关于MT5代码分析器
回溯测试运行 在。
2021.07.10 08:00: 37.101 Core 01 EURUSD, H1: 230861 ticks, 998 bars generated.测试在0: 03: 09.367通过(包括预处理刻度0: 00: 00.515)。
我添加了代码,使用GetMicrosecondCount()测量SymbolInfoTick()的执行时间。
ulong start= GetMicrosecondCount (); //--- Get tick information if (! SymbolInfoTick (symbol,tick)) return ( false ); BENCH += GetMicrosecondCount ()-start;
结果。
2021.07.10 08:00: 37.101 Core 01 2021.05.30 23:59:59 Total = 1209572 Executed = 836973 in661874 microseconds
因此,SymbolInfoTick()在3分9秒的历史数据上总共花了661毫秒。然而,分析器显示,它使用了74.71%的测量值。这有多准确或有用,我不明白。
另一个奇怪数据的例子。

根据全局统计,SymbolInfoTick()在调用堆栈中出现了209次。但在代码里面,它说的是210。良好的精确度。
根据全局统计,SymbolInfoTick 被采样了209次(占所有采样的0.83%)。好的。现在代码数据说它达到了1次(现在是1.49%,所以如果你看另一个总数,它是什么?)一旦计算出来,1等于1.49%意味着总数(100%)是67。因此,1.49%指的是OnTimer(),它是本例中的主要函数。但是,在全球的统计中,那里怎么会有1个,而有209个?
即使这不是一个错误,它又怎么能迅速发挥作用呢(在我看来,一个剖析器应该是这样的)?
另一个
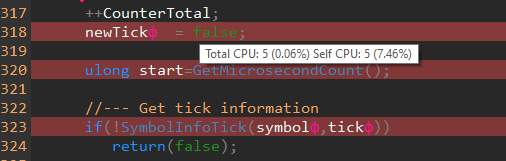
这是在SymbolInfoTick()之上的一行代码,如前所示。因此,像newTick=false这样的赋值被 "选择 "了5次!这意味着什么?调用SymbolInfoTick()后又是5次( 1-1.49%)?玩笑归玩笑 ?
问问自己这是什么,有什么区别。
- 基于采样的剖析(就像我们现在所拥有的,类似于Visual Studio C++和其他的)。
- 基于代码仪表的剖析(就像我们之前的一样)
差异是显而易见的。
问题是在实践中使用它时,数据不一致且有错误。
另一个奇怪数据的例子。
根据全局统计,SymbolInfoTick()在调用堆栈中出现了209次。但在代码里面,它说的是210。良好的精确度。
根据全局统计,SymbolInfoTick 被采样了209次(占所有采样的0.83%)。好的。现在代码数据说它达到了1次(现在是1.49%,所以如果你看另一个总数,它是什么?)一旦计算出来,1等于1.49%意味着总数(100%)是67。因此,1.49%指的是OnTimer(),它是本例中的主要函数。但是,在全球的统计中,那里怎么会有1个,而有209个?
即使这不是一个错误,它又怎么能迅速发挥作用(在我看来,剖析器应该是这样的)?
截图显示的是调用字符串的统计信息,而不是SymbolInfoTick函数。
总的来说,给定的字符串被测量了210次,一旦字符串上有一个确切的 "停止",在调用SymbolInfoTick之前或之后,以及209次作为SymbolInfoTick的返回字符串。
另一个
这是在SymbolInfoTick()之上的一行代码,如前所示。因此,像newTick=false这样的赋值被 "选择 "了5次!这意味着什么?调用SymbolInfoTick()后又是5次( 1-1.49%)?玩笑归玩笑 ?
我不太明白写的是什么。
阅读这个截图:字符串被 "停止 "了5次,占总负载的0.06%,对于字符串所属的函数代码来说,这是7.46%。
自身CPU "计数器显示字符串代码对字符串所在函数的速度的影响。
重要的是,在字符串中调用的函数的时间不被这个计数器所计算,也许这是不对的,让我们想想。
总CPU "计数器显示了字符串代码对整个程序的影响,这个计数器考虑到了字符串中调用的函数。
我不太明白它说什么。
你应该这样理解这张截图:该行被 "停止 "了5次,占总负载的0.06%,该行所属的函数代码占7.46%。
是的,我知道。(抱歉我之前的语气,我有点生气了)。
问题是:
newTickф = false ; // Total CPU : 5 (0.06%) Self CPU : 5 (7.46%)
到目前为止
if (! SymbolInfoTick (symbolф,tickф)) // Total CPU : 210 (2.57%) Self CPU : 1 (1.49%)
一般的CPU是好的。
但是对于Self CPU来说,"newTick = false "等于5,而像SymbolInfoTick()这样的函数调用只等于1,这怎么可能呢?这对我来说是没有意义的。
我已经开始使用一个新的分析器。在这一节中,我们可以集中介绍如何正确使用它的信息。
首先,我有一些关于剖析器 返回的数据的奇怪的问题。
在历史数据上运行的EA中使用的剖析报告。
2021.07.08 15:43:06.269 MQL5 profiler 139098 total measurements, 0/0 errors, 320 mb of stack memory analyzed (92848/1073741824)
2021.07.08 15:43:06.269 MQL5 profiler 982065 total function frames found (279627 mql5 code, 122460 built-in,571051 other, 8927 system)
结果(功能由调用)。
Q1.报告说有139098个测量值,但OnTick()总CPU是150026,这怎么可能呢?(但CopyHistoryData 80087为57.58%的正确率意味着100%=139098)。
Q2.报告说有571,051项其他 "职能"。如果这些功能不是mql、嵌入式或系统功能,那么它们是什么?
Q3.CopyHistoryData显示80087总CPU,3个报告的函数调用(CopyHigh,CopyLow,CopyTime)有不同的总CPU,ok。 然而,这些函数的本地CPU是相同的,等于总CPU(调用栈)。这似乎是不正确的,因为在80087(堆栈)的CopyHistoryData中,3个函数的总和是62,161(44286+9448+8427),怎么可能在62,161个调用中检测到这3个函数的8087个暂停?不可能,唯一的解释是,这个数字对CopyHistoryData来说是全局的,因此没有用。我错过了什么吗?