMA un seul neurone linéaire est suffisant (juste un additionneur avec différents poids d'entrées) pour l'ACC peut-être qu'une combinaison de neurones linéaires et sigmoïdes et l'utilisation de multiplicateurs au lieu d'additionneurs serait mieux.
Si la nature de la régularité souhaitée n'est pas du tout connue, il faut se contenter d'expérimenter - essayer tous les types de réseaux. Il suffit de s'entraîner correctement. Plus il y a d'échantillons à entraîner et moins il y a de neurones dans le réseau, mieux c'est. Après l'entraînement, vérifiez sur les données de contrôle quel réseau donne le meilleur résultat avec le plus petit nombre possible de neurones dans ce réseau.
1) La grille est capable de récupérer la fonction si les données d'entrée la contiennent. Si dans la dernière expérience, la valeur de la période dépend de la volatilité, alors la grille aurait dû donner une estimation de cette volatilité, c'est-à-dire que vous n'avez peut-être pas fourni toutes les données nécessaires à la récupération.
2) Vous pouvez extraire tout ce dont vous avez besoin de MLP. Utilisez d'autres réseaux lorsque vous pouvez prouver mathématiquement que l'utilisation d'une autre architecture est meilleure que MLP.
3)NS2 - rapide, résultat de qualité, facile à transférer partout...
Vous n'avez pas besoin d'introduire la valeur de la volatilité, dans l'idée que le réseau lui-même devrait détecter cette volatilité, peut-être que des neurones devraient être ajoutés, et pour former, plus d'échantillons à former.
... De plus, l'EMA prédite était toute croche et vacillait d'une barre à l'autre...
Probablement trop de neurones dans le réseau. Probablement quelque chose d'autre avec la normalisation des valeurs d'entrée.
à mrstock
Si vous avez soumis pour la formation exactement ce qui est montré dans les images, alors je suis d'accord avec Integer, le problème, entre autres, est dans la normalisation.
à LeoV et StatBars
Si la NS le permet, essayez d'utiliser l'erreur moyenne racine au lieu de l'erreur RMS. N'oubliez pas de nous faire part de vos impressions.
PS à mrstock
Essayez d'utiliser les incréments comme échantillon de formation. Dans Statistica il n'y a pas de normalisation automatique d'ailleurs.
joo писал(а) >>
Essayez d'utiliser les incréments comme échantillon de formation.
C'est probablement mieux que le logarithme de l'incrément...
Наверное, лучше логарифм приращения...
Essayez de jouer avec le paramètre tout en le faisant :
- paramètre pour la pente de la fonction d'activation sigmoïdale.
Si nous disons que nous voulons gagner de l'argent à l'aide des réseaux, mais pas pour faire des expériences de prédiction ou construire une autre bicyclette, alors la prédiction des prix ou l'EMA à partir du prix a été abandonnée au siècle dernier en raison de la futilité de cette action (en termes de gains).