L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 1489
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Se qualcuno capisce HMM allora per favore mi aiuti a risolvere il problema, se il problema è risolvibile allora condividerò il graal)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
Se qualcuno capisce HMM allora per favore mi aiuti a risolvere il problema, se il problema è risolvibile allora condividerò il graal)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
bene, lo stato è markoviano, ma qual è il modello?
significa che avete bisogno di più punti per la finestra quadrata, almeno
e se viene alimentata una serie casuale, di che tipo di predizione oltre al 50\50 possiamo parlare?significa che avete bisogno di più punti per la finestra quadrata, come minimo
Te l'ho detto, ho anche preso diverse migliaia di punti
e se viene immessa una serie casuale, allora di quale tipo di previsione diversa dal 50/50 possiamo parlare?
Che differenza fa, i dati sono gli stessi, il modello è lo stesso
Prevedo nuovi dati usando l'intera funzione nel pacchetto (come in tutti gli esempi in rete...) i risultati sono ottimi
Uso lo stesso modello per prevedere gli stessi dati ma con finestra scorrevole e il risultato è diverso, inaccettabile.
Questa è la domanda: qual è il problema?Ti ho detto che ho anche preso diverse migliaia di punti
che differenza fa, i dati sono gli stessi, il modello è lo stesso
Prevedo nuovi dati utilizzando l'intera funzione nel pacchetto (come in tutti gli esempi sul web ...) i risultati sono grandi
Prevedo gli stessi dati con lo stesso modello ma con una finestra scorrevole e il risultato è diverso, inaccettabile.
Questa è la vera domanda: qual è il problema?Non so che tipo di modello e da dove prendi i tuoi stati. senza pacchetti, che senso ha?
Forse c'è un gcf che non dà alcuno stato casuale, ecco perché viene predetto nel 1° caso. Prova a cambiare seme sia per il treno che per il test per vedere che nel 1° caso è impossibile prevedere qualcosa, altrimenti non so come aiutare l'idea non è chiara
Le suddivisioni sono fatte secondo la probabilità di classificazione. Più precisamente, non per probabilità, ma per errore di classificazione. Perché tutto è noto sull'esercitazione di allenamento, e non abbiamo probabilità, ma una stima esatta.
Anche se ci sono diverse fi bre di separazione, cioè misure di impurità (campionamento a sinistra o a destra).
Mi riferivo alla distribuzione della precisione di classificazione sul campione, non al totale come si fa ora.
non è chiaro quale sia il modello e da dove prendi gli stati. Senza pacchetti, concettualmente che senso ha?
Forse c'è un gcp che non dà nessuna randomizzazione, ecco perché è previsto nel 1° caso. Prova a cambiare seme sia per il treno che per il test per vedere se è impossibile prevedere anche nel primo caso, altrimenti non so come aiutare l'idea.
Ecco il file, ci sono i prezzi e due colonne con i predittori "data1" e "data2".
Addestrate HMM con solo due stati(su una traccia di dati senza insegnante) per queste due colonne ("dati1" e "dati2") in Python o come volete. Non toccate affatto il prezzo, fatelo solo per la visualizzazione
Poi si prende l'algoritmo di Viterbi e si arriva a un (test dei dati).
otteniamo due stati, dovrebbe apparire così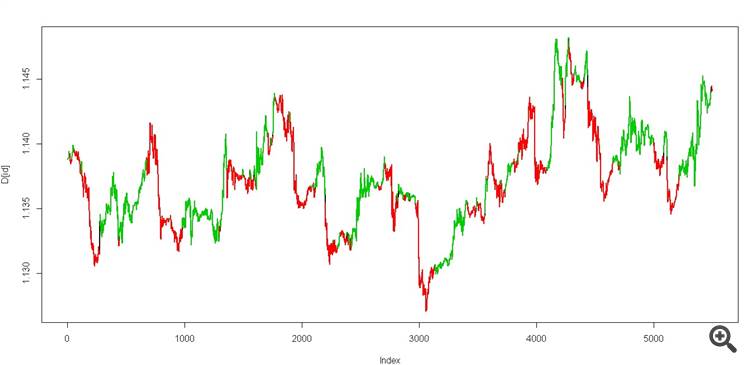
è un vero graal))
E poi provare a calcolare lo stesso Viterbi nella finestra scorrevole usando gli stessi dati
Ecco un file con prezzi e due colonne con predittori "data1" e "data2".
Alleni HMM con solo due stati(su una traccia di dati) usando queste due colonne ("data1" e "data2") in Python o in qualsiasi altro modo tu voglia. Non tocchi affatto il prezzo, lo usi solo per la visualizzazione.
Poi si prende l'algoritmo di Viterbi e (test dei dati)
otteniamo due stati, dovrebbe apparire così
È un vero e proprio graal).
E poi provare lo stesso calcolo di Viterbi nella finestra scorrevole sugli stessi dati
Senk, lo guarderò più tardi, ti farò sapere, perché sto lavorando con un markoviano.
Senk, controllerò più tardi e ti farò sapere, dato che io stesso sto lavorando con i Markov.
qualche fortuna?
qualche fortuna?
Non sto ancora cercando, giorno di riposo ) Ti farò sapere quando avrò tempo, più tardi in settimana intendo
guardando i pacchetti finora. Penso che si adatti ahttps://hmmlearn.readthedocs.io/en/latest/tutorial.html