文章 "在任何市场中获得优势(第三部分):Visa消费指数"
谢谢你,加穆
好文章,感谢分享
再次感谢加穆。写得一如既往地好。这是一个关于如何可视化、扩展、测试、检查过度拟合、实施数据反馈、预测和实施数据集交易系统的优秀注释模板。 非常精彩,非常感谢
linfo2 #:
再次感谢加穆。写得一如既往地好。这是一个关于如何可视化、扩展、测试、检查过度拟合、实施数据反馈、预测和实施数据集交易系统的优秀评论模板。 非常精彩,非常感谢
感谢尼尔的反馈,很高兴听到你的赞誉。再次感谢加穆。写得一如既往地好。这是一个关于如何可视化、扩展、测试、检查过度拟合、实施数据反馈、预测和实施数据集交易系统的优秀评论模板。 非常精彩,非常感谢
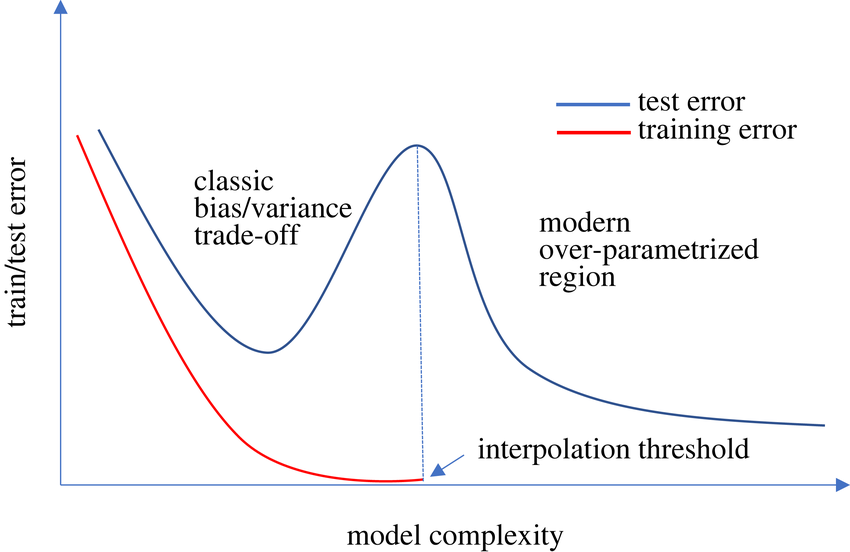
疯狂的是,每天都有新的研究质疑我们自以为知道的一切。我最近了解到了双重血统现象。
如果这个理论是真的,那么就不存在过度拟合。根据这一现象,如果我们继续在同一训练集上长时间训练更大的深度神经网络,验证误差就会持续下降,越来越低,我的黑哥们。
我下面附上的图片直观地表达了这一现象。问题在于,长时间训练一个如此庞大的模型成本很高,而且如果数据有噪声,这种现象就会持续更长时间。我还无法在我的电脑上重现这些结果,但这篇论文已经在网上传开了
{kind=link}
新文章 在任何市场中获得优势(第三部分):Visa消费指数已发布:
VISA是一家美国跨国支付服务公司。它成立于1958年,如今该公司运营着世界上最大的交易处理网络之一。VISA非常适合成为可靠的备选数据来源,因为它们几乎渗透了发达世界的每一个市场。此外,圣路易斯联邦储备银行也从VISA收集部分宏观经济数据。
在本次讨论中,我们将分析VISA消费动力指数(SMI)。该指数是消费者支出行为的宏观经济指标。这些数据由VISA使用其专有网络和VISA借记卡及信用卡品牌进行汇总。所有数据都经过匿名处理,主要收集于美国境内。随着VISA继续从不同的市场汇总数据,这一指数最终可能会成为全球消费者行为的基准。
我们使用圣路易斯联邦储备银行提供的API服务来检索VISA SMI数据集。圣路易斯联邦储备经济数据库(FRED)API使我们能够访问来自世界各地的数十万种不同的经济时间序列数据。
作者:Gamuchirai Zororo Ndawana