Is there a pattern to the chaos? Let's try to find it! Machine learning on the example of a specific sample. - page 18
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
Random is fixed :) It seems that this seed is calculated in a tricky way, i.e. all predictors allowed for model building are probably involved, and changing their number also changes the selection result.
The starting seed is fixed. And then a new number appears with each call of the HSC. That's why at different number of predictors and the number of DSTs will not fall on the same predictor as at the full number of predictors.
Why is this fitting, or rather what do you see it in? I tend to think that the test sample differs from exam more than exam from train, i.e. there are different probability distributions of predictors.
Well, you take the best exam variants, hoping that they will be good on the test. You select the predictors based on the best exam. But they are the best only for the exam.
What is the "err_" metric?
err_ oob - error on OOB (you have it exam), err_trn - error on train. By the formula we will get some error common for both sample sites.
By the way, in the discussion we have swapped test and exam. At first we planned intermediate checks on test and final checks on exam. But the context makes it clear what is what, even though they changed the names.
The starting number is fixed. And then a new number appears with each call of the DST. Therefore, at different number of predictors and numbers of DSTs will not fall on the same predictor as at full number of predictors.
Nah, the variants are reproduced there if the predictors used for training are left in the same number.
Well, you take the best exam variants, hoping that they will be good on the test. Predictors are selected by the best exam. But they are the best only for the exam.
It so happened that this variant was the most balanced - with a decent profit on test and exam. Below in the picture is the initially selected model - "Was" and the best balanced model after 10k training - "Became". In general, the result is better, and fewer predictors are used, so noise is eliminated. And here the question is how to avoid this noise before training.
And so the logic is such that training stops on the test, so there should be more likely to be a positive result there than in the sample that does not participate in training at all, so the emphasis is placed on the latter.
err_ oob - error on OOB (you have it exam), err_trn - error on trn. By the formula we will get some error common for both sample sites.
I mean, I don't know how "err" is counted - is it Accuracy? And why exam and not test, because in the basic approach exam we will not know.
By the way, we have switched test and exam in the discussion. At first it was planned to have intermediate tests on test and final tests on exam. But by context it is clear what is what, although they changed the names.
I didn't change anything (maybe I've described myself somewhere?) - it's just the way it is - on train - training, test - control of stopping training, and exam - section not involved in any kind of training.
I am just evaluating the effectiveness of the approach by the average of all models, including the average profit - it is more likely to be obtained than the edges with a good result.
And then there's the question of how to avoid that noise before you start training.
Apparently you can't. This is the task to filter out the noise and learn from the correct data.
I mean that I don't know how "err" is considered - is it Accuracy?
It's a way to get a combined/summarised error on a traine with a test. Any kind of error can be summed up. And (1-accuracy) and RMS and AvgRel and AvgCE etc.
I haven't changed anything(maybe I described myself somewhere?) - that's the way it is - on train - training, test - control of stopping training, and exam - section not involved in any kind of training.
It seemed to me from the pictures that exam means test
For example here.
And in the table above exam results are better than test. It is certainly possible, but it should be the other way round.
Apparently not. That's the challenge to cut through the noise and learn from the right data.
Nah, there has to be a way, otherwise it's all useless/random.
This is a way to get the combined/summarised error on a traine with a test. Any kind of error can be summed. And (1-accuracy) and RMS and AvgRel and AvgCE etc.
Got it, well that doesn't work on my data - there should be some correlation at least :)
It seemed to me from the pictures that exam meant test
For example here
And in the table above the exam results are better than the test.
Yes, it turns out that the exam is more likely to earn more money for modellers - I don't fully understand the situation myself.
Unfortunately, now I noticed that at some point I mixed up the total sample (rows) and now the examples from 2022 are in the train :(.
I will redo everything - I think I will have the result in a couple of weeks - let's see if the overall picture changes.
Unfortunately, now I noticed that at some point I mixed up the total sample (rows), and now the train includes examples from 2022 :(
I'll redo it - I think I'll have the result in a couple of weeks - see if the overall picture changes.
It doesn't make any difference whether it was assessed by exam or test. The main thing is that the assessment site was not used in either the training or the initial assessment.
2 weeks. I'm amazed at your stamina. I get annoyed with 3 hours of calculations too..... And have spent a total of 5 years on MO already, about the same as you.
In short, we'll start earning something in retirement )))) Maybe.
Unfortunately, I've now noticed that at some point I mixed up the overall sample (rows) and now the train is populated with examples from 2022 :(
I have everything glued into 1 sequential array. And then I separate the right amount from it. That way nothing gets mixed up.
It doesn't make any difference whether it was assessed by exam or test. The main thing is that the assessment site was not used in either the training or the initial assessment.
I'm wondering whether it's better to do the final training like Maxim - taking a prehistoric sample for control, or whether it's better to take the whole available sample and limit the number of trees, as on average in the best models.
2 weeks... I'm amazed at your stamina. I find 3 hours of calculations annoying too..... And have spent a total of 5 years on MO already, about the same as you.
Of course, you always want to get results faster. I try to load the hardware so that my calculations do not interfere with other things - I often use not the main working computer. In parallel I can implement other ideas in code - I come up with ideas faster than I have time to check them in code.
In short, we will start earning something in retirement )))) Maybe.
I agree - the prospect is sad. If I didn't see progress in my research, albeit slow, I'd probably have finished the work by now.
I have everything glued into 1 sequential array. And then from that array I separate out the right amount. That way nothing gets mixed up.
Yes, I converted the sample to a binary file, and in the script I put a checkbox by accident, apparently, responsible for mixing the sample - so it's not a problem, and CatBoost requires 3 separate samples - they did not make the selection on the range of rows, although they have a built-in cross validation.
I'm also wondering whether it's better to do the final training like Maxim - taking a prehistoric sample for control, or whether it's better to take the whole available sample and limit the number of trees, as on average in the best models.
For me, pre-training and tests are an opportunity to select on average the best hyperparameters (number of trees, etc.) and predictors. And even without a test you can train on them on the traine and immediately go into trading.
The idea of prehistoric sampling will work if the patterns do not change, maybe so. But there is a risk that it will change. So I prefer not to take risks and test on future sampling.
Another question is how long ago was this prehistoric sample: six months ago or 15 years ago? Six months ago might work, but the market 15 years ago is not the same as it is now. But it's not certain. Maybe there are patterns that have been working for decades.I will describe the results obtained using the same algorithm I described here, but with the sample unmixed, i.e. remaining in chronological order.
The only thing I have changed is that now the training of 10000 models was performed not on the whole sample with excluded predictors taking part in it, but on a re-formed sample in which the columns with excluded predictors were removed, which accelerated the training process (apparently pumping a large file takes a lot of time). Due to these changes I was able to consistently perform 6 steps of predictor screening.
Figure 1: Histogram of profit on sample exam after training 100 models on all predictors of the sample.
Figure 2: Histogram of profit on exam sample after training 10k models on selected sample predictors - step 1.
Figure3. Histogram of profit on exam sample after training 10k models on selected sample predictors - step 2.
Figure 4: Histogram of profits for exam sample after training 10k models on selected sample predictors - step 3.
Figure 5: Histogram of profits for exam sample after training 10k models on selected sample predictors - step 4.
Figure 6: Profit histogram for exam sample after training 10k models on selected sample predictors - step 5.
Figure 7: Profit histogram for exam sample after training 10k models on selected sample predictors - step 6.
Figure 8. Table with the characteristics of the models that were selected to form subsequent samples with a decreasing number of predictors (features).
Let's consider the model with the following characteristics obtained at the 6th step of predictor selection.
Figure 9: Model characteristics.
Figure 10. Visualisation of the model over the sample exam as a distribution over the probability of classification - x-axis - probabilities obtained from the model, and y - percentage of all samples.
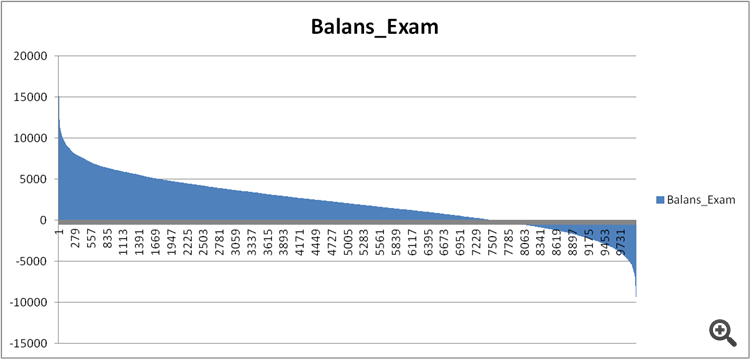
Figure 11. Balance of the model on the exam sample.
Now let us compare the predictors in the reasonably good and extremely bad models obtained at step 6 of predictor selection.
Figure 12. Comparison of the characteristics of the models.
Can we now see which predictors have such a bad effect on the financial result and spoil the training?
Figure 13. Weighting of predictors in the two models.
Figure 13 shows that almost all of the available predictors are used, except for one, but I doubt that this is the root of the problem. So it is not so much a matter of usage, but rather the sequence of usage in building the model?
I made a comparison of two tables, assigning an ordinal number of significance instead of an index, and saw how differently this significance is ranked in the models.
Figure 14: Table comparing the significance (use) of predictors in the two models.
Well and histogram for better visualisation - deviations in minus means that the predictor of the second (unprofitable) model was used later, and plus - earlier.
Figure 15. Deviations of significance of predictors in the models.
It can be seen that there are strong deviations, maybe this is the case, but how to find out/prove it? Perhaps some complex approach of comparing the models with the benchmark is needed - any ideas?
Is there some kind of confounding index to describe the overall bias, perhaps taking into account the significance of the predictors for the first model - i.e. with a decreasing coefficient?
What conclusions can be drawn?
My guess is this:
1. The results were much better in the past sample, I assume that this is due to the information that "leaked" about events from the future by mixing the chronology of the sample. Whether the models will be more stable with a jumbled sample or a normal sample is the question.
2. It is necessary to build a structure of significance of predictors for their further application in models, i.e. besides numbers it is necessary to lay down logic, otherwise the scatter of results of models is too great even on a small number of predictors.