文章 "您应当知道的 MQL5 向导技术(第 16 部分):配合本征向量进行主成分分析" 新评论 MetaQuotes 2025.01.10 15:49 新文章 您应当知道的 MQL5 向导技术(第 16 部分):配合本征向量进行主成分分析已发布: 本文所见的主成分分析,是数据分析中的一种降维技术,文中还有如何配合本征值和向量来实现它。一如既往,我们瞄向的是开发一个可在 MQL5 向导中使用的原型专业信号类。 SVD 能够将矩阵数据集拆分为 3 个单独的矩阵来达成降维,其中这 3 个矩阵之一,即 Σ 矩阵,标识数据中最重要的方差方向。这个矩阵也称为对角矩阵,包含奇异值,这些值表示沿每个预先确定的方向的方差量级(记录在 3 个矩阵中的另一个矩阵中,通常称为 U)。奇异值越大,在解释数据可变性时的相应方向就越重要。这导致了含有最高奇异值的 U 列被选作为整个矩阵的代表,其作为相当于将矩阵降维至单个向量。 相反,幂方法迭代细化向量估算,以便朝向主导本征向量收敛。该本征向量捕获数据中最明显变化的方向,并相当于一次原始矩阵的降维。 然而,配合本文所专注的本征向量和数值,我们能够将一个 n x n 矩阵简化为 n 个可能的 n 大小向量,每个向量都得以分配一个本征值。然后,由该本征值指导选择一个最能表示矩阵的本征向量,在解释数据可变性时,该值越高表示正相关程度越高。 作者:Stephen Njuki Sebastien Nicolas Paul Boulenc 2024.06.14 15:01 #1 非常有用,谢谢。 对于"_m "矩阵,为什么不遍历"_rates "索引直到 "i<=_buffer_size"? Stephen Njuki 2024.07.22 19:20 #2 Sebastien Nicolas Paul Boulenc #:了解这些非常有用,谢谢。对于"_m "矩阵,为什么不遍历"_rates "索引直到 "i<=_buffer_size"? if(_buffer_size >= 2) { for(int i = 1; i <= _buffer_size - 1; i++) { ... } } 本来应该是这样的,但考虑到缓冲区容量很大,我想我们复制了一年的数据,这个错误的影响微乎其微。感谢您的指出。 Sebastien Nicolas Paul Boulenc 2024.07.25 12:43 #3 Stephen Njuki #:本来应该是这样的,但考虑到缓冲区很大,我想我们复制了一年的数据,这个错误的影响微乎其微。感谢您的指出。 这当然是个细节问题,不用谢。 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
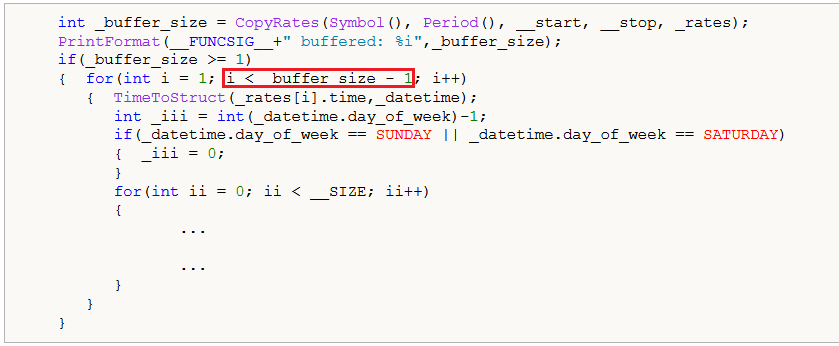
新文章 您应当知道的 MQL5 向导技术(第 16 部分):配合本征向量进行主成分分析已发布:
本文所见的主成分分析,是数据分析中的一种降维技术,文中还有如何配合本征值和向量来实现它。一如既往,我们瞄向的是开发一个可在 MQL5 向导中使用的原型专业信号类。
SVD 能够将矩阵数据集拆分为 3 个单独的矩阵来达成降维,其中这 3 个矩阵之一,即 Σ 矩阵,标识数据中最重要的方差方向。这个矩阵也称为对角矩阵,包含奇异值,这些值表示沿每个预先确定的方向的方差量级(记录在 3 个矩阵中的另一个矩阵中,通常称为 U)。奇异值越大,在解释数据可变性时的相应方向就越重要。这导致了含有最高奇异值的 U 列被选作为整个矩阵的代表,其作为相当于将矩阵降维至单个向量。
相反,幂方法迭代细化向量估算,以便朝向主导本征向量收敛。该本征向量捕获数据中最明显变化的方向,并相当于一次原始矩阵的降维。
然而,配合本文所专注的本征向量和数值,我们能够将一个 n x n 矩阵简化为 n 个可能的 n 大小向量,每个向量都得以分配一个本征值。然后,由该本征值指导选择一个最能表示矩阵的本征向量,在解释数据可变性时,该值越高表示正相关程度越高。
作者:Stephen Njuki