Pourquoi la distribution normale n'est-elle pas normale ? - page 4
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
L'horreur. Les gens qui lancent des mots comme ça, je n'ai rien à faire ici.
Je lis, j'essaie de comprendre sur quoi ils vont se mettre d'accord.
Si c'est la première tentative d'un autre agneau de mettre une paire de froufrous sur une pieuvre, c'est une chose. Si c'est quelque chose de pratique, je participerai.
Alors, Neutron est venu et a tout remis à sa place. Au fait, Marketeer parle aussi de l'aplatissement et de l'asymétrie.
La courbe gaussienne correspondante peut être tracée comme vous le souhaitez, mais ici le plus simple est de calculer simplement la variance de l'échantillon et de tracer une courbe gaussienne avec les paramètres 0 et sigma. C'est alors que vous pouvez voir la différence entre un véritable histogramme et une telle courbe gaussienne.
À propos, cette approximation gaussienne devrait être nettement inférieure à l'histogramme réel au centre de la courbe (au point zéro).
Urain, par combien avez-vous multiplié le s.c.o. des échantillons ?
D'un autre côté, l'estimation de la c.s.o. pour une distribution à queue fortement épaisse dépend de la taille de l'échantillon, donc ce n'est pas si simple ici.
Je n'ai pas du tout touché à la valeur RMS, j'ai simplement pris le graphique tout fait et l'ai mis à l'échelle pour qu'il s'adapte à l'histogramme verticalement.
L'histogramme est la distribution de la différence de Clos (il a ME et RMS) et ces ME et RMS sont utilisés pour construire la ligne rouge en utilisant la formule ci-dessus, mais comme la ligne est perdue au bas de l'histogramme et que les petites valeurs absolues x pour construire un histogramme y proportionnel sont à blâmer, nous avons dû multiplier chaque ligne y par un multiplicateur pour la comparaison.
Pour la fonction de référence, la variance et le MO sont tirés d'un certain nombre de devis (également calculés à cet endroit) et fixés à la même valeur, mais la seule manipulation concerne les valeurs absolues du benchmark, ici nous devons ajouter chaque terme au coefficient pour combiner les sommets.
D'après ce que je comprends, la fonction de référence est une fonction HP.
Si c'est le cas, vous avez fait tout ce qu'il fallait, sauf une chose : vous ne pouvez pas faire de domaine. Votre désir de combiner les sommets n'a rien à voir avec l'emplacement réel des graphes. De plus, le fait de dominer viole la normalisation de la fonction HP. Que pensez-vous de la probabilité >1 ?
Si vous enlevez la domination et refaites l'image, les parcelles correspondront plus ou moins décemment en largeur. Cependant, l'histogramme sera plus élevé au centre et sur les bords, ce qui est révélateur de deux problèmes principaux : un rendement plus important et, en même temps, des queues lourdes.
Faites une photo comme ça, si vous voulez bien.
PS
Je comprends votre problème à partir du post précédent. Il n'est pas nécessaire de violer la norme HP. Il est préférable de trouver la bonne échelle pour l'histogramme. On le trouve à partir du même rationnement. Vous devez additionner les hauteurs de toutes les barres de l'histogramme, puis diviser chaque barre par cette valeur. Le résultat est que l'histogramme est également normalisé à 1.
Je lis - j'essaie de comprendre sur quoi ils vont se mettre d'accord.
S'il s'agit d'une autre première tentative de mettre une paire de froufrous sur une pieuvre, c'est une chose. Si c'est quelque chose de pratique, j'en suis.
Vous essayez de trouver ce qui se trouve dans la première différence d'une série de citations et qui n'est pas dans la distribution normale ?
Je cherche à savoir ce que contient la première différence des séries de citations, qui n'est pas présente dans la distribution normale.
Et quel est le but de tout cela, quel est l'objectif ? Identifier les zones " anormales " ? Encore une fois, pourquoi ?
(Jusqu'à présent, juste " ?????"))))
Et quel est le but de tout cela, quel est l'objectif ? Identifier les zones " anormales " ? Encore une fois - pourquoi ?
(Jusqu'à présent un seul " ?????"))))
Disons pour sonder quelle loi d'anormalité se manifeste.
Je crois savoir que la fonction de référence est une fonction HP.
Si c'est le cas, vous avez fait tout ce qu'il fallait, sauf une chose : vous ne pouvez pas faire de domaine. Votre désir de combiner les sommets n'a rien à voir avec l'emplacement réel des graphes. De plus, le fait de dominer viole la normalisation de la fonction HP. Que pensez-vous de la probabilité >1 ?
Si vous enlevez la domination et refaites l'image, les parcelles correspondront plus ou moins décemment en largeur. Cependant, l'histogramme sera plus élevé au centre et sur les bords, ce qui est révélateur de deux problèmes principaux : un rendement plus important et, en même temps, des queues lourdes.
Faites une photo comme ça, si vous voulez bien.
PS
Je comprends votre problème à partir du post précédent. Il n'est pas nécessaire de violer la norme HP. Il est préférable de trouver la bonne échelle pour l'histogramme. On le trouve à partir du même rationnement. Vous devez additionner les hauteurs de toutes les barres de l'histogramme, puis diviser chaque barre par cette valeur. Le résultat est que votre histogramme est également normalisé par 1.
Eh bien, ce n'est pas si grave. Vous devez encore le normaliser.
il n'y a pas de rationnement du tout. Seuls les deux sont ajustés au multiplicateur=1.0/Point ; sinon l'inducteur ne voit pas de si petites valeurs.
. En bas à gauche se trouve la densité de la distribution de probabilité, à droite - la même chose en échelle logarithmique.
Si la distribution était normale, nous aurions ici une parabole, ce qui n'est pas le cas, à cause des queues "grasses". En principe, nous devrions ajuster une gaussienne des moindres carrés ici, puis tout se mettra en place. Je vais devoir ajouter une formule pour l'ajustement optimal...
Sergei, qu'en est-il du double logarithme ? J'y pense depuis un moment maintenant...
Je ne peux toujours pas le tester par pudeur :)
Sergei, qu'en est-il du double logarithme ? J'y pense depuis un certain temps maintenant...
Je suis trop modeste pour le vérifier :)
Il s'avère que oui :
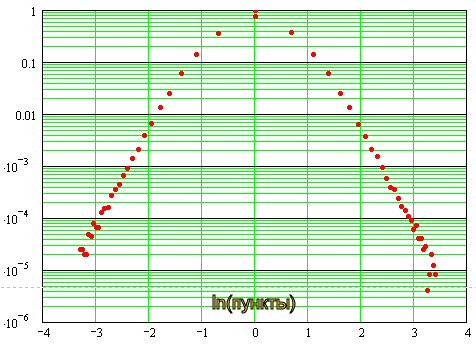
On peut voir qu'au voisinage de zéro, la distribution est proche de la normale, puis elle devient asymptotique sous forme de lignes droites, ce qui dans l'échelle logarithmique double indique la nature exponentielle de la distribution des "queues". En d'autres termes, sur leur "lourdeur".