Реализация машины с памятью
В качестве измерений(координат) векторов я взял отношения мувингов, предположив что отношения стационарны и раз расклассифицировав вектора(сделки) можно будет использовать такую классификацию и на форварде. Но не всё так просто :) .
Сколько бралось мувингов и какой коэффициент корреляции между ними ещё считался приемлимым (выбеливание входов)?
В каком смысле "отношения мувингов" стационарны. В чём (по какому параметру) констатируется стационарность?
Ага! Кажется я начал что-то понимать. Ваше изобретение - "отношение мувингов", есть в пределе ничто иное, как банальная производная от того же мувинга с единичным смещением. Вот рис.
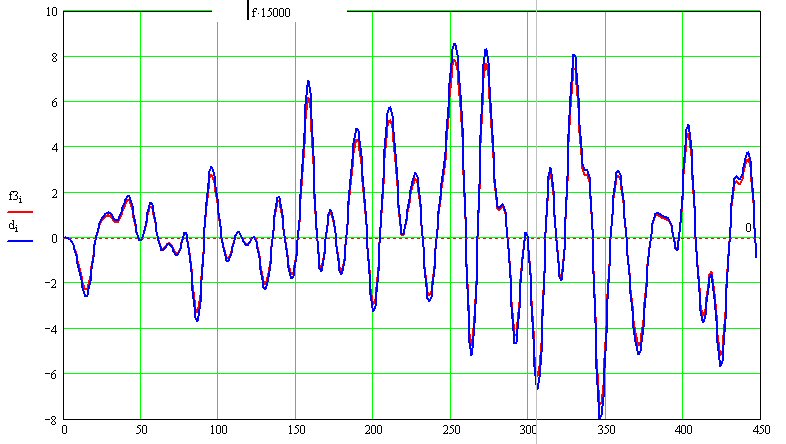
На нём синей линией показана производная от мувинга, а красной - отношение мувингов при разности периодов этих мувингов равной 1 (например, 19 и 20). Видно, что это одно и то же. Таким образом, вы в своей работе исследовали возможность применения первой производной сглаженной кривой ценового ряда как инструмент предсказания.
Вот только, это для ценовых рядов не работает в принципе и связано это с самой природой этого типа ВР - они не являются гладкими. Т.е. ничего, кроме отрицательного результата (хотя, как судить) у Вас и не должно было получится. Можно, конечно, говорить, что Вы работали с мувингами которые отличаются по своим периодам более чем на 1, но это всё от лукавого! Не суть. Короче, Вы использовали Классификатор для поиска закономерностей там, где их нет в принципе.
Два года назад я написал советника на основе k-ближайших соседей. При оптимизации получались неплохие результаты, но всё сливалось при out-of-sample тестировании. Потом соорудил эксперта подсчитывающего вероятность правильного предсказания направления движения цены методом k-ближайших соседей по всей истории. Оказалось точно 50% даже не смотря на то что оптимизатор давал хорошую прибыль. Как я не крутил входные параметры, выше 50% не удалось получить. Заключил что при оптимизации на истории можно подогнать этот метод чтобы выбирать правильные точки входа опять же на истории, но это всё случайно или с большим прогибом и не даёт гарантии что в будущем эксперт останется счастливчиком. В итоге, идею забросил по нескольким причинам:
1. Нужна длинная история для нахождения приемлемых соседей. Тут возникает теоретический вопрос. Почему мы уверены что при повторении ближайщего соседа будущее тоже повторится? Тут можно филосовствовать. Например, дескать те трейдеры торгующие по распознанию фигур в движениях цен распознают соседа и будут торговать в том же направлении, которое произошло в прошлом. Тогда возникает другой вопрос. Какой длинны память у этих трейдеров? Если например ближайщий сосед случился в 2001 году, вы думаете что его кто-то помнит и он имеет влияние на направление цены в 2009 году?
2. Нужны большие компьютерные ресурсы для поиска ближайщих соседов, подсчёта их расстояния от текущего вектора и вычисленя прогноза. Наибольшие ресурсы будут расходоваться если производить все эти вычисления бри каждом новом баре. Возникает такой вопрос. Какой длинны ближайщий сосед? Маленькая длинна (например, 3 бара) не даст соседу достаточной уникальности. Очень длинных соседов будет очень сложно найти. Существует также другая проблема с длинной соседа. Идеально, мы хотели бы выбрать соседа такой длинны чтобы хорошо описать определённую фигуру цены, например head and shoulders, треугольник и т.п. Но протяжённость этих фигур разная по истории. Поэтому длинна должна как-то адаптироваться: либо задавать разные длинны соседей при их поиске (громадные компьютерные ресурсы) либо найти метод чтобы автоматически находить правильную длинну соседа (фигуры). Я пробовал зигзагом находить фракталы и использовать только координаты этих фракталов для нахождения соседей. Движение цены между фракталами это шум. Например, head and shoulders можно задать семью фракталами. Тут возникает другая проблема. Как правильно определить фракталы? Существует множество методов. При вариации входных данных в эти методы, можно получить разное количество фракталов за один и тот ж промежуток времени. Короче, использование фракталов вместо цен не привело к увеличению вероятности предсказания будущего движения цен. Хотя мне кажется что это перспективное направлемие, по которому стоит поработать.
Перспективный метод таков:
- находим фракталы (swing points или волны) в движении цены
- классифицируем все возможные фигуры: head and shoulders, треугольники, флаги и т.п. Каждая фигура имеет свою определённую длину и условия на соотношения highs и lows. Например, h&s имеет длинну 7, треугольник, флаг - 5, ...
- прогоняем каждую фигуру по истории и подсчитываем вероятность направления и размаха движения цены.
- создаём базу фигур-шаблонов с их вероятностями.
- находим ближайщего соседа в этой базе
- принимаем решение о торговле
Сколько бралось мувингов и какой коэффициент корреляции между ними ещё считался приемлимым (выбеливание входов)?
В каком смысле "отношения мувингов" стационарны. В чём (по какому параметру) констатируется стационарность?
Ага! Кажется я начал что-то понимать. Ваше изобретение - "отношение мувингов", есть в пределе ничто иное, как банальная производная от того же мувинга с единичным смещением. Вот рис.
На нём синей линией показана производная от мувинга, а красной - отношение мувингов при разности периодов этих мувингов равной 1 (например, 19 и 20). Видно, что это одно и то же. Таким образом, вы в своей работе исследовали возможность применения первой производной сглаженной кривой ценового ряда как инструмент предсказания.
Вот только, это для ценовых рядов не работает в принципе и связано это с самой природой этого типа ВР - они не являются гладкими. Т.е. ничего, кроме отрицательного результата (хотя, как судить) у Вас и не должно было получится. Можно, конечно, говорить, что Вы работали с мувингами которые отличаются по своим периодам более чем на 1, но это всё от лукавого! Не суть. Короче, Вы использовали Классификатор для поиска закономерностей там, где их нет в принципе.
В данном примере нет никаких моих исследований, это просто пример, акцент был сделан на классификатор, который может быть принесёт больше пользы чем мне.
С чего Вы взяли что отношения мувингов - моё изобретение.
Отношения взяты например 8 к 144 мувингу для определения отклонения...
Стационарный - ряд не меняет своей функции распределения с течением времени.
Два года назад я написал советника на основе k-ближайших соседей. При оптимизации получались неплохие результаты, но всё сливалось при out-of-sample тестировании. Потом соорудил эксперта подсчитывающего вероятность правильного предсказания направления движения цены методом k-ближайших соседей по всей истории. Оказалось точно 50% даже не смотря на то что оптимизатор давал хорошую прибыль. Как я не крутил входные параметры, выше 50% не удалось получить. Заключил что при оптимизации на истории можно подогнать этот метод чтобы выбирать правильные точки входа опять же на истории, но это всё случайно или с большим прогибом и не даёт гарантии что в будущем эксперт останется счастливчиком. В итоге, идею забросил по нескольким причинам:
1. Нужна длинная история для нахождения приемлемых соседей. Тут возникает теоретический вопрос. Почему мы уверены что при повторении ближайщего соседа будущее тоже повторится? Тут можно филосовствовать. Например, дескать те трейдеры торгующие по распознанию фигур в движениях цен распознают соседа и будут торговать в том же направлении, которое произошло в прошлом. Тогда возникает другой вопрос. Какой длинны память у этих трейдеров? Если например ближайщий сосед случился в 2001 году, вы думаете что его кто-то помнит и он имеет влияние на направление цены в 2009 году?
2. Нужны большие компьютерные ресурсы для поиска ближайщих соседов, подсчёта их расстояния от текущего вектора и вычисленя прогноза. Наибольшие ресурсы будут расходоваться если производить все эти вычисления бри каждом новом баре. Возникает такой вопрос. Какой длинны ближайщий сосед? Маленькая длинна (например, 3 бара) не даст соседу достаточной уникальности. Очень длинных соседов будет очень сложно найти. Существует также другая проблема с длинной соседа. Идеально, мы хотели бы выбрать соседа такой длинны чтобы хорошо описать определённую фигуру цены, например head and shoulders, треугольник и т.п. Но протяжённость этих фигур разная по истории. Поэтому длинна должна как-то адаптироваться: либо задавать разные длинны соседей при их поиске (громадные компьютерные ресурсы) либо найти метод чтобы автоматически находить правильную длинну соседа (фигуры). Я пробовал зигзагом находить фракталы и использовать только координаты этих фракталов для нахождения соседей. Движение цены между фракталами это шум. Например, head and shoulders можно задать семью фракталами. Тут возникает другая проблема. Как правильно определить фракталы? Существует множество методов. При вариации входных данных в эти методы, можно получить разное количество фракталов за один и тот ж промежуток времени. Короче, использование фракталов вместо цен не привело к увеличению вероятности предсказания будущего движения цен. Хотя мне кажется что это перспективное направлемие, по которому стоит поработать.
Перспективный метод таков:
- находим фракталы (swing points или волны) в движении цены
- классифицируем все возможные фигуры: head and shoulders, треугольники, флаги и т.п. Каждая фигура имеет свою определённую длину и условия на соотношения highs и lows. Например, h&s имеет длинну 7, треугольник, флаг - 5, ...
- прогоняем каждую фигуру по истории и подсчитываем вероятность направления и размаха движения цены.
- создаём базу фигур-шаблонов с их вероятностями.
- находим ближайщего соседа в этой базе
- принимаем решение о торговле
Вы описали довольно сложный и трудоёмкий способ использовать данный классификатор, можно кстати и по другому, но не важно.
Классификатор можно использовать под любую стратегию, важно какие данные записываются в базу.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Реализация машины с памятью на основе k-ближайших соседей. Данный подход не дал мне желаемого результата, возможно из-за того что мало времени с ним возился (что скорее всего), возможно из-за не хватки каких-то знаний. В общем я решил выложить подход для обсуждения и может быть это даст свои плоды(Очень на это надеюсь).
Функция Euclidean_Metric – представляет собой классификатор. Функция по имеющейся базе векторов описывающих либо сделки, либо ситуации на рынке определяет принадлежность входного вектора к какой-либо группе векторов из базы. Вектора на группы разделяете Вы, в моём примере просто: Если сделка закрылась с положительным результатом то это класс 1, если с отрицательным результатом то класс 0. Поиск ближайших соседей многомерного вектора производиться при помощи евклидова расстояния. Затем просчитываем сколько из этих k-векторов принадлежат к классу 1, после чего делим это число на общее количество соседей(т.е. на k) и получаем вероятность принадлежности данного вектора к классу 1. Из-за “плохих” выбранных координат векторов мы не можем доверять полностью( просто выше 0,5 или ниже 0,5) классификации, поэтому дополнительно я ввёл пороговое значение, т.е. если вероятность прибыльности будущей сделки выше, допустим, 0,7 то входим в рынок. В качестве измерений(координат) векторов я взял отношения мувингов, предположив что отношения стационарны и раз расклассифицировав вектора(сделки) можно будет использовать такую классификацию и на форварде. Но не всё так просто :) . Почему именно k-ближайших соседей? Просто потому что если взять 1-го ближайшего соседа то это может оказаться аномальным выбросом случайной величины который и будет выбран для классификации, не учитывая что рядом скопление противоположных(по группе) векторов. Подробное описание Хайкин С. «Нейронные сети: полный курс»(Методы Обучения).
Проблемы классификатора 2:
1) Найти стационарные данные описывающие рыночные ситуации(или будущие сделки) с требуемой точностью или с требуемым уровнем правильной классификации.
2) Большой объём мат.операций следствие – долго считается…(кстати говоря в сравнении с PNN немного меньше)
Проще говоря проблемы практически те же что и у обычных ТС. Единственное, классификатор может формализовать условия которые трейдер не увидит, но например на интуитивном уровне будет чувствовать что от каких-то значений индикатора зависит стоит ли входить сейчас в рынок.
Теперь конкретно о реализации.
Base - true пишем файл с базой векторов, false торгуем с классификацией…
buy_threshold=0.6 порог на все Buy позиции
sell_threshold=0.6 аналогично на sell
inverse_position_open_?=true; А вот это интересный момент, Если у нас вероятность прибыльной сделки очень мала, то почему бы нам не зайти в рынок с инвертированной позицией? Ну вот этот флажок включает такие позиции.
invers_buy_threshold=0.3 порог, когда вероятность прибыльной Buy позиции меньше то входим на селл
invers_sell_threshold=0.3; аналогично…
fast=12 параметры MACD
slow=34;
tp=40; Тэйк
sl=30; Стоп
close_orders=false; флажок включает закрытие по противоположному сигналу, только если ордер в прибыли…
Используем так: Сначала флажок Base - true, ставим sl=tp и прогоняем по истории (1 раз!) записывается файл векторов. Следующий раз ставим Base - false и пороги желательно оптимизировать, на априорня я выбираю глядя на 1-й отчёт(без классификации) если вероятность выигрыша = 0,5 то пороги 0,6 и 0,4(на инвертированные позиции)
До классификации:
После, с оптимизацией порогов.