Discussing the article: "Neural networks made easy (Part 57): Stochastic Marginal Actor-Critic (SMAC)"
{kind=link}
Dmitry, thank you for your hard work. Everything is working.
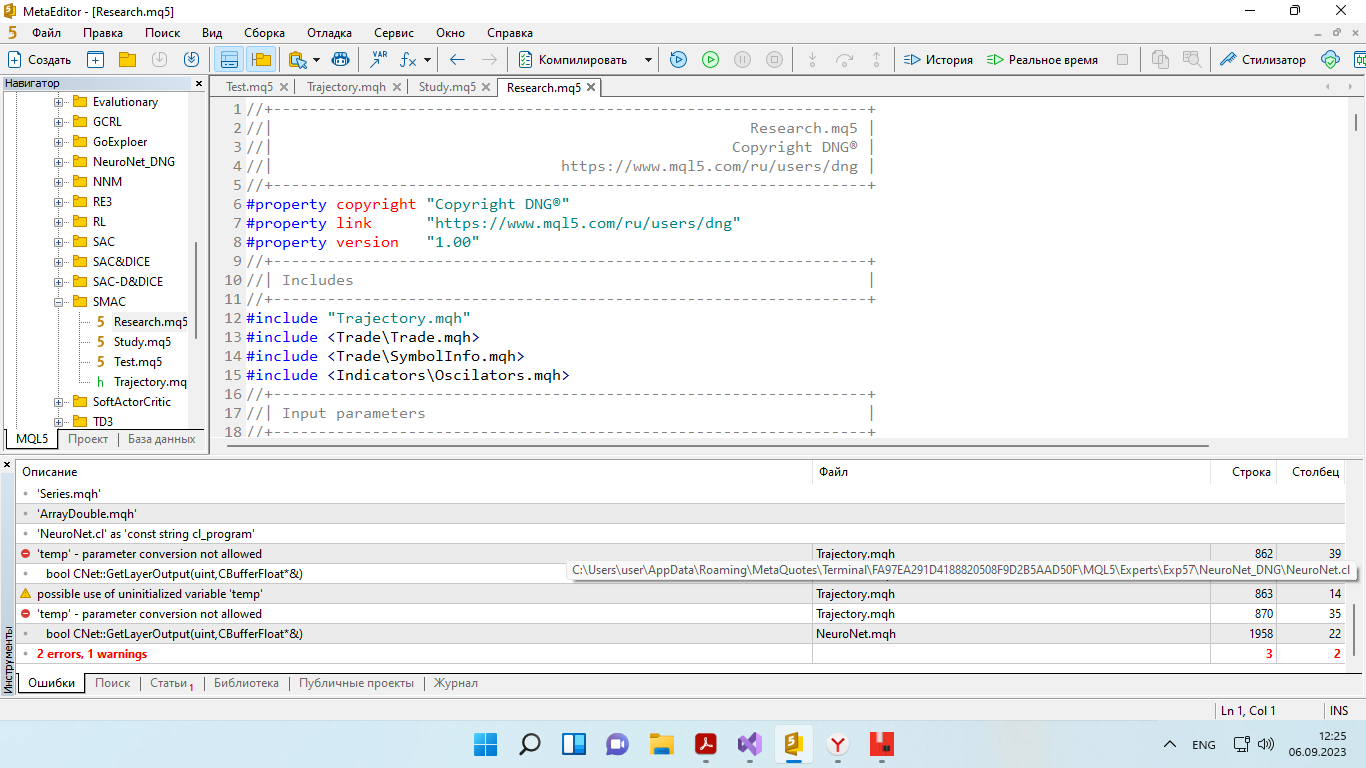
I collect examples by Expert Advisor Research for 100 passes, train the model by Expert Advisor Study, test with Test. Then I collect 50 passes again, train for 10 000 iterations, test again.
And so on until the model learns. Except that I have so far Test constantly gives different results after the cycle and not always positive. I have run a cycle, 2-3 tests and the results are different.
At what cycle will the result become stable? Or is it an endless work and the result will always be different?
Thank you!
And so on until the model learns. Except that I have so far Test constantly gives different results after the cycle and not always positive. That is, I run a cycle, 2-3 tests and the results are different.
At what cycle the result will become stable? Or is it an endless work and the result will always be different?
Thank you!
The Expert Advisor trains a model with a stochastic policy. This means that the model learns probabilities of maximising rewards for taking particular actions in particular states of the system. As it interacts with the environment, the actions are sampled with the learnt probabilities. In the initial stage, the probabilities of all actions are the same and the model selects an action randomly. In the learning process, the probabilities will shift and the choice of actions will be more conscious.
Dmitry hello. How many cycles did it take you as Nikolay described above to get a stable positive result?
And another interesting thing is that if an Expert Advisor learns for the current period and if for example in a month it will need to be retrained taking into account new data, it will be retrained completely or before learning? Will the training process be comparable to the initial one or much shorter and faster? And also if we have trained a model on EURUSD, then for work on GBPUSD it will be retrained as much as the initial one or it will be faster just before training? This question is not about this particular article of yours, but about all your Expert Advisors working on the principle of reinforcement learning.
Good day.
Dimitri, thank you for your work.
I want to clarify for everyone...
What Dimitri is posting is not a "Grail".
It is a classic example of an academic problem, which implies preparation for scientific research activities of theoretical and methodological nature.
And everyone wants to see a positive result on their account, right here and now....
Dmitry teaches us how to solve (our/my/your/their) problem by all methods presented by Dmitry.
Popular AI (GPT) has over 700 Million parameters!!!! How much is this AI?
If you want to get a good result, exchange ideas (add parameters), give test results, etc.
Create a separate chat room and "get" the result there. You can brag here :-), thus showing the effectiveness of Dmitry's work...
Create a separate chat room and "get" the result there. You can brag here :-), thus showing the effectiveness of Dmitry's work...
Mate, nobody is waiting for the grail here! I would just like to see that what Dmitriy puts out actually works. Not from Dmitry's words in his articles (all his articles have almost positive results), but on my computer. I downloaded his Expert Advisor from this article and have already done 63 cycles of training (data collection -> training). And it is still losing money. For all 63 cycles there were only a couple of data collections, when out of 50 new examples there were 5-6 positive ones. Everything else is minus. How can I see that it really works?
I asked Dmitriy in the above post, he didn't answer anything. The same problem in other articles - no result no matter how much you train.....
Friend, if you got a stable result, then write how many cycles you did before stable result, for example in this article? If to change, what to change to see the result on your computer, just in the tester? Not a grail, but at least to see that it works...?
Create a separate CHAT and "get" the result there. You can brag here :-), thereby showing the effectiveness of Dmitry's work ...
Here are the Params: (based on Dmitry and some research.)
#include "FQF.mqh"
The length of the message should not exceed 64000 characters
===I CUT THE LAST PARTS as Comments are limited to 64000 Chars but you know what to do... =)
The length of the message should not exceed 64000 characters
{kind=link}
{kind=link}
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Check out the new article: Neural networks made easy (Part 57): Stochastic Marginal Actor-Critic (SMAC).
Here I will consider the fairly new Stochastic Marginal Actor-Critic (SMAC) algorithm, which allows building latent variable policies within the framework of entropy maximization.
When building an automated trading system, we develop algorithms for sequential decision making. Reinforcement learning methods are aimed exactly at solving such problems. One of the key issues in reinforcement learning is the exploration process as the Agent learns to interact with its environment. In this context, the principle of maximum entropy is often used, which motivates the Agent to perform actions with the greatest degree of randomness. However, in practice, such algorithms train simple Agents that learn only local changes around a single action. This is due to the need to calculate the entropy of the Agent's policy and use it as part of the training goal.
At the same time, a relatively simple approach to increasing the expressiveness of an Actor's policy is to use latent variables, which provide the Agent with its own inference procedure to model stochasticity in observations, the environment and unknown rewards.
Introducing latent variables into the Agent's policy allows it to cover more diverse scenarios that are compatible with historical observations. It should be noted here that policies with latent variables do not allow a simple expression to determine their entropy. Naive entropy estimation can lead to catastrophic failures in policy optimization. Besides, high variance stochastic updates for entropy maximization do not readily distinguish between local random effects and multimodal exploration.
One of the options for solving these latent variable policies shortcomings was proposed in the article "Latent State Marginalization as a Low-cost Approach for Improving Exploration". The authors propose a simple yet effective policy optimization algorithm capable of providing more efficient and robust exploration in both fully observable and partially observable environments.
Author: Dmitriy Gizlyk