Indice Hearst - pagina 22
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
Sono confuso dal tuo "Non uno solo funzionante" dopo le parole "... e nella letteratura". Ci sono molti approcci diversi in letteratura che danno risultati leggermente diversi l'uno dall'altro, il che non è sorprendente dato che sono tutte stime. Tuttavia, è anche vero che più grande è il campione, più accurate dovrebbero essere queste stime e più "uguali" tra loro. Sono solo d'accordo che un algoritmo Hurst funzionante è difficile da trovare sui forum.
Per quanto riguarda cosa dare in pasto all'input dell'algoritmo, all'algoritmo non interessa. Alimenta il prezzo e otterrai qualcosa intorno a uno. Infatti, per l'essenza dell'algoritmo il prezzo ha una forte memoria a lungo termine, perché rimane relativamente lontano dai valori originali. Incrementi di prezzo dei mangimi - si ottiene qualcosa come 0,5, che ancora una volta è giustificato, perché i loro cambiamenti relativi sono grandi e quasi casuali. Alimentare le tendenze e/o i cicli - ottenere la persistenza. Il rumore generalmente riduce l'indice. Vedo che la domanda "il nostro prezzo è rumoroso o un prezzo di mercato equo?" non è l'oggetto dell'algoritmo di Hearst, quello è un altro campo.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
In generale, più lungo è, meglio è. Secondo l'algoritmo del libro di Peters, la lunghezza che ha il maggior numero di divisori interi è migliore.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Si distinguono due modelli:
1. Il processo ha un indice Hurst "stabile". Cioè, l'indice è una costante e non cambia nel tempo (durante tutta l'esistenza del processo). In questo caso, la sua definizione è presa come un minimo - un segmento statisticamente significativo - cioè un segmento che permette di fare una stima sicura della distribuzione del processo. O senza disturbare - il più grande segmento possibile.
2. L'indicatore è una qualche funzione, possibilmente molto complessa, possibilmente casuale. In questo caso, non ci sono criteri oggettivi per selezionare la lunghezza del BP. Stimare l'indice per il caso generale è impossibile sia nel dominio del tempo che in quello della frequenza, a meno che tu non sia un sensitivo.
È importante notare che l'analisi RS è uno dei metodi più crudi, la sua stima è sempre distorta e la dimensione del campione non aiuta in alcun modo. Per ottenere un calcolo corretto dell'indice di Hurst, usate una stima basata su wavelet (l'algoritmo può essere trovato in mathlab, per esempio).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
Hearst per il prezzo è ~1, ma qui cosa?
L'unica cosa che posso aiutare in questo caso è far notare che non c'è nessuna analisi Hearst o R/S nel file _hurst_classik. Lo scopo del nome "R/S" è di ridimensionare la riga. Ma il _hurst_classik che ha la pretesa di _RS_Analiz non fa ri-masterizzazione, ma, per esempio, prende banalmente la differenza tra i prezzi massimi e minimi.
Inoltre, l'analisi R/S, per raggiungere Hearst, calcola la pendenza della curva e per questo ha bisogno di molti punti sul piano log(R/S) - log(n) invece di uno. In questo miracolo _RS_Analiz non esiste.
Il punto principale del mio post era "identificare il modello BP", ma questo non ha catturato la tua attenzione.
Se stiamo parlando di modelli di classe ARFIMA o qualcosa del genere, non sono davvero interessato, perché questi modelli stanno crescendo "nakuya", il cui scopo è quello di raccogliere denaro per i fondi di investimento. Tale "scienza" è chiamata scienza del mobile perché è creata solo per il gusto di modificare la base scientifica per un risultato desiderato noto, di solito una previsione di prezzo.
Se stiamo parlando di modelli di classe ARFIMA o qualcosa del genere, non sono davvero interessato, perché questi modelli stanno crescendo "naqui", il cui scopo è quello di raccogliere denaro per i fondi di investimento. Tale "scienza" è chiamata scienza da gabinetto perché è creata solo per il gusto di adattare un quadro scientifico a un risultato deliberatamente desiderato, di solito una previsione di prezzo.
Non facciamo stime. Ora stiamo parlando di approcci che utilizzano il modello BP e non lo utilizzano affatto.AIUTARE A CALCOLARE L'INDICATORE HEARST!!!*
*piccola osservazione: come Peters
Ho letto tutto il thread dall'inizio alla fine: sì, non mi aspettavo che tutti, dai rispettati accademici ai semplici curiosi avessero una propria opinione su cosa sia Hirst, e su come debba essere contato e interpretato. Il più vicino all'originale è stato Eric Nyman nel suo articolo e nel suo libro. Ma... noi (in Russia per così dire) non abbiamo ancora uno strumento adeguato per generare grafici, che sono presentati nel libro di Peters.
Così, ho cercato di imitare il più possibile la sequenza di passi che Peters ha descritto nel suo primo libro: "Chaos and Order in the Capital World", per calcolare le statistiche R/S per lo S&P 500.
1. prendiamo i grafici mensili di S&P 500 dal 01.01.1950 al 01.07.1988.
2. Li carichiamo nel programma di analisi tecnica (io uso WealthLab e C#, qui e oltre userò il codice WL/C#)
3. Convertire i prezzi in rendimenti usando la formula del libro di Peters: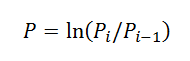
4. Lo stesso Peters non menziona che una volta calcolati i rendimenti, questi vengono riconvertiti in una serie accumulata: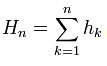 . Tuttavia, questo è ovvio, in base a quei valori di spread R/S che ha, inoltre la fonte lo afferma anche esplicitamente, cito: "Per ogni n naturale componiamo i valori (vedi formula precedente) e calcoliamo le seguenti caratteristiche numeriche della sottosequenza risultante".
. Tuttavia, questo è ovvio, in base a quei valori di spread R/S che ha, inoltre la fonte lo afferma anche esplicitamente, cito: "Per ogni n naturale componiamo i valori (vedi formula precedente) e calcoliamo le seguenti caratteristiche numeriche della sottosequenza risultante".
5. Dividiamo la serie risultante in k periodi, la lunghezza di ogni periodo essendo N da 6 a 231 mesi o osservazioni.
6. Ora c'è un punto importante. Se non si ottiene il numero intero di periodi (rimangono dati inutilizzati), vengono scartati. Tuttavia, se il resto è troppo grande (ad esempio 462 / 232 = 233 e 230 nel resto) si ottiene un valore errato. La mia comprensione è che Peters usa gli spostamenti, tuttavia questa è un'opzione molto complicata in termini di programmazione e semplicemente scarto il periodo se il suo residuo è maggiore di 6. Poiché i periodi adiacenti hanno quasi lo stesso valore R/S, questa è l'opzione corretta.
7. R viene poi calcolato con la formula:
8. R è diviso per la deviazione standard (calcolata dall'indicatore WL) e logaritmico: log10(R/S).
9. Il periodo corrente è logaritmato: log10(N);
10. Il rapporto ottenuto tra log10(R/S) e log10(N) viene scritto nel file.
Se l'ottimizzatore passa attraverso N da 6 (come Peters) a 231 (il numero minimo di esperimenti è 2), allora si ottiene una tabella di due colonne in doppia scala logaritmica: 1. periodo 2. valore di R/S.
Ora inizia la parte più interessante. Se tracciate questa tabella in Excel, verrà fuori quanto segue:
L'originale è presentato sulla destra. Come potete vedere, c'è qualche somiglianza, ma ancora non è lo stesso. In particolare, la cifra iniziale risulta essere leggermente sovrastimata (0,33 contro circa 0,31), e in secondo luogo, i valori finali iniziano improvvisamente a diminuire drasticamente, cosa che non dovrebbe essere il caso in linea di principio. Secondo il suo grafico, solo l'angolo di pendenza dovrebbe cambiare alla fine della serie, dicendoci che l'effetto memoria è limitato.
Finora mi sono fermato a questo punto. Non ho ancora deciso di applicare le statistiche U/V, data la sovrapposizione solo parziale con l'originale.
La conversione dei punteggi R/S in Hearst dà anche risultati un po' gonfiati. Se il punteggio di Hearst è: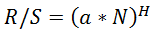 , poi usando la formula di Excel otteniamo LOG(HERST(10;B1);C1*0.5), dove B1 è il punteggio R/S corrente.
, poi usando la formula di Excel otteniamo LOG(HERST(10;B1);C1*0.5), dove B1 è il punteggio R/S corrente.
Di seguito è riportato il codice WL/C# che calcola le statistiche R/S:
p.s. Divertente, MQL4 non ha parole chiave come overide e using, ma la sintassi le evidenzia ancora:)Esiste un calcolo dell'indice di Hurst in Matcad (servono formule in forma discreta)?
Finora ho trovato solo questo
File con approcci all'analisi delle serie temporali in allegato. Ho preso queste formule da lì.
Mi dispiace, naturalmente.
È interessante? Guardando queste formule non vedo il senso di applicarle al Forex.
E' più facile disegnare una serie che descriva il forex. È già in circolazione, c'è gente che ha vinto premi Nobel per questo. Ma il risultato è molto mediato. Bisogna sempre stimare prima la media - l'errore, e poi cercare di togliere i minus dalla probabilità in relazione agli errori, e poi preoccuparsi.
Mi dispiace, naturalmente.
Allora, è interessante? Guardando le formule - non vedo proprio il senso di applicarle al forex.
E' più facile buttare su una serie da soli che descriva il forex. Esiste già, la gente ha preso un premio Nobel per questo. Ma il risultato è molto, molto mediocre. Prima è necessario stimare sempre la media - l'errore, cioè, poi cercare di tirare fuori i meno dalla probabilità in relazione agli errori, e poi preoccuparsi di questo.
Mi dispiace. Ma per il futuro, siamo d'accordo sul fatto di non postare inutili riflessioni in questo thread. Alcuni sono interessati al "forex row", altri alle statistiche di Hearst. Che ognuno abbia il proprio thread.
Sto pubblicando una tabella di tipo CSV in doppia scala logaritmica: stima R/S a periodo.