Discussion of article "Kernel Density Estimation of the Unknown Probability Density Function"
To the author. Even better results are obtained if we estimate not the density of distribution, but the distribution function, i.e. the integral of the density: firstly, it is easier to build it on the data, and since it is always non-decreasing and bounded between 0 and 1, the sensitivity to the choice of smoothing algorithm, be it kernel, spline, regression or anything else, is much lower. The requirements on the amount of data available are also reduced, and by an order of magnitude.
Well, the density can be easily obtained by numerical differentiation, if necessary.
Well, the density can be easily obtained by numerical differentiation if necessary.
Maybe. I can't say anything about it. I haven't even tried to evaluate pdf via cdf . Most likely the prejudice that using differentiation would require a significant increase in the accuracy of cdf estimation worked. In addition, I have not come across any publications evaluating the cdf->pdf method or comparing it with other methods. If you can share links, I would be grateful.
The original idea was not to use any external tools, i.e. it was assumed that everything should be implemented only by MQL5 tools.
This is the idea of all inventors of bicycles without exception.
Look at what the corresponding packages have in this regard and compare it with what you have provided - an infinitesimal amount of what is needed when applying matstatistics and econometrics in trading.
Maybe. I can't say anything about it. I haven't even tried to estimate pdf via cdf . Most likely, the prejudice that using differentiation would require a significant increase in the accuracy of cdf estimation worked. In addition, I have not come across any publications evaluating the cdf->pdf method or comparing it with other methods. If you share links, I would be grateful.
I can't provide references because I don't have them. I will instead give these considerations.
When evaluating a pdf directly, we have to divide the domain of the definition into intervals in advance, and there are two problems: firstly, we don't know how many intervals it is better to divide the domain into, and secondly, we don't know what type of grid(uniform, ... ?) would be best. And if the second question people still somehow tried to solve, for example, using quantile partitioning, then for the first one, in my opinion, there are no universal methods at all: all known to me have limitations that make them of little use in automation tasks, when we can not afford the method of poke.
The cdf estimation is devoid of these disadvantages. In this case, the steps of the function are located exactly where the input data falls, and so the problem of choosing a grid for the interpolant disappears by itself. Once the grid has been created, it is not difficult to choose the number of intervals: we already know the maximum number of intervals (and their location!!!), hence, by thinning we can set any required accuracy, and each time on a natural grid that best matches the structure of the input data.
In practice, I have used this technique to search for local modes of empirical distributions when the number of data samples does not exceed 100, and I obtained very smooth results, and visually the accuracy of the search is defined as quite qualitative, at least 2-4 main modes are found practically without deviations. But I use a different smoothing algorithm, I don't like the kernel ones for several reasons.
All perfectly fair. But as it seems to me except for one point, which you apparently just did not pay attention to.
A well known expression for Kernel smoother is "Kernel smooth".
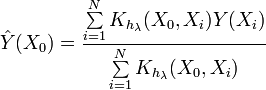
A method based on such smoothing for estimating pdf might look like this (simplified):
- We partition the input sequence into intervals (clustering, Binning)
- Smooth the resulting histogram.
If you don't like kernel smoothing, you can use, for example, p-spline. (It is probably better to choose p-spline right away).
With this approach to pdf estimation everything you said turns out to be absolutely fair. But even in this case this method of estimation for sequences of large length (>1000000) gives excellent results. As the length of the input sequence decreases, all those charms you mentioned begin to appear more and more strongly.
Now let's look at the expression of Kernel density estimation ( KDE)
![]()
This expression is different from the one given earlier. As we can see, this expression directly determines the value of the probability density function at a given point. And what is important in this case, there is no partitioning into intervals. The values of the input sequence are used directly.
At least, this is how I see the situation with KDE. The algorithm of pdf estimation given in the article at first glance copes well with sequences of 20-30 elements length. Sometimes you may want to reduce the degree of smoothing. You can easily do it by replacing in the code
h=0.9*a/MathPow(N,0.2); // Silverman's rule of thumbby
h=0.7*a/MathPow(N,0.2); // Silverman's rule of thumb
The original idea was not to use any external tools, i.e. it was assumed that everything should be implemented only by MQL5 tools.
This is the idea of all inventors of bicycles without exception.
Look at what the corresponding packages have in this regard and compare it with what you have provided - an infinitesimal amount of what is needed when applying matstatistics and econometrics in trading.
Dear Alex,
It is easy for you to reason from the height of your flight. But think for a second about the following:
This resource is called"www.mql5.com - Automated Trading and Testing of Trading Strategies". As you can see, the site is called mql5, not EViews or even MQ or MT5. Therefore, it is easy to assume that this site is primarily focused on popularisation, debugging and development of the MQL5 programming language. This is confirmed by the presence of the servicedesk and placement of MQL5 reference information on the site.
If this site was called, for example, "a collection of trading strategies" and did not belong to MQ. In this case, one would expect publications describing solutions in Exel, R, EVievs, Gauss, Stata and so on to appear on such a site.
If I had published this article on EViews site, I might have tried to understand the essence of your reproach. But you and I are not on EViews right now.
This site is visited by people with very different backgrounds. They are people of different ages with different educational backgrounds and different specialities. I think most of them have little or no experience with econometric packages. Do you think that all these people should be banished from this site, like, let them learn EViews first?
Since you have self-published, you should be familiar with the procedure of publishing articles on this site. It is impossible to self-publish any article. You can only submit an article for consideration. The administration of the site itself selects articles suitable for their general concept. And in some cases, the administration itself orders articles on topics of interest to them. As I have already said, the administration has a general concept and statistics on the number of requests for this or that publication. In this situation, I think it is not quite right to address me with claims about the subject of the article. Maybe you should discuss these issues with MQ representatives ?
There are published articles on this site that are not interesting to me. I emphasise, not bad articles, but just not interesting to me. I don't usually read them or write comments on them. Maybe you should choose a similar line of behaviour for yourself? Although I dare not give advice, do as you feel more comfortable.
Dear Alex,
It is easy for you to reason from the height of your flight. But think about the following for a second:
This resource is called"www.mql5.com - Automated Trading and Testing of Trading Strategies". As you can see, the site is called mql5, not EViews or even MQ or MT5. Therefore, it is easy to assume that this site is primarily focused on popularisation, debugging and development of the MQL5 programming language. This is confirmed by the presence of the servicedesk and placement of MQL5 reference information on the site.
If this site was called, for example, "a collection of trading strategies" and did not belong to MQ. In this case, one would expect publications describing solutions in Exel, R, EVievs, Gauss, Stata and so on to appear on such a site.
If I had published this article on EViews site, I might have tried to understand the essence of your reproach. But you and I are not on EViews right now.
This site is visited by people with very different backgrounds. They are people of different ages with different educational backgrounds and different specialities. I think most of them have little or no experience with econometric packages. Do you think that all these people should be banished from this site, like, let them learn EViews first?
Since you have self-published, you should be familiar with the procedure of publishing articles on this site. It is impossible to self-publish any article. You can only submit an article for consideration. The administration of the site itself selects articles suitable for their general concept. And in some cases, the administration itself orders articles on topics of interest to them. As I have already said, the administration has a general concept and statistics on the number of requests for this or that publication. In this situation, I think it is not quite right to address me with claims about the topic of the article. Maybe you should discuss these issues with MQ representatives ?
There are published articles on this site that are not interesting to me. I emphasise, not bad articles, but just not interesting to me. I don't usually read them or write comments on them. Maybe you should choose a similar line of behaviour for yourself? Although I dare not give advice, do as you feel more comfortable.
I can't accept your answer, as it is not at all on the essence of my post. I will try to explain my point of view.
1. Metaquotes has nothing to do with it at all - they have provided a very decent tool and they are doing it.
2. I am not aware of any restrictions on the topics of the articles. Of course, within the limits of trading. This site has a section "Statistics", i.e. they understand the subject of the site much wider than you do, in full accordance with the content and problems of trading. Let's not refer to Metaquotes and move on to the substance.
3. my post is not about WHAT to develop, but HOW to develop. For me, this is what is fundamental in connection with your article. I was not campaigning for EViews, of which I have a low opinion - it is good for demonstration and training purposes, but I don't think you can trade on it. My link is to packages to demonstrate the width of the problem.
4. I've been in programming for a long time. 40 years ago the first program libraries appeared and immediately, 40 years ago, criticised amateurs re-writing some program from an existing package. You are not the first. But this site is full of amateurs who like to build a bicycle again - hence my hypertrophied reaction.
5. The issue of nuclear evaluation is a chewed up and chewed over issue. And if you took someone else's library, you would have the opportunity to rise above the technical difficulties you solved in your paper and perhaps offer a solution to the issues raised by practitioner alsu, or remember that visual evaluation of distributions plays a very important role in their formal evaluation, or expand functionally, etc. - either way you would be a step higher.
I had no desire to express anything offensive towards you. Your article and development is respected, but I can't agree with the methodological focus of the technique of implementing your ideas.
My post on your article is dictated by the hope that someone will systematically supplement the Metaquot terminal with means of statistics and econometrics. I refer you to such people.
Extremely interesting. Very interesting.
Do you accept requests?
Not just open source code, but statistic-oriented code is desirable. Please pay attention to R.
Extremely interesting. Very interesting.
Do you accept requests?
Not just open source code, but statistic-oriented code is desirable. Please pay attention to R.
Requests are accepted here: https://www.mql5.com/ru/forum/6505. Write whatever you want. :)
- www.mql5.com
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Kernel Density Estimation of the Unknown Probability Density Function is published:
The article deals with the creation of a program allowing to estimate the kernel density of the unknown probability density function. Kernel Density Estimation method has been chosen for executing the task. The article contains source codes of the method software implementation, examples of its use and illustrations.
Author: Victor