Discusión sobre el artículo "Redes neuronales de propagación inversa del error en matrices MQL5"
¡Más gracias a Stanislav! Por fin se ha escrito un artículo sobre redes neuronales utilizando matrices nativas....
Por cierto. Hoy mismo me he enterado de que hay un nuevo bloque en la Documentación sobre ML.

- www.mql5.com
Gracias al autor por el detallado artículo y por las honestas conclusiones.
"Esas cosas que se me olvidaron, ni siquiera saben todavía" - así es como el autor podría responder a tales críticas.
"Esas cosas que he olvidado tú aún no las sabes" es como podría responder un autor a esas críticas.
Hay dos aspectos y es importante:
1. Ejecución, parte técnica, universalidad, alabada incluso por programadores maduros. Y aquí, efectivamente, no puedo ni quiero ni he intentado criticar el código. Hablo de otra cosa:
2. Pruebas. El autor señaló que todos sus modelos funcionan. De hecho, cuando pulsas el botón "Start" en el probador, aparece una imagen aleatoria para las 2 semanas siguientes, y de 10 pulsaciones 5 - ciruela, 5 - ganancia. Naturalmente, si usted pone tal cosa en el real - 50/50 viabilidad de su depósito. Este no es el caso. En mis preguntas acerca de lo que es y cómo solucionarlo, el autor dijo que debería ser así, es el principio del modelo. Bueno, aquí me caí simplemente, sin palabras.
Dos meses traté de iniciar estas redes, que no quería trabajar en NVIDIA, gracias Aleksey Vyazmikin, reescribió el código del autor y todo funcionaba en 3080. Y al final - modelos inoperables. Es doblemente ofensivo.
Pero si te ofendí/ofendí, me disculpo, no tenía tal propósito.
matrix temp; if(!outputs[n].Derivative(temp, of))
En la retropropagación ,las funciones derivadas esperan recibir x y no activación de x (a no ser que lo hayan cambiado recientemente para las funciones de activación a las que se aplica)
Aquí hay un ejemplo :
#property version "1.00" int OnInit() { //--- double values[]; matrix vValues; int total=20; double start=-1.0; double step=0.1; ArrayResize(values,total,0); vValues.Init(20,1); for(int i=0;i<total;i++){ values[i]=sigmoid(start); vValues[i][0]=start; start+=step; } matrix activations; vValues.Activation(activations,AF_SIGMOID); //imprimir sigmoide for(int i=0;i<total;i++){ Print("sigmoidDV("+values[i]+")sigmoidVV("+activations[i][0]+")"); } //derivados matrix derivatives; activations.Derivative(derivatives,AF_SIGMOID); for(int i=0;i<total;i++){ values[i]=sigmoid_derivative(values[i]); Print("dDV("+values[i]+")dVV("+derivatives[i][0]+")"); } //--- return(INIT_SUCCEEDED); } double sigmoid(double of){ return((1.0/(1.0+MathExp((-1.0*of))))); } double sigmoid_derivative(double output){ return(output*(1-output)); }
También hay funciones de activación para las que puede enviar más entradas, tanto en la activación y la derivación, como la elu, por ejemplo
Derivative(output,AF_ELU,alpha); Activation(output,AF_ELU,alpha);
En la retropropagación ,las funciones derivadas esperan recibir x y no activación de x (a no ser que lo hayan cambiado recientemente para las funciones de activación a las que se aplica)
No estoy seguro de lo que quieres decir. Hay fórmulas en el artículo, que se convierten en las líneas de código fuente exactamente. Las salidas se obtienen con la llamada de activación durante la etapa de avance, y luego tomamos sus derivados en backpropagation. Probablemente se perdió que la indexación de las matrices de salida en las clases son con +1 sesgo a la indexación de los pesos de capa.
No estoy seguro de lo que quieres decir. Hay fórmulas en el artículo, que se convierten en las líneas de código fuente exactamente. Las salidas se obtienen con la llamada de activación durante la etapa de feedforward, y luego tomamos sus derivados en backpropagation. Probablemente se perdió que la indexación de las matrices de salida en las clases son con +1 sesgo a la indexación de los pesos de capa.
Sí, la matriz temp se multiplica por los pesos y luego output[] contiene los valores de activación .
En la parte posterior prop usted está tomando las derivaciones de estos valores de activación, mientras que la función MatrixVector derivativa espera que usted envíe los valores temp

Esta es la diferencia en las derivadas
Permítanme simplificarlo:
#property version "1.00" int OnInit() { //--- //supongamos que x es la salida de la capa anterior (*) pesos de un nodo //el valor que va en la activación . double x=3; //obtenemos la sigmoide mediante la fórmula siguiente double activation_of_x=sigmoid(x); //y para la derivada hacemos double derivative_of_activation_of_x=sigmoid_derivative(activation_of_x); //hacemos esto con matrixvector vector vX; vX.Init(1); vX[0]=3; //creamos un vector de activaciones vector vActivation_of_x; vX.Activation(vActivation_of_x,AF_SIGMOID); //creamos un vector para las derivaciones vector vDerivative_of_activation_of_x,vDerivative_of_x; vActivation_of_x.Derivative(vDerivative_of_activation_of_x,AF_SIGMOID); vX.Derivative(vDerivative_of_x,AF_SIGMOID); Print("NormalActivation("+activation_of_x+")"); Print("vector Activation("+vActivation_of_x[0]+")"); Print("NormalDerivative("+derivative_of_activation_of_x+")"); Print("vector Derivative Of Activation Of X ("+vDerivative_of_activation_of_x[0]+")"); Print("vector Derivative Of X ("+vDerivative_of_x[0]+")"); //estás haciendo la derivada vectorial de la activación de x que devuelve el valor incorrecto //vectorMatrix espera que envíes x no la activación(x) //--- return(INIT_SUCCEEDED); } double sigmoid(double of){ return((1.0/(1.0+MathExp((-1.0*of))))); } double sigmoid_derivative(double output){ return(output*(1-output)); }
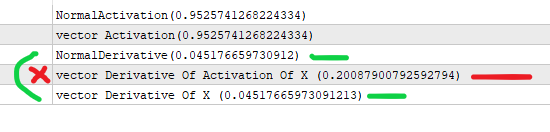
Entiendo lo que quieres decir. Efectivamente, la derivada sigmoidea se formula a través de 'y', es decir a través del valor sigmoide en el punto x, es decir y(x): y'(x) = y(x)*(1-y(x)). Esto es exactamente como los códigos en el artículo implementado.
Tu script de prueba calcula la "derivada" tomando x como entrada, no y, de ahí que los valores sean diferentes.
Entiendo tu punto de vista. Efectivamente, la derivada sigmoidea se formula a través de 'y', es decir, a través del valor sigmoide en el punto x, o sea y(x): y'(x) = y(x)*(1-y(x)). Así es exactamente como se implementan los códigos del artículo.
Tu script de prueba calcula la "derivada" tomando x como entrada, no y, de ahí que los valores sean diferentes.
Sí, pero los valores de activación se pasan a la función de derivación mientras que ésta espera los valores de preactivación. Eso es lo que estoy diciendo.
Y te perdiste el punto, el valor correcto es con la x como entrada (el valor correcto de acuerdo a la propia función de mq).
No estas almacenando el output_of_previous * weights en alguna parte (creo) , que es lo que debe ser enviado en las funciones de derivación (de acuerdo con la propia función de mq de nuevo , voy a hacer hincapié en eso)
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Redes neuronales de propagación inversa del error en matrices MQL5:
El artículo describe la teoría y la práctica de la aplicación del algoritmo de propagación inversa del error en MQL5 con la ayuda de matrices. Asimismo, incluye clases y ejemplos preparados del script, el indicador y el asesor.
Como veremos a continuación, MQL5 ofrece un amplio conjunto de funciones de activación integradas. La elección de una función específica debe realizarse según las características específicas del problema (regresión, clasificación). Como regla general, resulta posible seleccionar varias funciones para cualquier tarea y luego encontrar experimentalmente la óptima.
Funciones de activación populares
Las funciones de activación pueden tener diferentes rangos de valores: limitados o ilimitados. Concretamente, el sigmoide (3) asigna los datos al rango [0,+1] (mejor para problemas de clasificación), mientras que la tangente hiperbólica asigna los datos al rango [-1,+1] (mejor para problemas de regresión y pronóstico).
Autor: Stanislav Korotky