Redes neuronales. Preguntas de los expertos. - página 5
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
De acuerdo. Eso es lo que preguntaba, cuál es la relación entre el error y el beneficio, preferiblemente en OOS....))
También joo dijiste que el resultado nued podía deberse a la normalización de los datos, yo te contesté que no había ninguno.
Estoy de acuerdo con Leo en que no siempre es el criterio de error el que determina el beneficio final, pero es el error lo que importa en la tarea que tengo ahora delante. Esta noche colgaré la previsión realizada por la red para conocer la opinión de los demás sobre la calidad de la previsión y las posibles mejoras)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
No tienes que perder el tiempo, porque la diferencia entre "querer" y "conseguir" no es en absoluto filosófica, aunque se formule con las nociones filosóficas de "subjetivo" y "objetivo".
El hecho de que los resultados del ajuste sean inversamente proporcionales al error cuadrático medio es algo que sabemos sin ti.
Inequívocamente, la red debe aspirar a un beneficio en el OOS. De lo contrario, no tiene sentido.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
¿Utilizas también el error cuadrático medio? Usted es el padre de la red emc. :)
Reshetov escribió(a) >>
Definitivamente, la red debe apuntar a un beneficio en el OOS. De lo contrario, no tiene sentido.
Es comprensible. Otra cuestión es cómo debe esforzarse por conseguirlo.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
No utilizo el error cuadrático medio para operar, ya que sólo caracteriza la calidad del ajuste.
Por lo tanto, el error en la muestra no debería tender a
Como prometí, pongo una foto y una explicación de la misma. Red: MLP de una capa oculta. 2000 puntos de entrenamiento. 1000 en la salida del muestreador) recibí corriente y pre EMA del primer cuadro y pre cierre del primero y del segundo. ¡Eso es todo! ¿Por qué todo y tan poco? Porque el aumento del número de neuronas, capas, entradas, etc. no influye en absoluto en el resultado. Esto es lo que me asusta) Y lo que se muestra como una predicción, se puede obtener, bueno, una fórmula muy simple, que se calcula a mano. ¿Por qué no lo tengo tan claro? ¿Qué debo cambiar? ¿Se puede hacer mejor?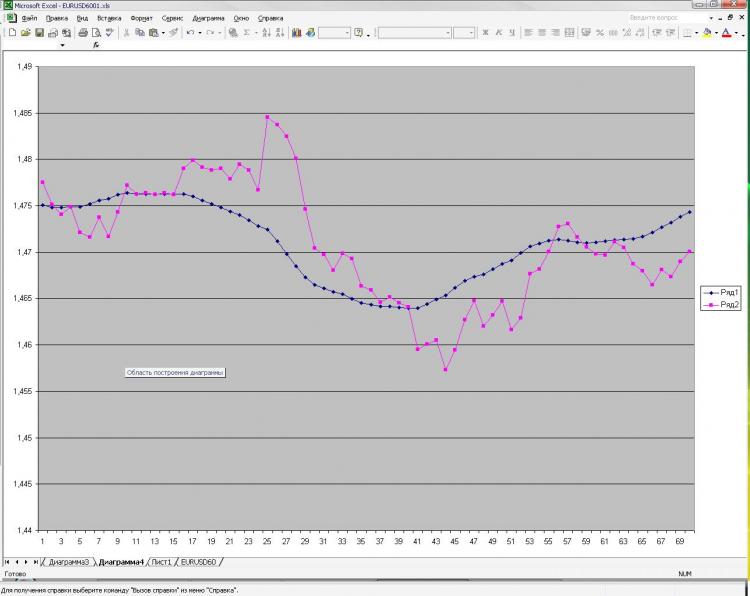
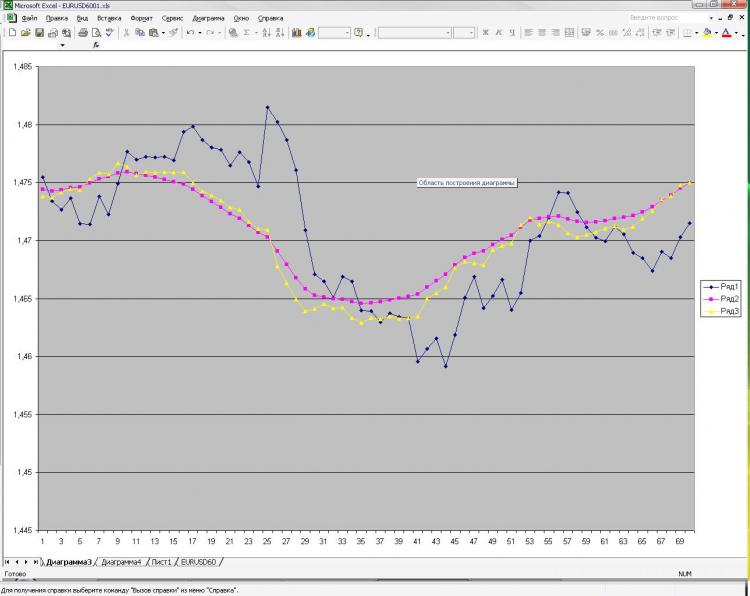
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
Ha descrito el problema de la aproximación. Dos puntos de "referencia" no son suficientes para describir la forma. Además, se suministra un punto más de clout cada uno, que no sólo no describe la curvatura, sino también una línea recta. Pruebe al menos 3 puntos de cada conjunto de parámetros de entrada. Es decir, tres puntos de EMA y tres puntos de cláusula, por lo tanto 6 neuronas de entrada, con 6 a 12 neuronas en la capa oculta. Un mayor número de neuronas en la capa oculta no es razonable para este problema.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Dame una muestra aquí, lo probaré en Statistica