Optimisation des algorithmes.
joo
Pour commencer, je pense que vous devez apporter le code à :
1. Compilable.
2. Forme lisible.
3. Commentaire.
En principe, le sujet est intéressant et urgent.
joo
Pour commencer, je pense que vous devez apporter le code à :
1. Compilable.
2. Forme lisible.
3. Commentaire.
Ok.
Nous avons un tableau trié de nombres réels. Vous devez choisir une cellule du tableau avec une probabilité correspondant à la taille du secteur de la roulette imaginaire.
La série de nombres de test et leur probabilité théorique de tomber sont calculées dans Excel et présentées pour comparaison avec les résultats de l'algorithme dans l'image suivante :
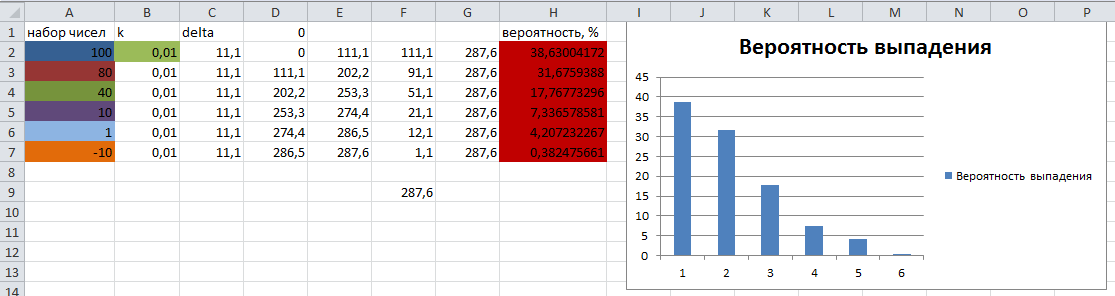
Le résultat de l'exécution de l'algorithme :
2012.04.04 21:35:12 Roulette (EURUSD,H1) h0 38618465 38.618465
2012.04.04 21:35:12 Roulette (EURUSD,H1) h1 31685360 31.68536
2012.04.04 21:35:12 Roulette (EURUSD,H1) h3 7.334754 7.334754
2012.04.04 21:35:12 Roulette (EURUSD,H1) h4 4205492 4.205492
2012.04.04 21:35:12 Roulette (EURUSD,H1) h5 385095 0.385095
2012.04.04 21:35:12 Roulette (EURUSD,H1) 12028 ms - Temps d'exécution
Comme vous pouvez le constater, les résultats de la probabilité que la "balle" tombe sur le secteur correspondant sont presque identiques aux résultats théoriques calculés.
#property script_show_inputs //--- input parameters input int StartCount=100000000; // Границы соответствующих секторов рулетки double select1[]; // начало сектора double select2[]; // конец сектора //—————————————————————————————————————————————————————————————————————————————— void OnStart() { MathSrand((int)TimeLocal());// сброс генератора // массив с тестовым набором чисел double array[6]={100.0,80.0,40.0,10.0,1.0,-10.0}; ArrayResize(select1,6);ArrayInitialize(select1,0.0); ArrayResize(select2,6);ArrayInitialize(select2,0.0); // счетчики для подсчета выпадений соответствующего числа из тестового набора int h0=0,h1=0,h2=0,h3=0,h4=0,h5=0; // нажмём кнопочку секундомера int time_start=(int)GetTickCount(); // проведём серию испытаний for(int i=0;i<StartCount;i++) { switch(Roulette(array,6)) { case 0: h0++;break; case 1: h1++;break; case 2: h2++;break; case 3: h3++;break; case 4: h4++;break; default: h5++;break; } } Print((int)GetTickCount()-time_start," мс - Время исполнения"); Print("h5 ",h5, " ",h5*100.0/StartCount); Print("h4 ",h4, " ",h4*100.0/StartCount); Print("h3 ",h3, " ",h3*100.0/StartCount); Print("h1 ",h1, " ",h1*100.0/StartCount); Print("h0 ",h0, " ",h0*100.0/StartCount); Print("----------------"); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Рулетка. int Roulette(double &array[], int SizeOfPop) { int i=0,u=0; double p=0.0,start=0.0; double delta=(array[0]-array[SizeOfPop-1])*0.01-array[SizeOfPop-1]; //------------------------------------------------------------------------------ // зададим границы секторов for(i=0;i<SizeOfPop;i++) { select1[i]=start; select2[i]=start+MathAbs(array[i]+delta); start=select2[i]; } // бросим "шарик" p=RNDfromCI(select1[0],select2[SizeOfPop-1]); // посмотрим, на какой сектор упал "шарик" for(u=0;u<SizeOfPop;u++) if((select1[u]<=p && p<select2[u]) || p==select2[u]) break; //------------------------------------------------------------------------------ return(u); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Генератор случайных чисел из заданного интервала. double RNDfromCI(double min,double max) {return(min+((max-min)*MathRand()/32767.0));} //——————————————————————————————————————————————————————————————————————————————
OK.
Nous avons un tableau trié de nombres réels. Nous devons sélectionner une cellule du tableau avec une probabilité correspondant à la taille du secteur de la roulette imaginaire.
Expliquez le principe du réglage de la "largeur du secteur", qui correspond aux valeurs du tableau. Ou est-il réglé séparément ?
C'est la question la plus sombre, le reste n'est pas un problème.
Deuxième question : qu'est-ce que le chiffre 0,01 ? D'où vient-il ?
En bref : dites-moi où obtenir les probabilités correctes de décrochage des secteurs (largeur en tant que fraction de la circonférence).
Vous pouvez juste la taille de chaque secteur. A condition (par défaut) que la taille négative n'existe pas dans la nature. Même dans le casino. ;)
Expliquez le principe du réglage de la "largeur du secteur", qui correspond aux valeurs du tableau. Ou est-il réglé séparément ?
La largeur des secteurs ne peut pas correspondre aux valeurs du tableau, sinon l'algorithme ne fonctionnera pas pour tous les nombres.
Ce qui compte, c'est la distance qui sépare les chiffres les uns des autres. Plus tous les chiffres sont éloignés du premier, moins ils ont de chances de tomber. En substance, nous reportons sur une ligne droite des barres proportionnelles à la distance entre les numéros, ajustées par un facteur de 0,01, de sorte que le dernier numéro dont la probabilité de tomber n'était pas égale à 0 comme le plus éloigné du premier. Plus le coefficient est élevé, plus les secteurs sont égaux. Le fichier Excel est joint, faites-en l'expérience.
MetaDriver:
1. En bref : Dites-moi où obtenir les probabilités correctes d'abandon d'un secteur (largeur en fractions de la circonférence).
2. Vous pouvez simplement dimensionner chaque secteur. en supposant (par défaut) que les tailles négatives n'existent pas dans la nature. pas même dans les casinos. ;)1. Le calcul des probabilités théoriques est donné en excel. Le premier nombre est la probabilité la plus élevée, le dernier nombre est la probabilité la plus faible mais n'est pas égal à 0.
2) Les tailles négatives de secteurs n'existent jamais pour aucun ensemble de nombres, à condition que l'ensemble soit trié par ordre décroissant - le premier nombre est le plus grand (cela fonctionnera avec le plus grand de l'ensemble mais un nombre négatif).
La largeur des secteurs ne peut pas correspondre aux valeurs du tableau, sinon l'algorithme ne fonctionnera pas pour tous les nombres.
hu : Ce qui compte, c'est la distance qui sépare les chiffres. Plus tous les chiffres sont éloignés du premier, moins ils ont de chances de tomber. En substance, nous reportons sur une ligne droite des segments proportionnels aux distances entre les numéros, corrigés par un facteur de 0,01, de sorte que la probabilité que le dernier numéro ne tombe pas était de 0 comme le plus éloigné du premier. Plus le coefficient est élevé, plus les secteurs sont égaux. Le fichier excel est joint, faites-en l'expérience.
1. Le calcul des probabilités théoriques est donné dans l'excel. Le premier nombre est la probabilité la plus élevée, le dernier nombre est la probabilité la plus faible mais n'est pas égal à 0.
2. il n'y aura jamais de tailles négatives de secteurs pour tout ensemble de nombres, à condition que l'ensemble soit trié par ordre décroissant - le premier nombre est le plus grand (cela fonctionnera avec le plus grand de l'ensemble mais aussi avec un nombre négatif).
Votre schéma "à l'improviste" fixe la probabilité du plus petit nombre(vmh). Il n'y a pas de justification raisonnable.
// Puisque la "justification" est un peu difficile. C'est bon, il n'y a que N-1 espaces entre les clous.
Cela dépend donc du "coefficient", lui aussi sorti de la boîte. Pourquoi 0,01 ? Pourquoi pas 0,001 ?
Avant d'effectuer l'algorithme, vous devez décider du calcul de la "largeur" de tous les secteurs.
zyu : Donnez la formule permettant de calculer les "distances entre les nombres". Quel numéro est le "premier" ? Quelle est la distance qui le sépare de lui-même ? Ne l'envoyez pas à Excel, je suis passé par là. C'est déroutant sur un plan idéologique. D'où vient le facteur de correction et pourquoi est-il ainsi ?
Celle en rouge n'est pas vraie du tout. :)
ce sera très rapide :
int Selection() { return(RNDfromCI(1,SizeOfPop); }
La qualité de l'algorithme dans son ensemble ne devrait pas être affectée.
Et même si c'est le cas, cette option prendra le pas sur la qualité au détriment de la vitesse.
1. Votre schéma "à l'improviste" fixe la probabilité du plus petit nombre(vmh). Il n'y a pas de justification raisonnable. Donc, il(vmh) dépend du "coefficient" également "hors de la boîte". pourquoi 0,01 ? pourquoi pas 0,001 ?
2. Avant d'effectuer l'algorithme, vous devez décider du calcul de la "largeur" de tous les secteurs.
3. zu : Donnez la formule permettant de calculer les "distances entre les nombres". Quel numéro est le "premier" ? À quelle distance se trouve-t-il de vous-même ? Ne l'envoyez pas à Excel, je suis passé par là. C'est déroutant sur un plan idéologique. D'où vient le facteur de correction et pourquoi exactement ?
4. Ce qui est souligné en rouge n'est pas vrai du tout. :)
1. Oui, ce n'est pas vrai. J'aime ce coefficient. Si vous en aimez un autre, j'en utiliserai un autre - la vitesse de l'algorithme ne changera pas.
2. la certitude est atteinte.
3. ok. nous avons un tableau trié de nombres - array[], où le plus grand nombre est dans array[0], et un rayon de nombres avec un point de départ 0.0 (vous pouvez prendre n'importe quel autre point - rien ne changera) et dirigé dans la direction positive. Disposez les segments sur la raie de cette manière :
start0=0=0 end0=start0+|array[0]+delta|
start1=end0 end1=start1+|array[1]+delta|
start2=end1 end2=start2+|array[2]+delta|
......
start5=end4 end5=start5+|array[5]+delta|
Où :
delta=(array[0]-array[5])*0.01-array[5];
C'est toute l'arithmétique. :)
Maintenant, si nous lançons une "balle" sur notre rayon marqué, la probabilité de toucher un certain segment est proportionnelle à la longueur de ce segment.
4. Parce que vous avez mis en évidence le mauvais (pas tous). Vous devriez mettre en évidence :"Essentiellement, nous traçons sur la ligne des nombres les segments proportionnels aux distances entre les nombres, corrigés par un facteur de 0,01 afin que le dernier nombre n'ait pas de probabilité d'atteindre 0".
ce sera très rapide :
int Selection() { return(RNDfromCI(1,SizeOfPop); }
La qualité de l'algorithme dans son ensemble ne devrait pas être affectée.
Et si elle est même légèrement affectée, elle prendra le pas sur la qualité au détriment de la vitesse.
:)
Suggérez-vous de sélectionner simplement un élément du tableau au hasard ? - Cela ne prend pas en compte les distances entre les numéros de tableau, votre option est donc inutile.
- www.mql5.com
:)
Suggérez-vous que vous choisissez simplement un élément du tableau au hasard ? - Cela ne prend pas en compte la distance entre les nombres dans le tableau, donc votre option est sans valeur.
ce n'est pas difficile à vérifier.
Est-il confirmé expérimentalement qu'elle est inadaptée ?
est-il confirmé expérimentalement qu'il est sans valeur ?
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Je suggère de discuter des problèmes de logique d'algorithme optimal ici.
Si quelqu'un doute que son algorithme a une logique optimale en termes de vitesse (ou de clarté), il est le bienvenu.
De même, je souhaite la bienvenue dans ce fil à ceux qui veulent pratiquer leurs algorithmes et aider les autres.
À l'origine, j'avais posté ma question dans la rubrique "Questions d'un nunuche", mais je me suis rendu compte qu'elle n'y avait pas sa place.
Veuillez donc suggérer une variante plus rapide de l'algorithme de la "roulette" que celle-ci :
Il est clair que les tableaux peuvent être retirés de la fonction, de sorte qu'ils ne doivent pas être déclarés à chaque fois et redimensionnés, mais j'ai besoin d'une solution plus révolutionnaire. :)