결과가 테스트와 유사해야 한다는 진술의 근거는 무엇인가요? 샘플이 동질적이지 않다고 가정합니다. 비슷한 수의 유사한 예가 없으며 퀀타에 대한 확률 분포가 약간 다르다고 생각합니다.
훈련. 저는 좋은 패턴이 있는 데이터에 대해 이야기하고 있습니다. 곱셈표의 1000가지 변형을 훈련에 입력하면 훈련과 일치하지 않는 새로운 변형(하지만 훈련의 경계 안에 있는)도 꽤 잘 계산됩니다. 하나의 트리가 가장 가까운 변형을 제공하고, 무작위 포레스트는 가장 가까운 100개의 변형을 평균화하여 하나의 트리보다 더 정확한 답을 제공할 가능성이 높습니다.
시장에 대해 규칙성을 가진 예측자를 찾을 수 있다면 OOS도 추적과 비슷할 것입니다. 그러나 지금처럼 모델의 절반 이상이 마이너스이고 1/3이 플러스인 것과는 다릅니다. 모든 성공적인 모델은 무작위 시드에서 우연히 그렇게되었습니다.
씨앗은 모델의 성공을 약간만 변경해야하며 일반적으로 모두 성공해야합니다. 이제 어떤 패턴도 발견되지 않았습니다(과잉 훈련/부족 훈련).
훈련 중지를 제어하는 데만 관여합니다. 즉, 훈련 중에 테스트에서 개선이없는 경우 훈련이 중지되고 테스트 모델에서 마지막으로 개선 된 지점까지 훈련이 중지되고 트리가 제거됩니다.
그러면 테스트도 좋은 이유가 분명해집니다. 본질적으로 테스트에 적합하기 때문입니다. 저는 한 번의 훈련을 위해 이 작업을 중단했습니다. 앞으로 밸런싱을 하고, 모든 OOC를 함께 붙인 다음, 붙인 여러 가지 OOC의 변형 중에서 가장 좋은 모델 하이퍼파라미터(깊이, 나무 수 등)를 선택합니다. 시험은 선택한 모든 OOS를 붙인 것과 거의 같을 것이라고 가정합니다. 5년 동안 그 변형에서 저는 일주일에 한 번씩 재교육을 받았는데, 이는 수백 개의 OOS 교육과 청크에 해당합니다.
일반적으로 몇 가지 예외를 제외하고는 3 개의 TF에서만 사용되기 때문에 더 많은 예측자를 추가 할 수 있지만 61 개의 예측자에 대한 10000 개의 변형 시드가 이러한 확산을 제공한다는 점을 고려할 때 모든 것이 훈련에 제대로 사용될지 여부는 의심 스럽습니다....
물론 예측자를 미리 선별해야 훈련 속도가 빨라집니다.
그들이 모두 거의 동일하다면 결과를 심각하게 개선하는 무언가를 찾을 가능성은 거의 없습니다. 완전히 새로운 데이터나 고유한 지표를 시도해 볼 수 있습니다.
예비 심사도 긴 작업이며 한 번에 하나씩 추가하는 것은 최대 3 개 기능까지 몇 배 더 길고 최대 10 개까지 추가하면 며칠입니다. 그러나 3-4 개의 기능 이후에는 일반적으로 개선이 없습니다. 그러나 때때로 있지만 증가는 적습니다. 거기에서 돌파구가 발견되지 않았습니다 (내 실험에서 누군가가 찾을 수 있습니다).
이상값은 이상값이라는 것은 논리적이며, 저는 이것이 비효율적이라고 생각하며 백색 잡음을 제거하여 배워야한다고 생각합니다. 다른 영역에서는 특히 평평한 시장 영역에서 간단한 원시 전략이 종종 작동합니다.
아래 그림은 수익성이 있지만 5 년 동안 2017 년에는 강력한 성장세를 보인 기간이 2 개뿐이었습니다 (분명히 예측 가능한 추세가 강함), 모델은이 2 개 기간에 가장 많은 돈을 벌었습니다. 그리고 시간이 지남에 따라 균일 한 성장을하는 것이 좋을 것입니다. 한 달 동안 활동하지 않으면 그러한 모델을 끄겠습니다. 물론 EA를 만들 수 있습니다-백조를 기다립니다. 하지만 저는 적극적인 거래를 선호합니다.
훈련. 좋은 패턴이 있는 데이터에 대해 이야기하고 있습니다. 학습을 위해 1000개의 구구단의 변형을 제출하면 학습과 일치하지 않는 새로운 변형(그러나 학습의 경계 안에 있는 변형)도 잘 계산됩니다. 나무 1개가 가장 가까운 변형을 제공하고, 무작위 숲은 가장 가까운 100개의 변형을 평균화하여 나무 1개보다 더 정확한 답을 제공할 가능성이 높습니다.
시장에 대해 규칙성을 가진 예측자를 찾을 수 있다면 OOS도 추적과 비슷할 것입니다. 그러나 지금처럼 모델의 절반 이상이 마이너스이고 1/3이 플러스인 것과는 다릅니다. 모든 성공적인 모델은 무작위 시드에서 우연히 그렇게 된 것입니다.
씨앗은 모델의 성공에 약간의 변화 만 가져와야하며 일반적으로 모두 성공해야합니다. 이제 어떤 패턴도 발견되지 않습니다(과훈련/부족 훈련).
좋은 데이터가 있으면 모든 것이 완벽하게 작동할 가능성이 높다고 주장하는 사람은 아무도 없습니다. 그러나 그러한 데이터를 얻을 수 없으므로 현재 가지고 있는 데이터에서 무엇을 짜낼 수 있는지 생각해야 합니다.
새로운 데이터에서 효과적인 모델을 무작위로 얻을 수 있다는 사실은 이러한 무작위성을 줄이는 방법, 즉 모델이 일관되게 구축 된 양자 세그먼트에 대한 규칙적인 메트릭이 있는지 궁금하게 만듭니다. 즉, 목표에 대한 탐욕 이외의 추가 메트릭에 대해 이야기하고 있습니다. 이러한 종속성을 설정할 수 있다면 성공 확률이 더 높은 모델을 구축할 수도 있습니다. 물론 이것은 다양한 샘플에서 작동해야 합니다.
그러면 테스트가 좋은 이유도 알 수 있습니다. 본질적으로 테스트에 적합하기 때문입니다. 저는 한 연구에서 이 작업을 중단했습니다. 저는 앞으로 밸런싱을 하고, 모든 OOC를 함께 붙인 다음, 붙인 여러 가지 OOC의 변형 중에서 가장 좋은 모델 하이퍼파라미터(깊이, 나무 수 등)를 선택합니다. 시험은 선택한 모든 OOS를 붙인 것과 거의 같을 것이라고 가정합니다. 5년 동안 그 변형에서 저는 일주일에 한 번씩 재교육을 받았는데, 이는 수백 개의 OOS 교육과 청크에 해당합니다.
가장 중요한 것은 마지막 시험 섹션을 분리하지 않는 것입니다.
하이퍼 파라미터를 피팅하고 결과를 평가하는 것은 무엇에 대한 것입니까? 귀하의 논리를 따른다면 평균화 요소와 동일한 피팅이라고 생각합니다.
CatBoost의 논리는 (Logloss로) 모델을 개선 할 수 없다면 더 이상 훈련 할 필요가 없다는 것입니다. 물론 이 경우 모델이 좋은 것으로 판명되었다는 보장은 없습니다.
글쎄요, 5000 개 이상에서 선택한 61 개. 나는 총 수와 선택한 수를 모두 가지고 있습니다. 그리고 한 번에 1 개씩 추가 할 때 3-4 개를 선택한 후 기능을 더 추가하면 OOS에서 결과가 악화 될뿐입니다.
아니요, 제가 선택한 것이 아니라 모든 예측자에 대해 학습할 때 모델에서 가져온 것입니다.
저는 일반적으로 예측자를 양자 세그먼트의 집합으로 간주합니다. 그리고 이러한 이유로 저는 양자 세그먼트를 선택하고 일반적으로 모든 예측자를 이진 세그먼트로 분해 할 수도 있습니다. 결과는 약간 나쁘지만 비슷합니다. 아마도 이진 방전 예측자의 경우 특별한 훈련 방법이 필요할 것입니다.
사전 스크리닝도 긴 작업이며 하나씩 추가하는 데 몇 배 더 오래 걸리고 최대 3 개 기능까지 추가하면 10 일까지 며칠이 걸립니다. 그러나 의미가 없습니다. 3-4 개 기능 이후에는 일반적으로 개선이 없습니다. 그러나 때때로 있지만 증가는 적습니다. 거기에서 돌파구를 찾지 못했습니다 (제 실험에서 누군가는 찾을 수 있습니다).
당신이 말하는 변형은 긴 게임이기 때문에 제가 플레이하지 않는 이유입니다 (음, 완전 자동화가 없습니다). 그러나 나는 효과가 없다는 데 동의하지 않습니다. 나는 그룹을 줄이면서 그룹에서 중퇴를했고 그 결과는 긍정적이었습니다. 그러나 저는 여전히 이러한 행동이 적합성 또는 무작위성에 기인한다고 생각합니다. 예측 변수 선택에 대한 정당성은 없습니다.
하단 수치는 수익성이 있지만 5 년 동안 2017 년에는 강한 성장세를 보인 기간이 2 개뿐이며 (분명히 예측 가능한 추세가 있음) 모델은이 2 개 기간 동안 가장 많은 수익을 올렸습니다. 그리고 시간이 지남에 따라 균일 한 성장을하는 것이 좋을 것입니다. 한 달 동안 활동하지 않으면 이러한 모델을 끄겠습니다.
물론 백조를 기다리는 전문가 고문을 만들 수 있습니다. 하지만 저는 적극적인 트레이딩을 선호합니다.
그렇기 때문에 저는 모델 세트를 사용하는 것을 선호하는데, 각 모델이 빈번하지 않은 패턴을 포착할 수 있다는 것을 알고 있기 때문입니다.
엘리바리우스 #: 일반적으로 훈련과 테스트의 오차가 거의 같도록 하는 것이 목표입니다. 여기서 시험은 훈련과 테스트를 향해, 즉 위로 이동하고 있으며 테스트는 테스트를 향해, 즉 아래로 이동하고 있습니다. 과잉 훈련은 감소합니다.
어떤 지표로 비슷한가요?
예를 들어 정밀도 지표를 가져와서 훈련에서 테스트 샘플의 이 지표를 빼면 델타(y축)가 나오고, x로 시험 샘플의 수익을 살펴볼 수 있습니다.
특별한 의존성이 없나요?
아래는 각 샘플에 대한 두 가지 메트릭으로, 새 트리가 모델에 추가될 때 데이터가 수집됩니다.
포럼 스타일로 답장을 작성할 때 답장을 여러 번 클릭하는 것이 불편합니다. 내 답변 아래는 색상으로 강조 표시되어 있습니다.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> 오래 전에 퀀타가 어떻게 만들어지는지, 기본 변형을 보았습니다. 먼저 열이 정렬됩니다. 1) 범위별, 짝수 단계 (예 : 0에서 1까지의 값 단계가 정확히 0.1을 통해 총 10 개의 양자 0.1, 0.2, 0.3 ... 0.9) 2) 백분위수 - 즉, 예제 수에 따라. 10 개의 양자로 나누면 각 양자에서 모든 행 수의 10 %를 넣고 복식이 많으면 복식이 다른 양자에 떨어지지 않아야하기 때문에 일부 양자는 10 % 이상이 될 것입니다 (예 : 복식이 샘플의 30 %이면이 양자에서는 모두 떨어집니다.) 예를 들어 복식이 샘플의 30 %이면이 양자에서는 모두 떨어집니다. 각 퀀텀의 샘플 수에 따라 분포는 0.001, 0.12,0.45,0.51,0.74, .... 0.98. 3) 두 가지 유형의 조합이 있습니다.
따라서 양자를 구성하는 데 아주 영리한 방법은 없습니다. 저는 이 두 가지 양자화 방법을 모두 직접 만들었습니다. 그리고 언제나 그렇듯이 저는 제가 더 낫다고 생각하는 방식으로 무언가를 했습니다. 제가 실수를 했을 수도 있습니다. 그리고 저는 보통 양자화하지 않고 부동 소수점 데이터로 계산을 합니다. 모든 예측자를 2진수로 만들면 양자 수가 2개만 남게 되는데, 하나는 모두 0이고 다른 하나는 모두 1입니다.
하이퍼파라미터를 맞추고 결과를 무엇으로 평가하나요? 논리대로라면 평균화 요소와 동일한 피팅이라고 생각합니다.
> 저는 밸런스 차트와 드로다운을 살펴봅니다. 아직 선택을 자동화할 수 없었습니다. 예, 피팅은 더 나은 OOS 접착을 위한 것입니다. 그러나 모델 자체(즉, 트레이스가 아니라)가 아니라 모델의 최상의 하이퍼파라미터를 선택하는 것입니다.
"거의 동일"이란 무슨 뜻인가요, 어떤 메트릭에 대해 이야기하고 계신 건가요? 물론 다른 데이터, 예를 들어 다른 도구를 사용해 볼 수 있습니다.
> 모두 가격과 매시업으로 만들어집니다.
오래된 질문입니다.
결과가 기차와 비슷해야 한다는 진술의 근거는 무엇인가요? 샘플이 동질적이지 않다고 가정하고 있습니다. 비슷한 예가 비교할 수 없을 정도로 많지 않고 양자의 확률 분포가 약간 다르다고 생각합니다.
В статье рассматриваются новые возможности пакета darch (v.0.12.0). Описаны результаты обучения глубокой нейросети с различными типами данных, структурой и последовательностью обучения. Проанализированы результаты.
따라서 양자 구조에서 아주 똑똑한 것은 없습니다. 저는 이 두 가지 양자화 방법을 모두 직접 만들었습니다. 그리고 언제나 그렇듯이 저는 제가 더 낫다고 생각하는 방식으로 무언가를 했습니다. 제가 실수했을 수도 있습니다. 그리고 저는 보통 양자화하지 않고 부동 소수점 데이터를 사용하여 계산을 합니다.
물론 다른 방법도 있지만 저는 현재 약 900개의 양자 테이블을 사용합니다.
요점은 방법이 아니라 이진 대상의 평균값이 샘플보다 높은 예측자의 범위를 선택하는 데 있습니다 (이제는 예제 수에 최소 5 % 플러스 기준을 적용했습니다. 또한 예측자에 유용한 정보를 나타냅니다). 그러한 정보가 없으면 몇 가지 분할로 나타나기를 바랄 수 있지만 가능성은 적다고 생각합니다.
사실, 그러한 플롯이 1-2 개 있고 실제로는 거의 많지 않습니다. 그리고 여기에서는 이러한 플롯 만 가져 오거나 이러한 플롯으로 예측자를 가져 와서 최상의 양자 테이블을 선택할 수 있습니다.
개인적으로 저는 적어도 제 예측자가 확률의 부드러운 전환이 아니라 불연속적으로 발생하고 반대 편차, 즉 +5에서 즉시 -5로 변경되는 것을 보았습니다. 이러한 확률이 순서대로 정렬되면 범위에서 훈련되기 때문에 모델을 훈련하기가 더 쉬울 것이라고 생각합니다. 이것이 정보가없는 영역을 제외하고 상충되는 영역을 분리하는 것이 합당한 이유입니다.
시장에서는 이와 같은 일이 더 자주 발생합니다: 좋은 테스트이지만 일부 훈련 단계(세 번째 단계 이후의 그림에서) 후에 재훈련이 시작되고 테스트 오류가 증가하기 시작합니다. 그림은 신경망을 참조하지만 모델이 과도하게 훈련될 때 포리스트와 부스트에서도 이와 같은 현상이 발생합니다.
규칙성은 항상 발견되는 것이 원칙이며, 문제는 이 규칙성이 계속 나타날지 여부입니다.
어떤 종류의 샘플을 사용했는지 모르겠습니다. 테스트가 훈련보다 빠르게 학습하는 경우도 있었지만, 그 반대의 경우가 더 많으며 둘 사이에 눈에 띄는 차이가 있습니다. 물론 이상적인 조건에서는 그 차이가 작을 것입니다.
샘플이 매우 유사하지 않고 개선이 없을 때 훈련이 중단되기 때문에 모델이 덜 훈련되었다고 확실히 말할 수 있습니다.
언젠가 재학습된 샘플이 그래픽으로 어떻게 보이는지 보여드리겠습니다. 모서리로 구분된 두 개의 돌출부입니다....
요점은 방법이 아니라 이진 대상의 평균값이 샘플보다 높은 예측자 범위의 선택입니다 (이제 최소 5 %와 예제 수에 대한 기준을 설정했습니다-또한 최소 5 %), 이는 예측자에 유용한 정보를 나타냅니다. 그러한 정보가 없다면 она появиться через пяток сплитов 을 기대할 수 있지만 가능성은 낮다고 생각합니다.
분할은 양자까지만 이루어집니다. 양자 내부의 모든 것은 동일한 값으로 간주되며 더 이상 분할되지 않습니다. 나는 당신이 양자에서 무언가를 찾고있는 이유를 이해하지 못합니다. 주요 목적은 계산 속도를 높이는 것입니다 (2 차 목적은 더 이상 분할이 없도록 모델을로드 / 일반화하는 것이지만 플로트 데이터의 깊이를 제한 할 수 있습니다) 나는 그것을 사용하지 않고 플로트 데이터로 모델을 만들뿐입니다. 65,000개의 부품에 대해 정량화를 수행했는데 결과는 정량화하지 않은 모델과 완전히 동일합니다.
개인적으로, 적어도 내 예측은 확률이 부드럽게 전환되는 것이 아니라 갑자기 발생하고 반대 편차로 변경되는 것을 보았습니다. 즉, +5 였다가 즉시 -5가되었습니다.
또한 이와 같은 것을 발견했습니다. 깊이를 1만큼 늘리면 수익성이 극적으로 변화하며 때로는 +에서 때로는 -에서 변경됩니다.
사실, 0.5가 하나 있습니다 :) 그러나 이렇게하면 예측자를 유용한 (잠재적으로 유용한 정보를 포함하는) 범위로 분할 할 수 있습니다.
데이터를 두 개의 섹터로 나누는 분할이 1 개있을 것입니다. 하나는 모두 0이고 다른 하나는 모두 1입니다. 퀀타라는 것이 무엇인지 모르겠지만, 퀀타는 양자화 후 얻은 섹터의 수라고 생각합니다. 아마도 말씀하신 것처럼 분할의 수일 것입니다.
이 샘플에서 2년을 더 줄였더니 시험 평균은 이미 -485점( 1214점 )이 되었고, 3000점 한도를 통과한 모델의 수는 884개( 지난번에는 277개)가 되었습니다.
그러나 테스트 샘플의 결과는 평균 2115점에서 186점으로, 즉 크게 악화되었습니다. 이것은 무엇일까요 - 훈련 샘플에서 테스트 샘플과 유사한 예가 더 적었나요?
평균 트리 수가 10개에서 7개로 감소했습니다.
그래프의 제로 브레이크는 균형 분포를 중앙으로 이동시켰습니다.
결과가 테스트와 유사해야 한다는 진술의 근거는 무엇인가요? 샘플이 동질적이지 않다고 가정합니다. 비슷한 수의 유사한 예가 없으며 퀀타에 대한 확률 분포가 약간 다르다고 생각합니다.
훈련. 저는 좋은 패턴이 있는 데이터에 대해 이야기하고 있습니다. 곱셈표의 1000가지 변형을 훈련에 입력하면 훈련과 일치하지 않는 새로운 변형(하지만 훈련의 경계 안에 있는)도 꽤 잘 계산됩니다. 하나의 트리가 가장 가까운 변형을 제공하고, 무작위 포레스트는 가장 가까운 100개의 변형을 평균화하여 하나의 트리보다 더 정확한 답을 제공할 가능성이 높습니다.
시장에 대해 규칙성을 가진 예측자를 찾을 수 있다면 OOS도 추적과 비슷할 것입니다. 그러나 지금처럼 모델의 절반 이상이 마이너스이고 1/3이 플러스인 것과는 다릅니다. 모든 성공적인 모델은 무작위 시드에서 우연히 그렇게되었습니다.
씨앗은 모델의 성공을 약간만 변경해야하며 일반적으로 모두 성공해야합니다. 이제 어떤 패턴도 발견되지 않았습니다(과잉 훈련/부족 훈련).
훈련 중지를 제어하는 데만 관여합니다. 즉, 훈련 중에 테스트에서 개선이없는 경우 훈련이 중지되고 테스트 모델에서 마지막으로 개선 된 지점까지 훈련이 중지되고 트리가 제거됩니다.
그러면 테스트도 좋은 이유가 분명해집니다. 본질적으로 테스트에 적합하기 때문입니다. 저는 한 번의 훈련을 위해 이 작업을 중단했습니다. 앞으로 밸런싱을 하고, 모든 OOC를 함께 붙인 다음, 붙인 여러 가지 OOC의 변형 중에서 가장 좋은 모델 하이퍼파라미터(깊이, 나무 수 등)를 선택합니다. 시험은 선택한 모든 OOS를 붙인 것과 거의 같을 것이라고 가정합니다. 5년 동안 그 변형에서 저는 일주일에 한 번씩 재교육을 받았는데, 이는 수백 개의 OOS 교육과 청크에 해당합니다.
분명히 제가 사용한 샘플을 명확하게 표시하지 않은 것 같습니다. 이것은 여기에 설명 된 실험의 여섯 번째 (마지막) 샘플이므로 예측 변수는 61 개뿐입니다.
특히 평평한 시장 영역에서 원시적 인 전략.5000개 이상 중에서 이 61개를 골랐군요. 총 개수도 적고 선택한 개수도 적습니다. 그리고 한 번에 1 개씩 추가 할 때 3-4 개를 선택한 후 표지판을 더 추가하면 OOS의 결과가 악화 될뿐입니다.
일반적으로 몇 가지 예외를 제외하고는 3 개의 TF에서만 사용되기 때문에 더 많은 예측자를 추가 할 수 있지만 61 개의 예측자에 대한 10000 개의 변형 시드가 이러한 확산을 제공한다는 점을 고려할 때 모든 것이 훈련에 제대로 사용될지 여부는 의심 스럽습니다....
물론 예측자를 미리 선별해야 훈련 속도가 빨라집니다.
그들이 모두 거의 동일하다면 결과를 심각하게 개선하는 무언가를 찾을 가능성은 거의 없습니다. 완전히 새로운 데이터나 고유한 지표를 시도해 볼 수 있습니다.
예비 심사도 긴 작업이며 한 번에 하나씩 추가하는 것은 최대 3 개 기능까지 몇 배 더 길고 최대 10 개까지 추가하면 며칠입니다. 그러나 3-4 개의 기능 이후에는 일반적으로 개선이 없습니다. 그러나 때때로 있지만 증가는 적습니다. 거기에서 돌파구가 발견되지 않았습니다 (내 실험에서 누군가가 찾을 수 있습니다).
이상값은 이상값이라는 것은 논리적이며, 저는 이것이 비효율적이라고 생각하며 백색 잡음을 제거하여 배워야한다고 생각합니다. 다른 영역에서는 특히 평평한 시장 영역에서 간단한 원시 전략이 종종 작동합니다.
아래 그림은 수익성이 있지만 5 년 동안 2017 년에는 강력한 성장세를 보인 기간이 2 개뿐이었습니다 (분명히 예측 가능한 추세가 강함), 모델은이 2 개 기간에 가장 많은 돈을 벌었습니다. 그리고 시간이 지남에 따라 균일 한 성장을하는 것이 좋을 것입니다. 한 달 동안 활동하지 않으면 그러한 모델을 끄겠습니다.
물론 EA를 만들 수 있습니다-백조를 기다립니다. 하지만 저는 적극적인 거래를 선호합니다.
이 샘플에서 2년을 더 줄이면 시험 평균은 이미 -485(이전에는 -1214 )가 되고, 3000점 한도를 돌파한 모델 수는 884개( 이전에는 277개)가 됩니다.
그러나 테스트 샘플의 결과는 평균 2115점에서 186점으로, 즉 크게 악화되었습니다. 이것은 무엇인가요 - 훈련 샘플에서 테스트 샘플과 유사한 예가 더 적은 것일까요?
평균 나무 수는 10개에서 7개로 감소했습니다.
그래프의 제로 브레이크는 균형 분포를 중앙으로 이동시켰습니다.
첫 번째 게시물의 파일을 게시해 주시면 한 가지 아이디어도 시도해보고 싶습니다.
훈련. 좋은 패턴이 있는 데이터에 대해 이야기하고 있습니다. 학습을 위해 1000개의 구구단의 변형을 제출하면 학습과 일치하지 않는 새로운 변형(그러나 학습의 경계 안에 있는 변형)도 잘 계산됩니다. 나무 1개가 가장 가까운 변형을 제공하고, 무작위 숲은 가장 가까운 100개의 변형을 평균화하여 나무 1개보다 더 정확한 답을 제공할 가능성이 높습니다.
시장에 대해 규칙성을 가진 예측자를 찾을 수 있다면 OOS도 추적과 비슷할 것입니다. 그러나 지금처럼 모델의 절반 이상이 마이너스이고 1/3이 플러스인 것과는 다릅니다. 모든 성공적인 모델은 무작위 시드에서 우연히 그렇게 된 것입니다.
씨앗은 모델의 성공에 약간의 변화 만 가져와야하며 일반적으로 모두 성공해야합니다. 이제 어떤 패턴도 발견되지 않습니다(과훈련/부족 훈련).
좋은 데이터가 있으면 모든 것이 완벽하게 작동할 가능성이 높다고 주장하는 사람은 아무도 없습니다. 그러나 그러한 데이터를 얻을 수 없으므로 현재 가지고 있는 데이터에서 무엇을 짜낼 수 있는지 생각해야 합니다.
새로운 데이터에서 효과적인 모델을 무작위로 얻을 수 있다는 사실은 이러한 무작위성을 줄이는 방법, 즉 모델이 일관되게 구축 된 양자 세그먼트에 대한 규칙적인 메트릭이 있는지 궁금하게 만듭니다. 즉, 목표에 대한 탐욕 이외의 추가 메트릭에 대해 이야기하고 있습니다. 이러한 종속성을 설정할 수 있다면 성공 확률이 더 높은 모델을 구축할 수도 있습니다. 물론 이것은 다양한 샘플에서 작동해야 합니다.
그러면 테스트가 좋은 이유도 알 수 있습니다. 본질적으로 테스트에 적합하기 때문입니다. 저는 한 연구에서 이 작업을 중단했습니다. 저는 앞으로 밸런싱을 하고, 모든 OOC를 함께 붙인 다음, 붙인 여러 가지 OOC의 변형 중에서 가장 좋은 모델 하이퍼파라미터(깊이, 나무 수 등)를 선택합니다. 시험은 선택한 모든 OOS를 붙인 것과 거의 같을 것이라고 가정합니다. 5년 동안 그 변형에서 저는 일주일에 한 번씩 재교육을 받았는데, 이는 수백 개의 OOS 교육과 청크에 해당합니다.
가장 중요한 것은 마지막 시험 섹션을 분리하지 않는 것입니다.
하이퍼 파라미터를 피팅하고 결과를 평가하는 것은 무엇에 대한 것입니까? 귀하의 논리를 따른다면 평균화 요소와 동일한 피팅이라고 생각합니다.
CatBoost의 논리는 (Logloss로) 모델을 개선 할 수 없다면 더 이상 훈련 할 필요가 없다는 것입니다. 물론 이 경우 모델이 좋은 것으로 판명되었다는 보장은 없습니다.
글쎄요, 5000 개 이상에서 선택한 61 개. 나는 총 수와 선택한 수를 모두 가지고 있습니다. 그리고 한 번에 1 개씩 추가 할 때 3-4 개를 선택한 후 기능을 더 추가하면 OOS에서 결과가 악화 될뿐입니다.
아니요, 제가 선택한 것이 아니라 모든 예측자에 대해 학습할 때 모델에서 가져온 것입니다.
저는 일반적으로 예측자를 양자 세그먼트의 집합으로 간주합니다. 그리고 이러한 이유로 저는 양자 세그먼트를 선택하고 일반적으로 모든 예측자를 이진 세그먼트로 분해 할 수도 있습니다. 결과는 약간 나쁘지만 비슷합니다. 아마도 이진 방전 예측자의 경우 특별한 훈련 방법이 필요할 것입니다.
그들이 모두 거의 동일하다면 결과를 심각하게 개선하는 것이 이미 발견 될 가능성은 거의 없습니다. 완전히 새로운 데이터 또는 고유한 지표를 사용해 볼 수 있습니다.
"거의 같다"는 것이 무슨 뜻인가요, 메트릭에 대해 이야기하는 건가요? 물론 다른 데이터, 예를 들어 다른 도구를 사용하여 다른 데이터를 시도해 볼 수 있습니다.
사전 스크리닝도 긴 작업이며 하나씩 추가하는 데 몇 배 더 오래 걸리고 최대 3 개 기능까지 추가하면 10 일까지 며칠이 걸립니다. 그러나 의미가 없습니다. 3-4 개 기능 이후에는 일반적으로 개선이 없습니다. 그러나 때때로 있지만 증가는 적습니다. 거기에서 돌파구를 찾지 못했습니다 (제 실험에서 누군가는 찾을 수 있습니다).
당신이 말하는 변형은 긴 게임이기 때문에 제가 플레이하지 않는 이유입니다 (음, 완전 자동화가 없습니다). 그러나 나는 효과가 없다는 데 동의하지 않습니다. 나는 그룹을 줄이면서 그룹에서 중퇴를했고 그 결과는 긍정적이었습니다. 그러나 저는 여전히 이러한 행동이 적합성 또는 무작위성에 기인한다고 생각합니다. 예측 변수 선택에 대한 정당성은 없습니다.
하단 수치는 수익성이 있지만 5 년 동안 2017 년에는 강한 성장세를 보인 기간이 2 개뿐이며 (분명히 예측 가능한 추세가 있음) 모델은이 2 개 기간 동안 가장 많은 수익을 올렸습니다. 그리고 시간이 지남에 따라 균일 한 성장을하는 것이 좋을 것입니다. 한 달 동안 활동하지 않으면 이러한 모델을 끄겠습니다.
물론 백조를 기다리는 전문가 고문을 만들 수 있습니다. 하지만 저는 적극적인 트레이딩을 선호합니다.
그렇기 때문에 저는 모델 세트를 사용하는 것을 선호하는데, 각 모델이 빈번하지 않은 패턴을 포착할 수 있다는 것을 알고 있기 때문입니다.
일반적으로 훈련과 테스트의 오차가 거의 같도록 하는 것이 목표입니다. 여기서 시험은 훈련과 테스트를 향해, 즉 위로 이동하고 있으며 테스트는 테스트를 향해, 즉 아래로 이동하고 있습니다. 과잉 훈련은 감소합니다.
어떤 지표로 비슷한가요?
예를 들어 정밀도 지표를 가져와서 훈련에서 테스트 샘플의 이 지표를 빼면 델타(y축)가 나오고, x로 시험 샘플의 수익을 살펴볼 수 있습니다.
특별한 의존성이 없나요?
아래는 각 샘플에 대한 두 가지 메트릭으로, 새 트리가 모델에 추가될 때 데이터가 수집됩니다.
이 모델의 특징은 다음과 같습니다.
다음은 두 샘플의 손실이 있는 다른 모델의 메트릭입니다.
이 모델의 특징은 다음과 같습니다.
포럼 스타일로 답장을 작성할 때 답장을 여러 번 클릭하는 것이 불편합니다. 내 답변 아래는 색상으로 강조 표시되어 있습니다.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> 오래 전에 퀀타가 어떻게 만들어지는지, 기본 변형을 보았습니다. 먼저 열이 정렬됩니다.
1) 범위별, 짝수 단계 (예 : 0에서 1까지의 값 단계가 정확히 0.1을 통해 총 10 개의 양자 0.1, 0.2, 0.3 ... 0.9)
2) 백분위수 - 즉, 예제 수에 따라. 10 개의 양자로 나누면 각 양자에서 모든 행 수의 10 %를 넣고 복식이 많으면 복식이 다른 양자에 떨어지지 않아야하기 때문에 일부 양자는 10 % 이상이 될 것입니다 (예 : 복식이 샘플의 30 %이면이 양자에서는 모두 떨어집니다.) 예를 들어 복식이 샘플의 30 %이면이 양자에서는 모두 떨어집니다. 각 퀀텀의 샘플 수에 따라 분포는 0.001, 0.12,0.45,0.51,0.74, .... 0.98.
3) 두 가지 유형의 조합이 있습니다.
따라서 양자를 구성하는 데 아주 영리한 방법은 없습니다. 저는 이 두 가지 양자화 방법을 모두 직접 만들었습니다. 그리고 언제나 그렇듯이 저는 제가 더 낫다고 생각하는 방식으로 무언가를 했습니다. 제가 실수를 했을 수도 있습니다. 그리고 저는 보통 양자화하지 않고 부동 소수점 데이터로 계산을 합니다.
모든 예측자를 2진수로 만들면 양자 수가 2개만 남게 되는데, 하나는 모두 0이고 다른 하나는 모두 1입니다.
하이퍼파라미터를 맞추고 결과를 무엇으로 평가하나요? 논리대로라면 평균화 요소와 동일한 피팅이라고 생각합니다.
> 저는 밸런스 차트와 드로다운을 살펴봅니다. 아직 선택을 자동화할 수 없었습니다. 예, 피팅은 더 나은 OOS 접착을 위한 것입니다. 그러나 모델 자체(즉, 트레이스가 아니라)가 아니라 모델의 최상의 하이퍼파라미터를 선택하는 것입니다.
"거의 동일"이란 무슨 뜻인가요, 어떤 메트릭에 대해 이야기하고 계신 건가요? 물론 다른 데이터, 예를 들어 다른 도구를 사용해 볼 수 있습니다.
> 모두 가격과 매시업으로 만들어집니다.
오래된 질문입니다.
결과가 기차와 비슷해야 한다는 진술의 근거는 무엇인가요? 샘플이 동질적이지 않다고 가정하고 있습니다. 비슷한 예가 비교할 수 없을 정도로 많지 않고 양자의 확률 분포가 약간 다르다고 생각합니다.
> 여기 예시 https://www.mql5.com/ru/articles/3473
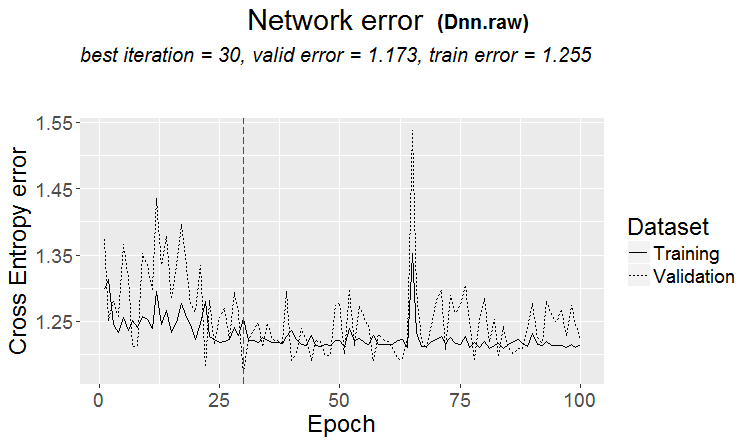
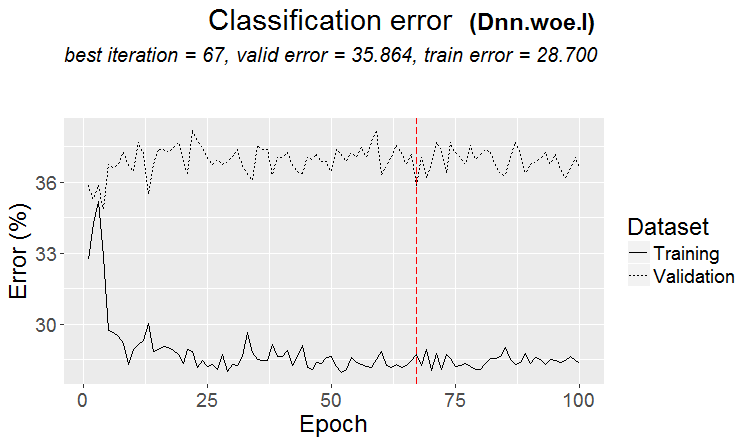
좋은 변형은 패턴이 발견될 때입니다: 삼항식과 테스트의 오류가 거의 같습니다
시장에서는 이와 같은 일이 더 자주 발생합니다: 테스트는 좋지만 어떤 훈련 단계(그림에서 3단계 이후) 후에 재훈련이 시작되고 테스트 오류가 커지기 시작합니다. 그림은 신경망을 나타내지만 모델이 과도하게 훈련될 때 포리스트와 부스트에서도 이와 같은 현상이 발생합니다.
어떤 지표로 비슷한가요?
하지만 그렇다고 해서 지표가 나쁘다는 의미는 아닙니다.
따라서 양자 구조에서 아주 똑똑한 것은 없습니다. 저는 이 두 가지 양자화 방법을 모두 직접 만들었습니다. 그리고 언제나 그렇듯이 저는 제가 더 낫다고 생각하는 방식으로 무언가를 했습니다. 제가 실수했을 수도 있습니다. 그리고 저는 보통 양자화하지 않고 부동 소수점 데이터를 사용하여 계산을 합니다.
물론 다른 방법도 있지만 저는 현재 약 900개의 양자 테이블을 사용합니다.
요점은 방법이 아니라 이진 대상의 평균값이 샘플보다 높은 예측자의 범위를 선택하는 데 있습니다 (이제는 예제 수에 최소 5 % 플러스 기준을 적용했습니다. 또한 예측자에 유용한 정보를 나타냅니다). 그러한 정보가 없으면 몇 가지 분할로 나타나기를 바랄 수 있지만 가능성은 적다고 생각합니다.
사실, 그러한 플롯이 1-2 개 있고 실제로는 거의 많지 않습니다. 그리고 여기에서는 이러한 플롯 만 가져 오거나 이러한 플롯으로 예측자를 가져 와서 최상의 양자 테이블을 선택할 수 있습니다.
개인적으로 저는 적어도 제 예측자가 확률의 부드러운 전환이 아니라 불연속적으로 발생하고 반대 편차, 즉 +5에서 즉시 -5로 변경되는 것을 보았습니다. 이러한 확률이 순서대로 정렬되면 범위에서 훈련되기 때문에 모델을 훈련하기가 더 쉬울 것이라고 생각합니다. 이것이 정보가없는 영역을 제외하고 상충되는 영역을 분리하는 것이 합당한 이유입니다.
모든 예측자를 2진수로 만들면 하나는 모두 0이고 하나는 모두 1인 2개의 퀀타만 존재하게 됩니다.
실제로는 하나 - 0,5 :) 하지만 이렇게 하면 예측자를 유용한(잠재적으로 유용한 정보를 포함하는) 범위로 분해할 수 있습니다.
> 잔액 차트와 드로다운 보기. 선택 자동화는 아직 해결되지 않았습니다. 예 피팅 - 최고의 OOS 접착을 위해. 그러나 모델 자체(즉, 트레이스가 아니라)가 아니라 모델의 최상의 하이퍼파라미터를 선택하는 것입니다.
글쎄요, 이해할 수 있지만 표준은 아닙니다. 모델 메트릭도 중요하다고 생각합니다.
> 이 모든 것은 가격과 매시업에서 이루어집니다.
이론적으로는 예, 그리고 신경망을 사용하는 경우 실제로는 일반 사용자의 컴퓨팅 능력이 없기 때문에 너무 복잡한 종속성을 다른 계산으로 검색해야합니다.
오래된 질문에 대해.
> 여기 예시 https://www.mql5.com/ru/articles/3473
좋은 변형은 패턴이 발견될 때입니다: 삼항식과 테스트는 거의 동일한 오류가 있습니다
시장에서는 이와 같은 일이 더 자주 발생합니다: 좋은 테스트이지만 일부 훈련 단계(세 번째 단계 이후의 그림에서) 후에 재훈련이 시작되고 테스트 오류가 증가하기 시작합니다. 그림은 신경망을 참조하지만 모델이 과도하게 훈련될 때 포리스트와 부스트에서도 이와 같은 현상이 발생합니다.
규칙성은 항상 발견되는 것이 원칙이며, 문제는 이 규칙성이 계속 나타날지 여부입니다.
어떤 종류의 샘플을 사용했는지 모르겠습니다. 테스트가 훈련보다 빠르게 학습하는 경우도 있었지만, 그 반대의 경우가 더 많으며 둘 사이에 눈에 띄는 차이가 있습니다. 물론 이상적인 조건에서는 그 차이가 작을 것입니다.
샘플이 매우 유사하지 않고 개선이 없을 때 훈련이 중단되기 때문에 모델이 덜 훈련되었다고 확실히 말할 수 있습니다.
언젠가 재학습된 샘플이 그래픽으로 어떻게 보이는지 보여드리겠습니다. 모서리로 구분된 두 개의 돌출부입니다....
교육 샘플을 반으로 더 자릅니다.
모델은 306개에 불과하며 시험별 평균 수익은 -2791점입니다.
하지만 이 모델을 얻었습니다.
다음과 같은 특징이 있습니다.
매트 기대치는 확실히 떨어졌지만 리콜은 많은 수의 거래가 있는 그래프로 인해 두 배로 증가했습니다.
이러한 예측 변수가 사용되었습니다:
그리고 샘플보다 9 개가 적습니다. 그것들만 가져 와서 전체 샘플 (모든 기차 노선에서)에서 훈련하려고합니다.
분할은 양자까지만 이루어집니다. 양자 내부의 모든 것은 동일한 값으로 간주되며 더 이상 분할되지 않습니다. 나는 당신이 양자에서 무언가를 찾고있는 이유를 이해하지 못합니다. 주요 목적은 계산 속도를 높이는 것입니다 (2 차 목적은 더 이상 분할이 없도록 모델을로드 / 일반화하는 것이지만 플로트 데이터의 깊이를 제한 할 수 있습니다) 나는 그것을 사용하지 않고 플로트 데이터로 모델을 만들뿐입니다. 65,000개의 부품에 대해 정량화를 수행했는데 결과는 정량화하지 않은 모델과 완전히 동일합니다.
개인적으로, 적어도 내 예측은 확률이 부드럽게 전환되는 것이 아니라 갑자기 발생하고 반대 편차로 변경되는 것을 보았습니다. 즉, +5 였다가 즉시 -5가되었습니다.
또한 이와 같은 것을 발견했습니다. 깊이를 1만큼 늘리면 수익성이 극적으로 변화하며 때로는 +에서 때로는 -에서 변경됩니다.
사실, 0.5가 하나 있습니다 :) 그러나 이렇게하면 예측자를 유용한 (잠재적으로 유용한 정보를 포함하는) 범위로 분할 할 수 있습니다.
데이터를 두 개의 섹터로 나누는 분할이 1 개있을 것입니다. 하나는 모두 0이고 다른 하나는 모두 1입니다. 퀀타라는 것이 무엇인지 모르겠지만, 퀀타는 양자화 후 얻은 섹터의 수라고 생각합니다. 아마도 말씀하신 것처럼 분할의 수일 것입니다.