Discussing the article: "Propensity score in causal inference"
https://www.mql5.com/ru/code/48482
An archive of models from the article (except for the very first one in the list), for quick reference without installing Python.

- www.mql5.com
Hello, I used your method : propensity_matching_naive.py in the parameters I set the training of 25 models. After training appeared in the python directory folder :
catboost_info .
What did I try to do? Loaded AUDCAD h1 quotes, then using the file :
propensity_matching_naive.py from your publication : https://www.mql5.com/ru/articles/14360.
I can't understand what to do next, what to save further in ONNX format, or this method works only as a test quality assessment? :
catmodel propensity matching naive.onnx
catmodel_m propensity matching naive.onnx
I use pythom for the first time in my life, installed without problems, libraries are also not difficult. I read your publications, serious approach, but perhaps not the easiest method of calculation, I may be wrong, everything is relative.
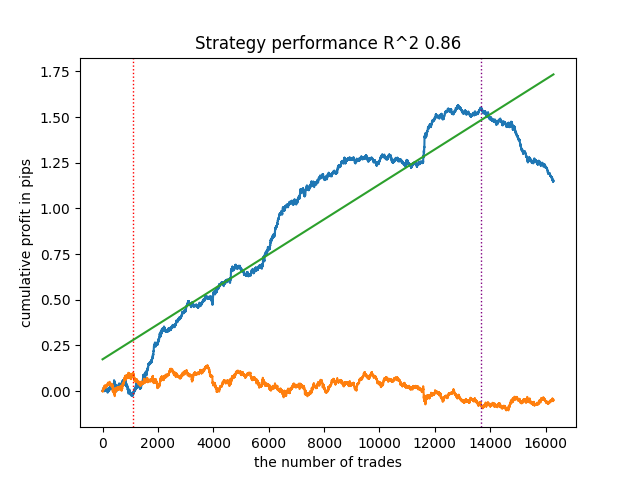
I have attached screens, what I got in my training.
 в причинно-следственном выводе")
- www.mql5.com
{kind=link}
{kind=link}
Hello, I used your method : propensity_matching_naive.py in the parameters I set the training of 25 models. After training appeared in the python directory folder :
catboost_info .
What did I try to do? Loaded AUDCAD h1 quotes, then using the file :
propensity_matching_naive.py from your publication : https://www.mql5.com/ru/articles/14360.
I can't understand what to do next, what to save further in ONNX format, or this method works only as a test quality assessment? :
catmodel propensity matching naive.onnx
catmodel_m propensity matching naive.onnx
I am using pythom for the first time in my life, installed it without problems, libraries are also not difficult. I read your publications, serious approach, but perhaps not the easiest method of calculation, I may be wrong, everything is relative.
I have attached screens, what I got in my training.
Good. in previous articles described 2 ways to export.
1. the earlier one, exporting the model to native MQL code
2. export to onnx format in later articles.
I don't remember if there is a model export function in the python files to this article. "export_model_to_ONNX()", If not, you can take from the earlier ones.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Check out the new article: Propensity score in causal inference.
The article examines the topic of matching in causal inference. Matching is used to compare similar observations in a data set. This is necessary to correctly determine causal effects and get rid of bias. The author explains how this helps in building trading systems based on machine learning, which become more stable on new data they were not trained on. The propensity score plays a central role and is widely used in causal inference.
In this article, I will cover the topic of matching briefly mentioned in the previous article, or rather one of its varieties - propensity score matching.
This is important because we have a certain set of labeled data that is heterogeneous. For example, in Forex, each individual training example may belong to the area of high or low volatility. Moreover, some examples may appear more often in the sample, while some appear less often. When attempting to determine the average causal effect (ATE) in such a sample, we will inevitably encounter biased estimates if we assume that all examples in the sample have the same propensity to produce treatment. When trying to obtain a conditional average treatment effect (CATE), we may encounter a problem called the "curse of dimensionality".
Matching is a family of methods for estimating causal effects by matching similar observations (or units) in treatment and control groups. The purpose of matching is to make comparisons between similar units to achieve as accurate an estimate of the true causal effect as possible.
Author: Maxim Dmitrievsky