L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 1180
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Ivan Negreshniy, non capisco, ho creato il modello in CatBoost, ma come dovrebbe essere collegato, è il ponte/canale da EA a python, dove i valori del predittore saranno passati, e nella direzione opposta il risultato dei calcoli sarà ricevuto - una classe concreta?
Per quanto ho capito, CatBoost permette di scaricare un codice del modello che non capisco, ma lo allegherò per la stima del professionista, non è possibile integrarlo in qualche modo in MQL e non usare python allora? E, CatBoost hanno librerie in C++, non possono farle funzionare in MQL e non usano python e comandi da console?
Ciò che non è chiaro, il ponte è necessario per l'automazione end-to-end del lavoro con i dati e i modelli direttamente da Expert Advisor, compresa la creazione, l'impostazione, la formazione, ecc. E ciò che CatBoost scarica nei file è la serializzazione di un particolare modello, che può essere utilizzato solo per i calcoli.
Naturalmente, è possibile creare un EA basato su questi file nell'editor, ma non sarà molto diverso da un normale EA con una logica rigida, e se questo è l'obiettivo, IMHO, è molto più facile da raggiungere attraverso la formazione utilizzando modelli, che ho suggerito. https://www.mql5.com/ru/forum/270216
Dato che tutto lì è addestrato e generato automaticamente, e il codice di ogni albero è convertito in una funzione separata e logica, che può essere più facile da analizzare e più veloce da eseguire, se lo completate, possiamo confrontare più tardi.
Un lavoro impegnativo per me, in primo luogo.
La maggior parte dei predittori sono indicatori raggruppati e inseriti nell'ATR giornaliero. Il resto del lavoro sulle serie temporali sono predittori di caratterizzazione.
Ho due domande
1) Si prega di spiegare cosa significa: un mucchio diindicatori e il loro inserimento nel diario ATR.
2) Perché catbust? Sei sicuro che sia meglio di altri boost?
Ciò che non è chiaro qui, il ponte è necessario per l'automazione end-to-end di lavorare con dati e modelli direttamente dall'EA, compresa la creazione, la configurazione, la formazione, ecc,
Capisco, cioè è principalmente la capacità di creare la propria interfaccia per lavorare con la libreria MoD, giusto? Questo equivale al fatto che ora ho intenzione di fare la stessa interfaccia ma attraverso l'attivazione di un file exe e l'immissione di comandi in esso. In generale, sì, è interessante farlo attraverso python, ma non ho queste conoscenze, purtroppo.
e ciò che CatBoost scarica nei file è la serializzazione di un modello specifico, che può essere utilizzato solo per i calcoli.
Naturalmente, possiamo creare un EA basato su questi file nell'editor, ma non sarà molto diverso da un normale EA con una logica rigida, e se questo è l'obiettivo, allora IMHO, è molto più facile da raggiungere attraverso la formazione con l'aiuto di modelli, che ho suggerito. https://www. mql5.com/ru/forum/270216
Se capisci questo codice, forse puoi dirmi come tradurlo in forma leggibile, per esempio dando ad ogni regola una descrizione finita, come faccio per le foglie dopo aver elaborato i modelli da R
Non riesco proprio a capire l'algoritmo di crittografia in questo codice - puoi fare la sua descrizione/interprete (magari a pagamento)?
E se questo è l'obiettivo, IMHO, è molto più facile raggiungerlo attraverso l'apprendimento di modelli, che ho suggerito. https://www.mql5.com/ru/forum/270216
Poiché lì tutto è addestrato e generato automaticamente, e il codice di ciascuno degli alberi è convertito in una funzione separata e logica, che può essere più facile nell'analisi e più veloce nell'esecuzione, se la completate, possiamo confrontarla più tardi.
L'obiettivo non è solo ottenere un modello, ma ottenere delle foglie, valutarle e poi generare nuovi modelli basati su queste foglie.
Stavo leggendo quell'argomento e non capisco bene, il processo di costruzione automatica delle reti è stato creato sulla base di indicatori nudi e markup, le informazioni vengono trasferite al template, mentre io ho la post-elaborazione degli indicatori, in più uso alcuni dei miei indicatori, che non voglio mettere alla luce, quindi risulta che il metodo non è disponibile, e ancora - non si può ottenere foglie da esso...
Ho due domande
1) Spiegare cosa significaraggruppare gli indicatori e inserirli nell'ATR giornaliero
2) Perché catbust? Sei sicuro che sia meglio di altri boost? o impalcature
1. questa è la mia visione del mercato, cioè il prezzo ha un piano di movimento, che è definito da ATR all'inizio della giornata, poi a seconda degli ostacoli (livelli di resistenza (livelli di prendere/vedere decisioni di trading da parte dei partecipanti al mercato), che sono, compresi gli indicatori), questo piano viene attuato o meno. I predittori descrivono questi ostacoli rispetto al piano di movimento. Così, questo è quello che sembra graficamente - una griglia lungo la gamma ATR con diversi indicatori all'interno
Screenshot della piattaforma MetaTrader
Si-9.18, M1, 2018.08.30
JSC '''Otkritie Broker'', MetaTrader 5, Real
Per la memoria
2. CatBoost - mi ha appena aiutato a configurarlo. Inoltre funziona chiaramente più velocemente del mio precedente approccio di creare modelli in R e allo stesso tempo era più efficiente, c'è documentazione e comandi attraverso DOS :) Rispetto ad altri strumenti, per esempio Deductor Studio, è più stabile e i modelli escono meglio, in più quest'ultimo è a pagamento, qui è tutto gratuito.
Ti potrebbe interessare, mi sono imbattuto in
Voglio fare un sistema sull'ottimizzazione degli alberi, più precisamente costruendo alberi con l'ottimizzatore... è un argomento interessante, ma non so da dove cominciare :))
https://explained.ai/
Grazie per la preoccupazione!
La barriera linguistica rende la lettura straziante, e i traduttori rendono il testo o stupido o divertente... ahimè.
tradurre una parola alla volta, utilizzando il plugin di google translator per chrome.
Uso il pluginImTranslator in chrome, funziona bene quando si traduce un paragrafo in una volta, quando si selezionano le parole e si fa clic con il tasto destro del mouse sul menu contestuale
non c'è bisogno di cliccare su google
Che tipo di plugin è? Funzionava in Chrome, poi ha smesso, e non so come impostarlo.
Capisco, cioè è prima di tutto un'opportunità per creare la propria interfaccia per lavorare con la libreria MoD, giusto? Questo equivale al fatto che ora ho intenzione di fare la stessa interfaccia ma attraverso l'attivazione di un file exe e l'immissione di comandi in esso. In generale, sì, è interessante farlo via python, ma non ho queste conoscenze, purtroppo.
Se capite questo codice, potete dirmi come tradurlo in forma leggibile, per esempio dando ad ogni regola una descrizione finita, per esempio, come faccio per le foglie dopo aver elaborato i modelli da R
Non riesco proprio a capire l'algoritmo di crittografia in questo codice - puoi fare la sua descrizione/interprete (magari a pagamento)?
L'obiettivo non è solo ottenere un modello, ma ottenere delle foglie, valutarle e poi generare nuovi modelli basati su quelle foglie.
Ho letto quel tema, ma non lo capisco, il processo di costruzione automatica delle reti è stato creato sulla base di indicatori nudi e markup, le informazioni vengono trasferite al template, nel mio caso c'è la post elaborazione degli indicatori, in più uso alcuni dei miei indicatori, che non voglio rendere pubblici, quindi risulta che il metodo non è disponibile, e ancora - non si può ottenere foglie da esso...
Non capisco perché può avere bisogno di editing manuale spaccature e foglie decidendo gli alberi, sì ho tutta la ramificazione automaticamente convertito in un operatore logico, ma onestamente non ricordo che io stesso ho mai corretto.
E in generale vale la pena scavare il codice CatBoost, come faccio a saperlo con certezza.
Per esempio, ho messo sopra test su python la mia rete neurale con apprendimento tramite tabella di moltiplicazione per due, e ora l'ho presa per testare alberi e foreste (DecisionTree, RandomForest, CatBoost)
ed ecco il risultato - ovviamente non è a favore di CatBoost, come due volte due fa zero cinque...:)
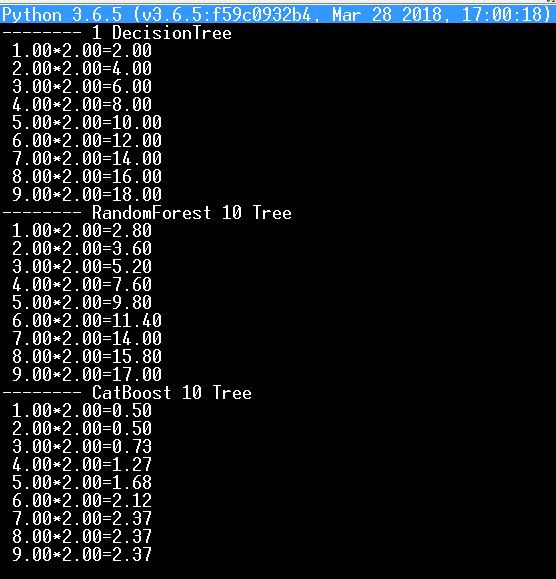
è vero che se si prendono migliaia di alberi, i risultati migliorano.Non capisco perché sia necessaria la modifica manuale delle divisioni e delle foglie degli alberi decisionali, sì, ho tutti i rami convertiti automaticamente in operatori logici, ma francamente non ricordo di averli mai corretti io stesso.
E in generale vale la pena scavare il codice CatBoost, come faccio a saperlo con certezza.
Per esempio, ho messo sopra test su python la mia rete neurale con apprendimento tramite tabella di moltiplicazione per due, e ora l'ho presa per testare alberi e foreste (DecisionTree, RandomForest, CatBoost)
ed ecco il risultato - chiaramente non è a favore di CatBoost, come due volte due fa zero cinque...:)
Dai, è impossibile che la foresta o il boosting non possano far fronte alla tabella di moltiplicazione
Impossibile, non c'è modo che una foresta o il boosting non possano gestire la tabella di moltiplicazione.