記事"Growing Neural Gas: MQL5への実装"についてのディスカッション
見た目はクールだ :)
でも、それが何なのか、どうやって使うのか、まだわからないんだ :)
見た目はクールだ :)
でも、それが何なのか、どう使うのかは、もっと解明する必要があるね :)
は、次元削減やクラスタリング、確率的ネットワーク、その他多くのオプションのために、最初の隠れ層として使用することができます。
資料をありがとう!
暇を見つけて勉強してみます :)
興味深いネットワーキング・メソッドに関する新しい記事をありがとう。文献を調べれば、数百はないにしても数十はある。しかし、トレーダーにとっての問題は、ツールがないことではなく、ツールを正しく使うことにある。Expert Advisorでこの手法を使用した例が掲載されていれば、さらに興味深い記事になるだろう。

興味深いネットワーキング・メソッドに関する新しい記事をありがとう。文献を調べれば、数百はないにしても数十はある。しかし、トレーダーにとっての問題は、ツールがないことではなく、ツールを正しく使うことにある。この方法をExpert Advisorで使用する例が掲載されていれば、この記事はさらに興味深いものになるだろう。
1.記事が良い。アクセスしやすい方法で提示されており、コードも複雑ではない。
2.記事の欠点は、ネットワークの入力データについて全く何も述べられていないことである。 期間/指標データの相場ベクトル、価格乖離のベクトル、正規化された相場など、何が入力されるかについて少し書いてもよかっただろう。アルゴリズムを実際に使用するためには、入力データとその準備の問題が鍵となります。 x[i]=price[i+1]-price[i]。
さらに、事前に入力ベクトルを正規化(x_normal[i]=x[i]/M)することができ、その場合、対象期間の価格の最大偏差をMとして使用することができる(以下、簡潔にするため、変数宣言は 書かない):
M=x[ArrayMaximum(x)]-x[ArrayMinimum(x)];
この場合、すべての入力ベクトルは一辺[-0.5,0.5]の単位超立方体に位置することになり、クラスタリングの質が大幅に向上します。また、Mとして、標準正規偏差または期間中の相場の相対偏差に関する他の平均化変数を使用することもできます。
3.この論文では、ニューロン重みベクトルと入力ベクトルの間の距離として、差のノルムの2乗を使用することを提案している:
for(i=0, sum=0; i<m; i++, sum+=Pow(x[i]-w[i],2));
私見では、この距離関数はこのクラスタリング・タスクには有効ではない。より効果的なのは、スカラー積または正規化スカラー積、つまり重みベクトルと入力ベクトルの間の角度の余弦を計算する関数である:
for(i=0, norma_x=0, norma_w=0; i<m; i++, norma_x+=x[i]*x[i], norma_w+=w[i]*w[i]); norma_x=sqrt(norma_x); norma_w=sqrt(norma_w); for(i=0, sum=0; i<m; i++, sum+=x[i]*w[i]); if(norma_x*norma_w!=0) sum=sum/(norma_x*norma_w);
そうすれば、各クラスタには、振動の方向によってではなく、振動の大きさによって互いに類似したベクトルがグループ化され、解決すべき問題の次元が大幅に削減され、学習済みニューラルネットワークの重み分布の特性が向上します。
4.ネットワークの学習の停止基準を定義する必要があることが正しく観察されている。 停止基準は、訓練されたネットワークの必要なクラスタ数を決定する必要がある。そしてそれ(数)は、解決すべき一般的な問題に依存する。もしタスクが1-2サンプル先の時系列を予測することであり、この目的のために、例えば多層ペルセプトロンを使用するのであれば、クラスタ数はペルセプトロンの入力層のニューロン数とあまり変わらないはずである。

一般に、最も詳細な分足チャート(10年*365日*24時間*60分)では、ヒストリーのバーの数は5,300,000を超えない。時間足チャートでは87,000本です。つまり、クラスター数が10000~20000を超える分類器を作成することは、各気配値のベクトルがそれぞれ独立したクラスターを持つ場合、"オーバートレーニング "効果のために正当化されないということです。
誤りの可能性があることをお詫びします。
1.ありがとう、あなたのためにベストを尽くしたよ:)
2.そうだね。しかし、まだインプットがある。これは別の大きな問題で、それだけで何十もの記事を書くことができる。
3.そして、ここでは完全に同意できない。正規化された入力の場合、スカラー積の比較はユークリッド規範の比較と等価です。
4.最大クラスタ数はすでにアルゴリズムのパラメータの1つです。
max_nodes
最後のNステップで勝者の誤差を測定し、何らかの方法でそのダイナミクスを評価する(例えば、回帰直線の傾きを測定する)。誤差がまだ減少しており、学習データがすでに底をついている場合は、ノイズを抑制するために平滑化を検討する価値がある。
3.式の同等性がどこにあるのか理解できない。ベクトル(x,w)/(|x||w|)間の角度の余弦の公式は、|x-w|^ 2と「あまり」似ていない。入力を正規化しても、これらの尺度の根本的な違いは変わらない:
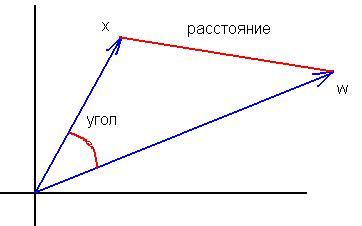
の等価性は、距離の最大値は常にスカラー積の最小値に対応し、逆もまた同様である。正規化ベクトルの場合の関係は相互に曖昧でなく単調であるため、距離の2乗を計算するか角度を計算するかは問題ではない。
こんにちは、アレックス、
このテーマについて明確な説明をありがとう。
例えば、最適なシグナルから将来の価格を再構築するための実用的なコードを共有することは可能でしょうか?
アイデアは次のとおりです:
1.入力(ソース):複数の通貨(18)
2.行き先:予測したい通貨の最適シグナル (pic: 2. Optimal_Signals)
3.ソースとデスティネーション間の神経接続を見つけ、取引でそれを爆発させる。

NN 再構築に関するもう一つの質問:
ランダム・サンプルの代わりに、写真2のように我々のサンプルを使うことは可能でしょうか?
私たちの脳は1秒もかからずに画像を再構成することができます。

ランダムに生成されたサンプルには意味も用途もないので、見ていてあまりおもしろくない。)

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 Growing Neural Gas: MQL5への実装 はパブリッシュされました:
本稿では、Growing neural gas (GNG)と呼ばれるクラスタの適用アルゴリズを実装するムMQL5プログラム開発方法をお見せしていきます。本稿は言語ドキュメンテーションを学習し、一定のプログラミングスキルがあり、神経情報科学分野の基礎知識がある方を対象としています。
作者: Alexey Subbotin