Que mettre à l'entrée du réseau neuronal ? Vos idées... - page 52
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Si vous regardez l'image, oui, c'est chaud et doux, mais dans le code, c'est très bien.
Les parenthèses de l'image ne sont pas correctes. Cela devrait être comme ceci.
Ola ke tal. Je me suis dit que j'allais faire part de mes idées.
Mon dernier modèle consiste à collecter les prix normalisés de 10 symboles et à former ainsi un réseau de récurrence. En entrée, 20 barres du mois, de la semaine et du jour.
C'est l'image que j'obtiens. La différence par rapport à l'entraînement séparé est que le profit total est 3 fois moins élevé et le drawdown.... wow, le drawdown sur la période de contrôle est d'à peine 1%.
Il me semble que cela résout le problème de la rareté des données.
Ola ke tal. Je me suis dit que je devais faire part de mes idées.
Mon dernier modèle consiste à collecter les prix normalisés de 10 symboles et à former ainsi un réseau de récurrence. Il y a 20 barres du mois, de la semaine et du jour par entrée.
C'est l'image que j'obtiens. La différence par rapport à l'entraînement séparé est que le profit total est 3 fois moins élevé et le drawdown.... wow, le drawdown sur la période de contrôle est d'à peine 1%.
Il me semble que cela résout le problème de la rareté des données.
Je pense que vous avez un très haut niveau de connaissance du sujet, mais je crains de ne rien comprendre.
Je crains de ne rien comprendre. Dites-moi ce qu'est cette beauté sur le graphique : s'agit-il de Python ? d'une architecture LSTM ?
Est-il possible d'afficher une telle chose sur MT5 ?
prix normalisés de 10 symboles
Ici aussi, comment les prix ont été normalisés. Qu'est-ce que "ante" En général, tout ce qui n'est pas un secret commercial, merci de le partager)
Je pense que vous avez une très grande maîtrise du sujet.
Je crains de ne rien comprendre. Dites-moi ce qu'est cette beauté sur le graphique : s'agit-il de Python ? d'une architecture LSTM ?
Est-il possible d'afficher une telle chose sur MT5 ?
Ici aussi, comment les prix sont-ils normalisés ? Qu'est-ce que "ante" ? En général, tout ce qui n'est pas un secret commercial, s'il vous plaît, partagez-le).
Bien sûr, c'est du python. En µl5 pour sélectionner des données sur une condition, il faut faire une énumération et tout ça iff iff iff iff iff iff. Et en python, une seule ligne suffit pour sélectionner les données selon n'importe quelle condition. Je ne parle pas de la rapidité du travail. C'est trop pratique. Mcl5 est nécessaire pour ouvrir des transactions avec un réseau tout fait.
La normalisation est la plus courante. Moins la moyenne, divisée par l'écart-type. Le secret de fabrication ici est la période de normalisation, il est important de l'aborder de manière à ce que les prix soient autour de zéro pendant 10 ans. Mais pas de manière à ce que les prix soient inférieurs à zéro au début de la période de 10 ans et supérieurs à zéro à la fin. Ce n'est pas ainsi que l'on peut comparer...
Deux périodes de test - ante et test. La période ante avant la formation est de 6 mois. C'est très pratique. L'ante est toujours là. Et le test, c'est le futur, il n'existe pas. C'est-à-dire qu'il existe, mais seulement dans le passé. Et dans le futur, il n'existe pas. C'est-à-dire qu'il n'existe pas.
Qu'est-ce qui est le plus important selon vous : l'architecture ou les données d'entrée ?
Qu'est-ce qui est le plus important selon vous : l'architecture ou les données d'entrée ?
Je pense que ce sont les données d'entrée. Ici, j'essaie 6 caractères, pas 10. Et je ne passe pas la période de contrôle août-décembre 2023. Séparément, c'est difficile aussi. Et un passage à 10 caractères peut être légitimement choisi sur la base des résultats de l'entraînement. Le réseau est toujours récurrent en 1 couche de 32 états, le lien complet n'est utilisé qu'une seule fois.
Quelques résumés :
Je me suis rendu compte que je venais de trouver un modèle algorithmique alors que j'examinais diverses données d'entrée, ce qui répondait en fait partiellement à la question de ma branche "Que donner en entrée au réseau neuronal ?". Mais le réseau neuronal s'est avéré inutile. Ni MLP, ni RNN, ni LSTM, ni BiLSTM, ni CNN, ni Q-learning, ni tout cela combiné et mélangé.
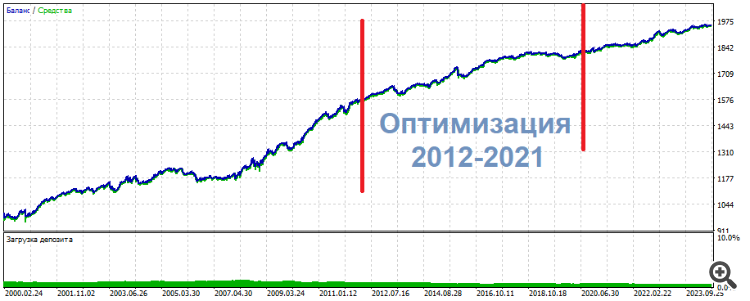
Dans l'une de ces expériences, j'ai optimisé 2 entrées sur 3 neurones. En conséquence, l'un des ensembles supérieurs a montré l'image suivante
* ******* **************
UPD Voici un autre ensemble, même chose : milieu - optimisation, résultats - sur les côtés. Presque la même chose, juste plus uniforme
**********************
Les trades ne sont pas des pips ou des scalps. Plutôt intraday.
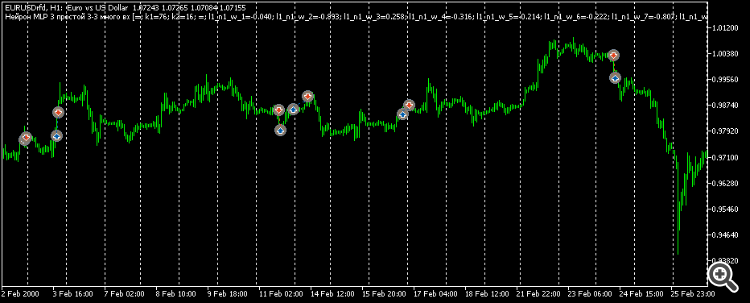
Ainsi, mes conclusions subjectives pour le moment :
Je n'ai jamais vu de ma vie de pires résultats qu'avec des indicateurs de lissage . C'est comme une personne voyante qui devient aveugle. Tout à l'heure, il pouvait voir une silhouette claire, et maintenant il ne peut pas comprendre ce qu'il y a - une tache dans ses yeux. Aucune information.
Mon avis, tel que je le vois
Le réseau neuronal n'est applicable qu'aux modèles stationnaires et statiques qui n'ont rien à voir avec la tarification.
Quel type de prétraitement, de normalisation faites-vous ? Avez-vous essayé la normalisation ?
I van Butko #: Le réseau neuronal se souvient du chemin. Pas plus que cela.
Essayez les transformateurs, on dit qu'ils sont bons pour vous....
I van Butko #: Les oscillateurs sont diaboliques !
Eh bien, tout n'est pas aussi clair. C'est juste que le NS est pratique pour travailler avec des fonctions continues, mais nous avons besoin d'une architecture qui fonctionne avec des fonctions par morceaux/intervalles, alors le NS sera capable de prendre les plages d'oscillateurs comme des informations significatives.
Quel type de prétraitement, de normalisation faites-vous ? Avez-vous essayé la normalisation ?
Essayez les transformateurs, il paraît qu'ils sont bons pour vous....
Eh bien, tout n'est pas si clair. C'est juste que NS est pratique pour travailler avec des fonctions continues, mais nous avons besoin d'une architecture qui fonctionne avec des fonctions par morceaux/intervalles, alors NS sera capable de prendre les gammes d'oscillateurs comme des informations significatives.
1. et quand comment : si la fenêtre de données, certains incréments, j'apporte la plage -1...1. je n'ai pas entendu parler de la normalisation 2.
Accepté, merci 3. Je suis d'accord, je n'ai pas la preuve complète du contraire.
C'est pourquoi j'écris depuis mon propre clocher, comme je le vois et l'imagine approximativement. Le simple lissage est un effacement de facto de l'information. Pas une généralisation. Un effacement tout court. Pensez à une photographie : dès que vous dégradez son contenu, l'information est irrémédiablement perdue. Et la restaurer avec l'IA est une démarche artistique, pas une restauration au sens propre. C'est un redécoupage arbitraire.
"Lissage : lorsqu'un nombre est le résultat de deux unités d'information indépendantes : le motif -1/1, par exemple, et le motif -6/6. La valeur moyenne de chaque unité sera la même, mais il y avait à l'origine deux motifs. Ils peuvent ou non signifier quelque chose, ils peuvent signifier des signaux opposés.
C'est là qu'interviennent les mashki, les oscillateurs, etc. qui ne font qu'effacer ou brouiller stupidement l'"image" initiale du marché. Et dans ce "brouillage", nous effrayons le SN, qui essaie sans cesse de fonctionner comme il le devrait. La généralisation et le lissage sont des phénomènes hétérogènes extrêmement rébarbatifs.
Quelques résumés :
Je me suis rendu compte que je venais de trouver un modèle algorithmique en examinant diverses données d'entrée, ce qui répondait en fait partiellement à la question de ma branche : "Que faut-il introduire dans le réseau neuronal ?" Mais le réseau neuronal s'est avéré inutile. Ni MLP, ni RNN, ni LSTM, ni BiLSTM, ni CNN, ni Q-learning, ni tout cela combiné et mélangé.
Dans l'une de ces expériences, j'ai optimisé 2 entrées sur 3 neurones. En conséquence, l'un des ensembles supérieurs a montré l'image suivante
* ******* **************
UPD Voici un autre ensemble, même chose : milieu - optimisation, résultats - sur les côtés. Presque la même chose, juste plus uniforme
**********************
Les trades ne sont ni des pips ni des scalps, mais plutôt de l'intraday.
Donc, mes conclusions subjectives pour le moment :
Je n'ai jamais vu de ma vie de pires résultats qu'avec des indicateurs de lissage . C'est comme une personne voyante qui devient aveugle. Tout à l'heure, il pouvait voir une silhouette claire, et maintenant il ne peut pas comprendre ce qu'il y a - une tache dans ses yeux. Aucune information.
Mon avis, tel que je le vois
pas un pépin faible.
Est-il temps de coudre des sacs ?