文章 "神经网络变得轻松(第四十五部分):训练状态探索技能"
如何在不使用 OpenCL 的 情况下运行测试?
因为处理器支持 OpenCL,但显卡不支持,测试和优化都无法启动....。
Oleg Pavlenko 使用 OpenCL 的 情况下运行测试?
因为处理器支持 OpenCL,但显卡不支持,测试和优化都无法运行....。
日安,奥列格。
这种实现方式只适用于 OpenCL。要禁用它,你需要重新设计整个网络算法。但如果处理器支持 OpenCL 并安装了相应的驱动程序,就可以在处理器上运行。

问题在于您运行的是 "tester.ex5",它会检查训练模型的质量,而您还没有训练模型。首先,您需要运行Research.mq5 来创建示例数据库。然后运行 StudyModel.mq5,训练自动编码器。在 StudyActor.mq5 或 StudyActor2.mq5 中训练演员(奖励函数不同)。只有这样,tester.ex5 才能正常工作。注意,在后者的参数中需要指定演员模型 Act 或 Act2。这取决于用于研究 Actor 的 Expert Advisor。
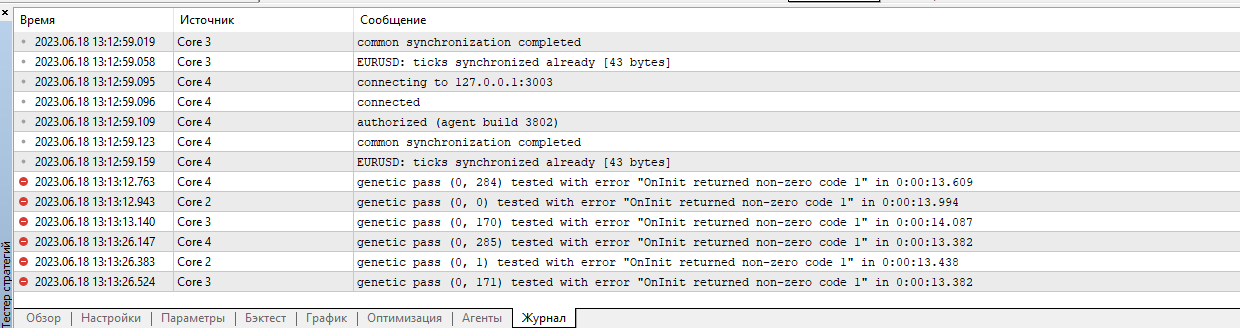

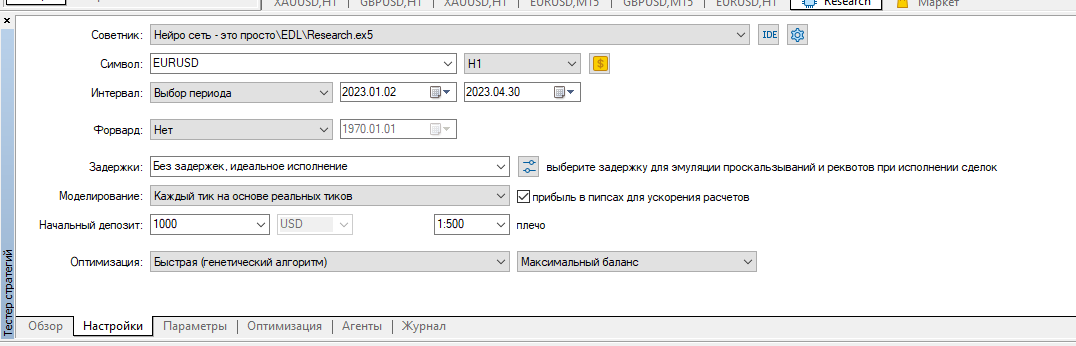
我清除了所有测试代理日志,并在欧元兑美元 H1 上 运行了2023 年前 4 个月的研究 优化。
我在真实点数上运行了它:
结果:只有 4 个样本,2 个在正值,2 个在负值:

也许我做错了什么,优化的参数不对,或者我的终端出了问题?不清楚...我正试图重复您在文章中提到的结果...
错误从一开始就出现了。
优化的设置和结果以及代理和测试人员的日志都附在 Research.zip 压缩包中。
附加的文件:
Research.zip
36 kb
新文章 神经网络变得轻松(第四十五部分):训练状态探索技能已发布:
在没有明确奖励函数的情况下,实用的训练技能就是分层强化学习的主要挑战之一。 以前,我们已领略了解决此问题的两种算法。 但环境研究的完整性问题仍然悬而未决。 本文演示了一种不同的技能训练方式,其可取决于系统的当前状态直接使用。
最初的结果比我们预期的要差。 包含的正面结果则是,测试样本中所用的技能分布相当均匀。 这就是最终我们的测试正面结果所在。 在对自动编码器和代理者进行了多次迭代训练后,我们仍然无法获得能够在训练集上产生盈利的模型。 显然,问题在于自动编码器无法足够准确地预测状态。 结果就是,余额曲线与预期结果相去甚远。
为了验证我们的假设,创建了一个替代的代理者训练 EA “EDL\StudyActor2.mq5”。 替代选项与之前研究的选项之间的唯一区别就是生成奖励的算法。 我们依旧用该循环来预测帐户状态的变化。 这一次,我们取相对余额变化指标作为奖励。
贯穿测试区间,使用修改后的奖励函数进行训练的代理者显示出相当平缓的盈利增长能力。
作者:Dmitriy Gizlyk