rfeControl = rfeControl(number = 1,repeats = 1) 설정 - 시간을 10-15분으로 줄였습니다. 결과 변경 - 2쌍의 예측 변수가 위치를 변경했지만 일반적으로 기본적으로 원래대로 보입니다.
글쎄요, 여기 한 코어에서 10분이 제 2 x 4이고 2분이 기억나지 않습니다.
나는 몇 시간 동안 무언가를 기다리지 않습니다. 10-15 분이 작동하지 않으면 문제가 발생하고 더 많은 시간을 보내더라도 아무런 이점이 없습니다. 몇 시간 동안 지속되는 모델을 구축할 때의 최적화는 모델이 최소한으로 거칠고 어떤 경우에도 최대한 정확해야 한다고 말하는 모델링 이데올로기에 대한 완전한 오해입니다.
선택에서 가장 중요한 것은 과적합 문제를 해결하려는 시도입니다. 모델이 재교육되었습니까? 그렇지 않은 경우 선택은 더 적은 수의 예측 변수를 희생시키면서 학습 속도를 높일 수 있습니다. 그러나 주요 구성 요소를 분리하여 양을 줄이는 것이 훨씬 더 효율적입니다. 그것들은 아무 영향도 미치지 않지만 예측 변수의 수를 10배 정도 줄일 수 있으므로 모델 피팅 속도를 높일 수 있습니다.
파란색은 좋음, 빨간색은 나쁨(정확한 평가를 위해 결과가 [-1:1]로 조정되었습니다. 정확한 평가를 위해 함수 자체를 호출한 결과를 참조하십시오. cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable ), 등.) X3, X4, X5, X19, X20은 거의 모든 방법으로 잘 평가되고 있음을 알 수 있습니다. 처음에는 해당 방법을 사용한 다음 더 추가/제거를 시도할 수 있습니다.
그러나 래틀 모델은 Rat_DF2에 대한 5개의 예측 변수로 테스트를 통과하지 못했고 다시 기적이 일어나지 않았습니다. 저것들. 나머지 예측 변수가 있더라도 모델 매개변수를 선택하고 교차 검증을 수행하고 예측 변수를 직접 추가/제거해야 합니다.
Vladimir 기사의 데이터에 대해 CORElearn에서도 동일한 작업을 수행했습니다. 열의 평균(하단 행 Average)을 계산하고 이를 기준으로 정렬합니다. 이렇게 하면 전반적인 중요성을 더 쉽게 인식할 수 있습니다.
1.6분을 계산했으며 37개의 알고리즘이 이를 해결했습니다. 속도는 Caret(16분)보다 훨씬 우수하며 비슷한 결과를 보입니다.
열의 평균(하단 행 Average)을 계산하고 이를 기준으로 정렬합니다. 이렇게 하면 전반적인 중요성을 더 쉽게 인식할 수 있습니다.
1.6분을 계산했으며 37개의 알고리즘이 이를 해결했습니다.
글쎄, 결과는 무엇입니까? 그들은 예측 변수의 중요성에 대한 질문에 대답했습니다. 그렇지 않으면 이 그림 중 몇 개를 이해하지 못합니다.
저에게는 이제 모델을 만들고 선택할 때 전혀 문제가 없으며 예측 변수를 함께 선택한 다음 10개의 모델을 만든 다음 상호 정보와 가장 잘 맞는 모델을 선택합니다. 그리고 당신은 그것이 어떻게 이루어졌는지 알고 있습니다. 마인드 퍼즐!!! 좋아, 누가 결정 잘했어!!!!!
나는 구리에서 그러한 모델 세트를 얻을 수있었습니다. 그리고 실제로 vporos: 어떤 모델이 작동하고 있으며 그 이유는????????
오히려 그들은 모두 일꾼이지만 그 중 한 명만 득점할 수 있습니다. 그리고 이유를 설명???
글쎄, 결과는 무엇입니까? 그들은 예측 변수의 중요성에 대한 질문에 대답했습니다. 그렇지 않으면 이 그림 중 일부를 이해하지 못합니다.
저에게는 이제 모델을 만들고 선택할 때 전혀 문제가 없으며 예측 변수를 함께 선택한 다음 10개의 모델을 만든 다음 상호 정보와 가장 잘 맞는 모델을 선택합니다. 그리고 당신은 그것이 어떻게 이루어졌는지 알고 있습니다. 마인드 퍼즐!!! 좋아, 누가 결정 잘했어!!!!!
나는 구리에서 그러한 모델 세트를 얻을 수있었습니다. 그리고 실제로 vporos: 어떤 모델이 작동하고 있으며 그 이유는????????
오히려 그들은 모두 일꾼이지만 그 중 한 명만 득점할 수 있습니다. 그리고 이유를 설명???
2개 수업
코어 1개 로드됨
rfeControl = rfeControl(number = 1,repeats = 1) 설정 - 시간을 10-15분으로 줄였습니다. 결과 변경 - 2쌍의 예측 변수가 위치를 변경했지만 일반적으로 기본적으로 원래대로 보입니다.
글쎄요, 여기 한 코어에서 10분이 제 2 x 4이고 2분이 기억나지 않습니다.
나는 몇 시간 동안 무언가를 기다리지 않습니다. 10-15 분이 작동하지 않으면 문제가 발생하고 더 많은 시간을 보내더라도 아무런 이점이 없습니다. 몇 시간 동안 지속되는 모델을 구축할 때의 최적화는 모델이 최소한으로 거칠고 어떤 경우에도 최대한 정확해야 한다고 말하는 모델링 이데올로기에 대한 완전한 오해입니다.
이제 예측 변수의 선택에 대해 설명합니다.
왜 했고 왜 그랬어요? 어떤 문제를 해결하려고 합니까?
선택에서 가장 중요한 것은 과적합 문제를 해결하려는 시도입니다. 모델이 재교육되었습니까? 그렇지 않은 경우 선택은 더 적은 수의 예측 변수를 희생시키면서 학습 속도를 높일 수 있습니다. 그러나 주요 구성 요소를 분리하여 양을 줄이는 것이 훨씬 더 효율적입니다. 그것들은 아무 영향도 미치지 않지만 예측 변수의 수를 10배 정도 줄일 수 있으므로 모델 피팅 속도를 높일 수 있습니다.
시작하려면 왜 필요합니까?
예측 변수를 필터링하기 위한 또 다른 흥미로운 패키지를 찾았습니다. FSelector라고 합니다. 엔트로피 사용을 포함하여 예측 변수를 제거하기 위한 약 12가지 방법을 제공합니다.
예측자와 대상이 포함된 파일은 여기에서 가져왔습니다 - https://www.mql5.com/ru/forum/86386/page6#comment_2534058
마지막으로 각 방법에 따른 예측변수의 추정치를 그래프로 보여주었어요~
파란색은 좋음, 빨간색은 나쁨(정확한 평가를 위해 결과가 [-1:1]로 조정되었습니다. 정확한 평가를 위해 함수 자체를 호출한 결과를 참조하십시오. cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable ), 등.)
X3, X4, X5, X19, X20은 거의 모든 방법으로 잘 평가되고 있음을 알 수 있습니다. 처음에는 해당 방법을 사용한 다음 더 추가/제거를 시도할 수 있습니다.
그러나 래틀 모델은 Rat_DF2에 대한 5개의 예측 변수로 테스트를 통과하지 못했고 다시 기적이 일어나지 않았습니다. 저것들. 나머지 예측 변수가 있더라도 모델 매개변수를 선택하고 교차 검증을 수행하고 예측 변수를 직접 추가/제거해야 합니다.
Vladimir 기사의 데이터에 대해 CORElearn에서도 동일한 작업을 수행했습니다.
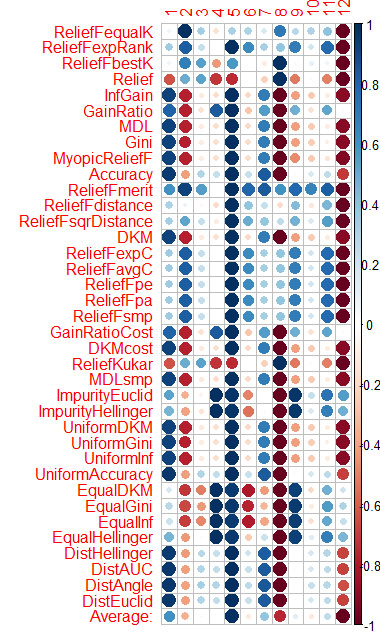
열의 평균(하단 행 Average)을 계산하고 이를 기준으로 정렬합니다. 이렇게 하면 전반적인 중요성을 더 쉽게 인식할 수 있습니다.
1.6분을 계산했으며 37개의 알고리즘이 이를 해결했습니다. 속도는 Caret(16분)보다 훨씬 우수하며 비슷한 결과를 보입니다.
Vladimir 기사의 데이터에 대해 CORElearn에서도 동일한 작업을 수행했습니다.
열의 평균(하단 행 Average)을 계산하고 이를 기준으로 정렬합니다. 이렇게 하면 전반적인 중요성을 더 쉽게 인식할 수 있습니다.
1.6분을 계산했으며 37개의 알고리즘이 이를 해결했습니다.
글쎄, 결과는 무엇입니까? 그들은 예측 변수의 중요성에 대한 질문에 대답했습니다. 그렇지 않으면 이 그림 중 몇 개를 이해하지 못합니다.
저에게는 이제 모델을 만들고 선택할 때 전혀 문제가 없으며 예측 변수를 함께 선택한 다음 10개의 모델을 만든 다음 상호 정보와 가장 잘 맞는 모델을 선택합니다. 그리고 당신은 그것이 어떻게 이루어졌는지 알고 있습니다. 마인드 퍼즐!!! 좋아, 누가 결정 잘했어!!!!!
나는 구리에서 그러한 모델 세트를 얻을 수있었습니다. 그리고 실제로 vporos: 어떤 모델이 작동하고 있으며 그 이유는????????
오히려 그들은 모두 일꾼이지만 그 중 한 명만 득점할 수 있습니다. 그리고 이유를 설명???
글쎄, 결과는 무엇입니까? 그들은 예측 변수의 중요성에 대한 질문에 대답했습니다. 그렇지 않으면 이 그림 중 일부를 이해하지 못합니다.
저에게는 이제 모델을 만들고 선택할 때 전혀 문제가 없으며 예측 변수를 함께 선택한 다음 10개의 모델을 만든 다음 상호 정보와 가장 잘 맞는 모델을 선택합니다. 그리고 당신은 그것이 어떻게 이루어졌는지 알고 있습니다. 마인드 퍼즐!!! 좋아, 누가 결정 잘했어!!!!!
나는 구리에서 그러한 모델 세트를 얻을 수있었습니다. 그리고 실제로 vporos: 어떤 모델이 작동하고 있으며 그 이유는????????
오히려 그들은 모두 일꾼이지만 그 중 한 명만 득점할 수 있습니다. 그리고 이유를 설명???
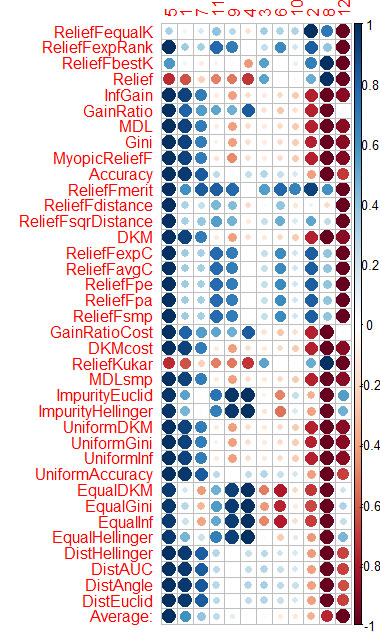
Vtreat는 예측자를 매우 유사하게 정렬합니다(처음에 중요).
5 1 7 11 4 10 3 9 6 2 12 8
다음은 CORElearn의 평균 정렬입니다.
5 1 7 11 9 4 3 6 10 2 8 12
더 이상 예측자를 선택 하기 위한 패키지로 귀찮게 하지 않을 것이라고 생각합니다.
따라서 Vtreat는 충분합니다. 예측 변수의 상호 작용이 고려되지 않는 한. 아마도 CORElearn에도 있을 것입니다.
나는 당신이 시장 역사의 일부에 대한 예측 변수의 중요성을 계속 선택하는 것을 볼 때 눈물을 흘립니다. 무엇 때문에? 이것은 욕설 통계입니다. 행동 양식
실제로 NN에 예측변수 2번을 제출하면 오차가 30%에서 거의 50%까지 올라가는 것을 확인했다.
OOS에서 오류는 어떻게 변경됩니까?
OOS에서 오류는 어떻게 변경됩니까?
비슷하게. Vladimir의 기사에서와 같이 데이터는 거기에서 가져온 것입니다.
다른 OOS에 있다면?
실제로 NN에 예측변수 2번을 제출하면 오차가 30%에서 거의 50%까지 올라가는 것을 확인했다.
예측 변수에 침을 뱉고 NN 정규화 시계열 에 적용합니다. NS는 자체적으로 예측 변수를 찾습니다. +1-2개의 레이어가 있으며 여기에 여러분을 위한 예측 변수가 있습니다.