Discussão do artigo "Redes neurais de maneira fácil (Parte 28): algoritmo de gradiente de política"
 Boa tarde.
Boa tarde.
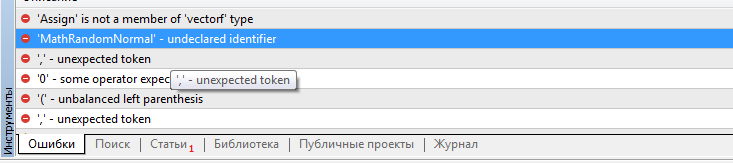
Dmitry, onde obter as funções values.Assign e MathRandomNormal? Seus scripts não foram criados e se referem à ausência dessas funções. O arquivo VAE.mqh foi rejeitado.
Boa tarde.
Dmitry, onde obter as funções values.Assign e MathRandomNormal? Seus scripts não foram criados e se referem à ausência dessas funções. O arquivo VAE.mqh foi rejeitado.
Bom dia, Victor.
Com relação a values.Assign, tente atualizar o terminal. Essa é uma função integrada adicionada recentemente à MQL5. MathRandomNormal está incluída na biblioteca padrão do terminal e é adicionada no arquivo "\MQL5\Include\Math\Stat\Normal.mqh" .
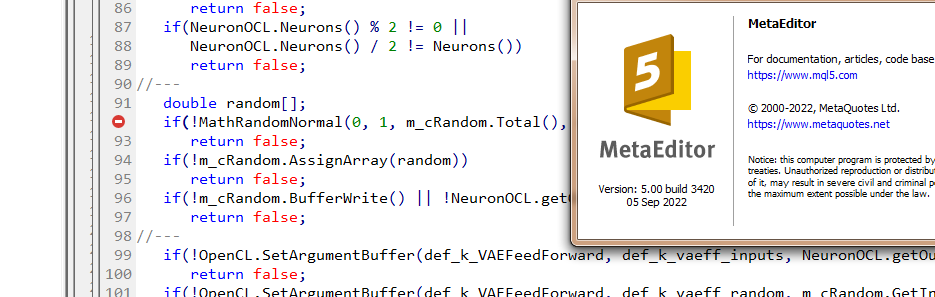
Dmitry, tenho a versão 3391 do terminal datada de 5 de agosto de 2022 (última versão estável). Agora tentei atualizar para a versão beta 3420 de 5 de setembro de 2022. O erro com values.Assign desapareceu. Mas o erro com MathRandomNormal não desapareceu. Tenho uma biblioteca com essa função no caminho, como você escreveu. Mas no arquivo VAE.mqh você não tem uma referência a essa biblioteca, mas no arquivo NeuroNet.mqh você especifica essa biblioteca da seguinte forma:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Mas não é assim que eu o montei. :(
PS: Se eu especificar o caminho para a biblioteca diretamente no arquivo VAE.mqh. É possível fazer isso? Eu realmente não entendo como você define a biblioteca no arquivo NeuroNet.mqh, não haverá um conflito?
Tentei adicionar a linha #include <Math\Stat\Normal . mqh> diretamente no arquivo VAE .mqh, mas não funcionou. O compilador ainda escreve 'MathRandomNormal' - identificador não declarado VAE.mqh 92 8. Se você apagar essa função e começar a digitar novamente, aparecerá uma dica de ferramenta com essa função, o que, pelo que entendi, indica que ela pode ser vista no arquivo VAE.mqh.
Em geral, tentei em outro computador com uma versão diferente da vinda, e o resultado é o mesmo - não vê a função e não compila. versão mais recente do mt5 betta 3420 de 5 de setembro de 2022.
Dmitry, você tem alguma configuração ativada no editor?
Em geral, tentei em outro computador com uma versão diferente do Windows, e o resultado é o mesmo - ele não vê a função e não compila. mt5 versão mais recente betta 3420 de 5 de setembro de 2022.
Dmitry, você tem alguma configuração ativada no editor?
Tente comentar a linha"namespace Math"
Dmitry, tenho a versão 3391 do terminal datada de 5 de agosto de 2022 (última versão estável). Agora tentei atualizar para a versão beta 3420 de 5 de setembro de 2022. O erro com values.Assign desapareceu. Mas o erro com MathRandomNormal não desapareceu. Tenho uma biblioteca com essa função no caminho, como você escreveu. Mas no arquivo VAE.mqh você não tem uma referência a essa biblioteca, mas no arquivo NeuroNet.mqh você especifica essa biblioteca da seguinte forma:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Mas não é assim que estou conseguindo fazer funcionar. :(
PS: Se especificar diretamente no arquivo VAE.mqh o caminho para a biblioteca. É possível fazer isso? Eu realmente não entendo como você define a biblioteca no arquivo NeuroNet.mqh, não haverá um conflito?
3445 de 23 de setembro - a mesma coisa.
 Olá.
Olá.
Preciso de conselhos :) Acabei de entrar no terminal após a reinstalação, quero fazer o treinamento e dá um erro
{kind=link}
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Redes neurais de maneira fácil (Parte 28): algoritmo de gradiente de política foi publicado:
Continuamos a estudar métodos de aprendizado por reforço. No artigo anterior, nos iniciamos no método de aprendizado Q profundo. Com ele, treinamos um modelo para prever a recompensa imediata dependendo da ação tomada por nós em uma determinada situação. E, em seguida, realizamos uma ação de acordo com nossa política e a recompensa esperada. Mas nem sempre é possível aproximar a função Q ou nem sempre sua aproximação dá o resultado desejado. Nesses casos, os métodos de aproximação são usados não para funções de utilidade, mas, sim, para uma política (estratégia) direta de ações. E é precisamente a esses métodos que o gradiente de política pertence.
Testamos primeiro o modelo DQN. E aqui recebemos uma surpresa. O modelo deu lucro. Mas, ao mesmo tempo, ela fez apenas uma operação de negociação, que ficou aberta durante todo o teste. O gráfico do instrumento com um negócio perfeito é mostrado abaixo.
Ao avaliar esse negócio no gráfico do instrumento, não se pode deixar de concordar que o modelo identificou claramente a tendência global e abriu um negócio em sua direção. O negócio é lucrativo, mas fica a dúvida: será que o modelo conseguirá fechar tal negócio a tempo? Na verdade, treinamos o modelo com dados históricos dos últimos 2 anos. E, durante todos os 2 anos, o mercado foi dominado por uma tendência de baixa para o instrumento analisado. Portanto, surge a dúvida de se o modelo conseguirá fechar o negócio a tempo.
E aqui é importante dizer que ao usar a estratégia gananciosa, o modelo de gradiente de política dá resultados semelhantes. E lembre que, quando começamos a estudar métodos de aprendizado por reforço, enfatizei repetidamente a necessidade da escolha certa da política de recompensa. E então decidi experimentar a política de recompensa. Em particular, para excluir o fato de permanecer muito tempo em uma posição de perda, decidi aumentar as penalidades para posições não lucrativas. E, consequentemente, treinei o modelo de gradiente de política levando em consideração a nova política de recompensa. Depois de vários experimentos com os hiperparâmetros do modelo, consegui atingir 60% de lucratividade nas operações. O gráfico de testes é mostrado abaixo.
O tempo médio de manutenção da posição é de 1 hora e 40 minutos.
Autor: Dmitriy Gizlyk