기고글 토론 "지수 평활을 이용한 시계열 예측"
코드의 미로를 헤쳐 나갈 수는 없지만 비교하고 싶습니다.
초기 견적
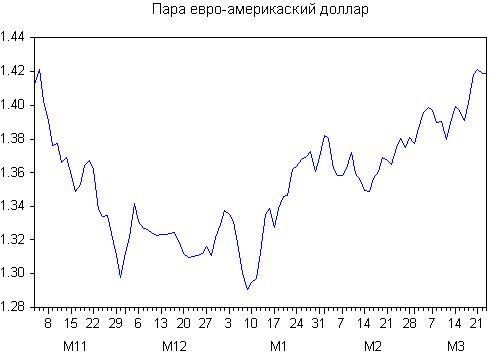
다음과 같은 스무딩 변형이 있습니다:
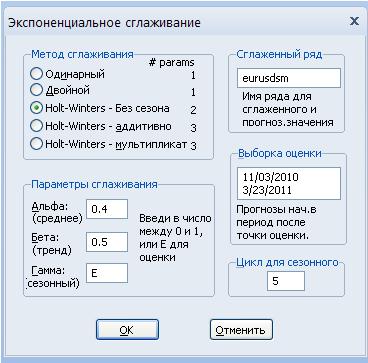
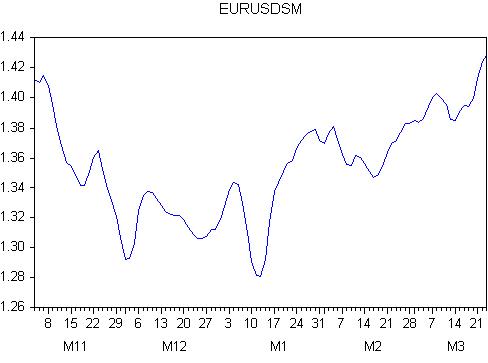
스무딩 결과
회귀 방정식:
EURUSD = C(1)*URUSDSM(-1) + C(2)*TEND + C(3)
회귀 방정식 추정
| 변수 | 계수 | Stand.osh. | t-통계 | 확률 |
| EURUSDSM(-1) | 0.759607 | 0.049127 | 15.46225 | 0.0000 |
| REND | 0.000207 | 5.79E-05 | 3.577804 | 0.0005 |
| C | 0.314884 | 0.065276 | 4.823886 | 0.0000 |
R-제곱 = 0.788273
회귀 표준 오차 = 0.015172
얻은 수치에서 다음과 같은 사실을 알 수 있습니다:
모든 회귀 계수가 유의미합니다(0과 같을 확률은 0과 같습니다).
회귀가 분산의 78 %를 설명한다는 다소 높은 (그러나 그다지 높지는 않은) R- 제곱.
표준 오차는 151핍입니다. 엄청난 수치입니다.
결과 수치를 신뢰할 수 있을까요?
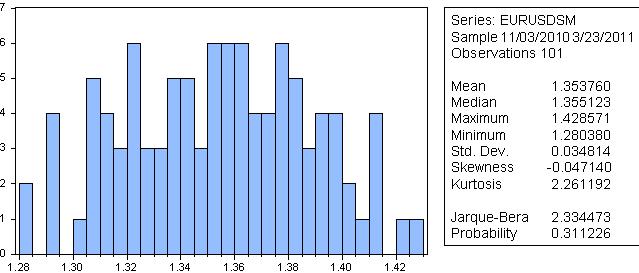
Jarque-Bera에 따르면 평활화 계열이 정규 분포를 가질 확률은 31%이기 때문에 저는 그렇게 생각하지 않습니다.
예측을 해 봅시다:
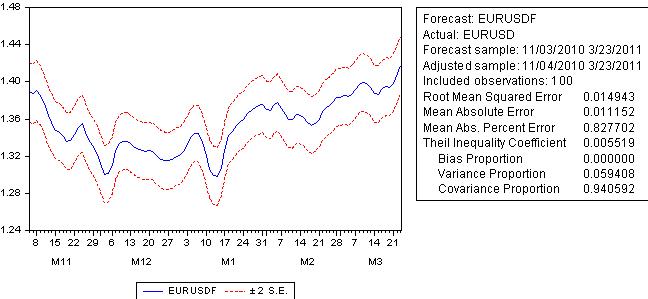
예측 오차가 회귀 오차에 크게 뒤지지 않고 100핍을 초과합니다.
예측 오차의 그래프를 살펴봅시다:
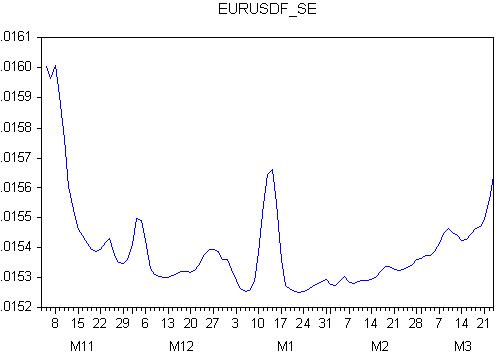
음, 이것은 완전한 마무리입니다: 오차는 가변적이며, 이는 예측의 미래 동작을 알 수 없음을 의미합니다!
그 이유를 알아보기 위해 회귀 방정식 계수의 상관 관계를 살펴봅시다:
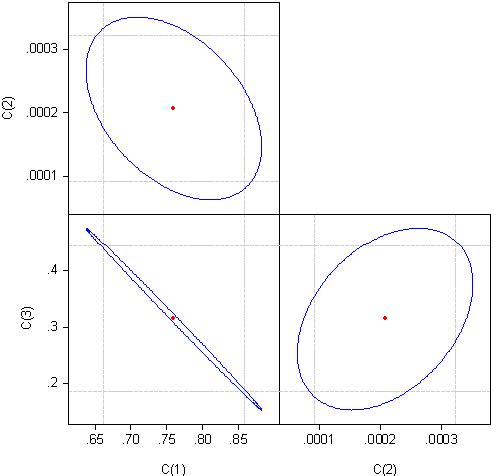
계수 c(1)과 c(3)은 거의 100% 상관관계가 있다고 볼 수 있습니다.
결론은 예측에 지수 평활을 사용할 수 없다는 것입니다.
결과가 다른 이유는 무엇일까요?
여러분이 찾은 최적의 매개변수는 사소한 맞춤에 지나지 않는다는 것이 분명합니다. 회귀 자체는 절망적이며 그 계수는 상관 관계가 있습니다.
여러분이 찾은 최적의 매개 변수는 사소한 피팅에 지나지 않는다는 것이 분명합니다. 회귀 자체는 절망적이며 그 안에있는 계수는 상관 관계가 있습니다.
기사에 관심을 가져 주셔서 감사합니다.
무슨 뜻인지 명확히 설명해 주시겠어요? 수렴하지 않는 결과는 무엇이며 최적의 매개 변수는 무엇인가요?
무슨 뜻인지 명확히 설명해 주시겠어요?
죄송합니다만, 사용할 수 있다고 말씀하셨지만 제 결론은 사용할 수 없다는 것입니다.
제 결론은 예측에 지수 평활을 사용할 수 없다는 것입니다.
질문의 내용은 무엇이며 그 이유는 무엇인가요?
대답을 해드리고 싶지만 최소한 질문이 무엇인지 알아야 합니다. 그렇지 않으면 추측하고 상상해야 할 것입니다.
다시 설명해 드리겠습니다.
지수 평활화 모델을 사용하여 유로USD 쌍, 시세 또는 전혀 예측할 수 없습니까?
추신.
텍스트에 "회귀 방정식 :eurusd = c(1)*eurusdsm(-1) + c(2)*trend + c(3)"가 있습니다. 왜 회귀, 기사는 지수 평활화 모델에 관한 것이며 c(3) 대신에 일부 분포와 분산을 가진 무작위 변수가있는 다른 모델이 있습니까?
텍스트에서: "회귀 방정식:eurusd = c(1)*eurusdsm(-1) + c(2)*trend + c(3)". 왜 회귀, 기사는 지수 평활화 모델에 관한 것이고, 다른 모델이 있으며, c(3) 대신 일부 분포와 분산이있는 무작위 변수가 있습니까?
장님과 청각 장애인에게 말하는 것은 효과가 없습니다. 연기합시다.
좋은 기사를 다시 한 번 축하드립니다.
새로운 기고글 지수 평활을 이용한 시계열 예측 가 게재되었습니다:
이 문서를 통해 시계열의 단기 예측에 사용되는 지수 평활 모형을 독자분들이 익숙해지실 수 있도록 설명해드릴 것입니다. 또한 예측 결과의 최적화 및 추정과 관련된 주제를 다루고, 스크립트와 인디케이터를 예시삼아 몇 가지 제공해드릴 것입니다. 이 문서는 지수 평활 모형에 기초한 예측 원칙을 처음 숙지하는 데 유용할 것입니다.
그림 1은 시험 시퀀스 USDJPY M1의 파편에 대한 1단계 선행 예측 오차의 제곱합 대 알파 계수 값의 그림을 보여줍니다.
1번 그림. 단순 지수 평활
결과 그림의 최소값은 거의 식별되지 않으며 약 0.8의 알파 값에 가깝습니다. 그러나 이러한 그림은 단순 지수 평활과 관련하여 항상 그렇지는 않습니다. 이 문서에 사용된 테스트 시퀀스에 대한 최적의 알파 값을 얻으려고 시도할 때에, 통일성을 갖추지 못한 그림을 얻을 때가 제대로 된 그림을 얻을 때보다 많습니다.
작성자: Victor