Diskussion zum Artikel "Backpropagation von Neuronalen Netze mit MQL5-Matrizen"
Mehr Dank an Stanislav! Endlich wurde ein Artikel über neuronale Netze mit nativen Matrizen geschrieben....
Nebenbei bemerkt. Gerade heute habe ich herausgefunden, dass es einen neuen Block in der Dokumentation über ML gibt.

- www.mql5.com
Danke an den Autor für den ausführlichen Artikel und für die ehrlichen Schlussfolgerungen.
"Das, was ich vergessen habe, weißt du noch gar nicht" - so könnte der Autor auf solche Kritik reagieren.
"Die Dinge, die ich vergessen habe, kennst du noch gar nicht", könnte ein Autor auf eine solche Kritik antworten.
Es gibt zwei Aspekte, und die sind wichtig:
1. die Ausführung, der technische Teil, die Universalität, die auch von reiferen Programmierern gelobt wird. Und hier kann und will ich in der Tat den Code nicht kritisieren und habe es auch nicht versucht. Ich spreche von etwas anderem:
2. Testen. Der Autor hat darauf hingewiesen, dass alle seine Modelle funktionieren. In der Tat, wenn Sie die "Start"-Taste im Tester drücken, erscheint ein zufälliges Bild für die nächsten 2 Wochen, und von 10 Drücken 5 - Pflaume, 5 - Gewinn. Natürlich, wenn Sie so etwas auf die reale - 50/50 Lebensfähigkeit Ihres Depots. Dies ist nicht der Fall. Auf meine Fragen, was es ist und wie man es beheben kann, sagte der Autor, dass es so sein sollte, es ist das Prinzip des Modells. Nun, hier fiel ich einfach aus, keine Worte.
Zwei Monate habe ich versucht, diese Netze zu starten, sie wollten nicht auf NVIDIA arbeiten, dank Aleksey Vyazmikin, neu geschrieben der Autor den Code und alles funktionierte auf 3080. Und am Ende - nicht funktionsfähige Modelle. Es ist doppelt beleidigend.
Aber wenn ich Sie beleidigt habe, entschuldige ich mich, ich hatte keine solche Absicht.
matrix temp; if(!outputs[n].Derivative(temp, of))
In der Backpropagation erwarten die Ableitungsfunktionen, dass sie x erhalten und nicht die Aktivierung von x (es sei denn, sie haben es kürzlich für die Aktivierungsfunktionen geändert, auf die es zutrifft)
Hier ist ein Beispiel:
#property version "1.00" int OnInit() { //--- double values[]; matrix vValues; int total=20; double start=-1.0; double step=0.1; ArrayResize(values,total,0); vValues.Init(20,1); for(int i=0;i<total;i++){ values[i]=sigmoid(start); vValues[i][0]=start; start+=step; } matrix activations; vValues.Activation(activations,AF_SIGMOID); //sigmoid drucken for(int i=0;i<total;i++){ Print("sigmoidDV("+values[i]+")sigmoidVV("+activations[i][0]+")"); } //Ableitungen matrix derivatives; activations.Derivative(derivatives,AF_SIGMOID); for(int i=0;i<total;i++){ values[i]=sigmoid_derivative(values[i]); Print("dDV("+values[i]+")dVV("+derivatives[i][0]+")"); } //--- return(INIT_SUCCEEDED); } double sigmoid(double of){ return((1.0/(1.0+MathExp((-1.0*of))))); } double sigmoid_derivative(double output){ return(output*(1-output)); }
Es gibt auch Aktivierungsfunktionen, für die man sowohl bei der Aktivierung als auch bei der Ableitung mehr Eingaben machen kann, wie z.B. die elu
Derivative(output,AF_ELU,alpha); Activation(output,AF_ELU,alpha);
In der Backpropagation erwarten die Ableitungsfunktionen, dass sie x erhalten und nicht die Aktivierung von x (es sei denn, sie haben es kürzlich für die Aktivierungsfunktionen geändert, auf die es zutrifft)
Ich bin mir nicht sicher, was Sie meinen. Es gibt Formeln in dem Artikel, die genau in die Zeilen des Quellcodes umgesetzt werden. Die Ausgänge werden mit dem Aktivierungsaufruf während der Feedforward-Phase erhalten, und dann nehmen wir ihre Ableitungen bei Backpropagation. Wahrscheinlich haben Sie übersehen, dass die Indizierung der Output-Arrays in den Klassen mit +1 auf die Indizierung der Schichtgewichte ausgerichtet ist.
Ich bin mir nicht sicher, was Sie meinen. Es gibt Formeln in dem Artikel, die genau in die Zeilen des Quellcodes umgewandelt werden. Die Ausgänge werden mit dem Aktivierungsaufruf während der Feedforward-Phase erhalten, und dann nehmen wir ihre Ableitungen auf Backpropagation. Wahrscheinlich haben Sie übersehen, dass die Indizierung der Output-Arrays in den Klassen mit +1 auf die Indizierung der Schichtgewichte ausgerichtet ist.
Ja, die temp-Matrix wird mit den Gewichten multipliziert und output[] enthält dann die Aktivierungswerte.
In der hinteren Stütze nehmen Sie die Ableitungen dieser Aktivierungswerte, während die MatrixVector Ableitungsfunktion erwartet, dass Sie die temporären Werte senden

Hier ist der Unterschied in den Ableitungen
Erlauben Sie mir, es zu vereinfachen:
#property version "1.00" int OnInit() { //--- //nehmen wir an, dass x die Ausgabe der vorherigen Schicht ist (*) Gewichte eines Knotens //der Wert, der in die Aktivierung eingeht. double x=3; //das Sigmoid erhalten wir durch die folgende Formel double activation_of_x=sigmoid(x); //und für die Ableitung machen wir double derivative_of_activation_of_x=sigmoid_derivative(activation_of_x); //wir machen das mit matrixvector vector vX; vX.Init(1); vX[0]=3; //wir erstellen einen Vektor für Aktivierungen vector vActivation_of_x; vX.Activation(vActivation_of_x,AF_SIGMOID); //wir erstellen einen Vektor für Ableitungen vector vDerivative_of_activation_of_x,vDerivative_of_x; vActivation_of_x.Derivative(vDerivative_of_activation_of_x,AF_SIGMOID); vX.Derivative(vDerivative_of_x,AF_SIGMOID); Print("NormalActivation("+activation_of_x+")"); Print("vector Activation("+vActivation_of_x[0]+")"); Print("NormalDerivative("+derivative_of_activation_of_x+")"); Print("vector Derivative Of Activation Of X ("+vDerivative_of_activation_of_x[0]+")"); Print("vector Derivative Of X ("+vDerivative_of_x[0]+")"); //Sie führen eine vektorielle Ableitung der Aktivierung von x durch, die den falschen Wert ergibt. //vectorMatrix erwartet, dass Sie x senden, nicht die Aktivierung (x) //--- return(INIT_SUCCEEDED); } double sigmoid(double of){ return((1.0/(1.0+MathExp((-1.0*of))))); } double sigmoid_derivative(double output){ return(output*(1-output)); }
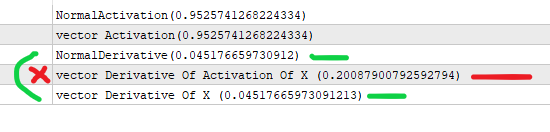
Ich verstehe, was Sie meinen. In der Tat wird die sigmoide Ableitung über "y" formuliert, d. h. über den sigmoiden Wert im Punkt x, also y(x): y'(x) = y(x)*(1-y(x)). Dies ist genau wie die Codes in dem Artikel implementiert.
Ihr Testskript berechnet die "Ableitung" mit x als Eingabe, nicht mit y, daher sind die Werte unterschiedlich.
Ich verstehe Ihren Standpunkt. In der Tat wird die sigmoide Ableitung über "y" formuliert, d. h. über den sigmoiden Wert am Punkt x, also y(x): y'(x) = y(x)*(1-y(x)). Dies ist genau, wie die Codes in dem Artikel implementiert.
Ihr Testskript berechnet die "Ableitung" mit x als Eingabe, nicht mit y, daher sind die Werte unterschiedlich.
Ja, aber die Aktivierungswerte werden an die Ableitungsfunktion übergeben, während sie die Werte vor der Aktivierung erwartet. Das ist es, was ich sagen will.
Und du hast den Punkt übersehen, der korrekte Wert ist mit x als Eingabe (der korrekte Wert laut mqs Funktion selbst).
Du speicherst die output_of_previous * weights nicht irgendwo (denke ich), was in den Ableitungsfunktionen gesendet werden sollte (laut mq's Funktion selbst wieder, ich betone das)
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Backpropagation von Neuronalen Netze mit MQL5-Matrizen :
Der Artikel beschreibt die Theorie und Praxis der Anwendung des Backpropagation-Algorithmus in MQL5 unter Verwendung von Matrizen. Es bietet vorgefertigte Klassen zusammen mit Beispielen von Skripten, Indikatoren und Expert Advisors.
Wie wir weiter unten sehen werden, bietet MQL5 eine ganze Reihe von integrierten Aktivierungsfunktionen. Die Wahl einer Funktion sollte auf der Grundlage des spezifischen Problems (Regression, Klassifizierung) getroffen werden. In der Regel ist es möglich, mehrere Funktionen auszuwählen und dann experimentell die optimale Funktion zu finden.
Häufig verwendete Aktivierungsfunktionen
Aktivierungsfunktionen können verschiedene Wertebereiche haben, begrenzt oder unbegrenzt. Insbesondere Sigmoid (3) bildet die Daten im Bereich [0,+1] ab, was für Klassifizierungsprobleme besser geeignet ist, während der hyperbolische Tangens die Daten im Bereich [-1,+1] abbildet, was für Regressions- und Prognoseprobleme als besser geeignet gilt.
Autor: Stanislav Korotky