文章 "强化学习中的随机决策森林"
if(ts<0.4 && CheckMoneyForTrade(_Symbol,lots,ORDER_TYPE_BUY)) { if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)) { updatePolicy(ts); }; }
您可以将其替换为
if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts);
顺便说一句,您的 if(OrderSend) 检查变量将始终有效。因为如果出现错误,OrderSend 不会返回 0。
不幸的是,这正是我们必须做的。看看这篇文章,它提供了一种有趣的向代理 "传递 "数据的方法。

- 2018.02.27
- Aleksey Zinovik
- www.mql5.com
您可以用下面这段话来代替
顺便说一句,您的 if(OrderSend) 检查变量将始终有效。因为如果出现错误,OrderSend 不会返回 0。
谢谢,这样好多了(我忘记了空值)。我稍后会改正的
作者使用本地 MQL 工具,在不使用任何辅助工具的情况下,为 ML 的实施提供了一个很好的范例,在此向他表示敬意!
我唯一的意见是,将这个示例定位为强化学习。
首先,在我看来,强化学习应该对代理的记忆(即本例中的 RDF)产生剂量上的影响,但在本例中,强化学习只是对训练样本中的样本进行过滤,这实际上与教师为训练准备数据并无太大区别。
其次,训练本身并不是流式的、连续的,而是临时性的,因为在优化过程中,每次通过测试仪后,整个系统都要重新训练一次,我说的不是实时训练。
没错,这只是一个简单的粗粒度示例,其目的更多是为了让人们熟悉脚手架,而不是强化学习。我认为这个话题值得进一步探讨,并研究其他的强化方式。
信息量很大,谢谢!
首先,在我看来,强化应该对代理的记忆(即本例中的 RDF)进行剂量控制,但在这里,强化只是对训练样本进行过滤,这与使用教师进行学习的训练数据几乎没有什么区别。
其次,训练本身并不是流式的、连续的,而是一次性的,因为在优化过程中,每次通过测试仪后,整个系统都要重新训练一次,我说的不是实时训练。
我想对您的回答做一点补充。这两点是密切相关的。这个版本是经验重放主题的变体。这将不会不断更新表格,也不会重新训练森林(这将更加耗费资源),而只会在结束时对新的经验进行重新训练。也就是说,这是一种完全合法的强化变体,例如在 DeepMind 的Atari 游戏中就使用了这种变体,但在那里,一切都更加复杂,而且使用了迷你批次来对抗过拟合。
为了实现流式学习,最好能有一个具有额外学习能力的 NS,我正在考虑贝叶斯网络。如果您或任何人有关于贝叶斯网络的例子,我将不胜感激:)
同样,如果近似器没有重新训练的可能性,那么要进行实时更新,我就必须拖动过去状态的整个矩阵,而每次只对整个样本进行重新训练并不是一个非常优雅和缓慢的解决方案(随着状态和特征数量的增加)。
此外,我还想把 Q-phrase 和 NN 与 mql 结合起来,但我不明白为什么要使用 mql,并循环使用状态到状态的转换概率,而我可以像本文一样,仅限于通常的时差估计。因此,这里更适合使用行为批判。
我想对答案做一点补充。这两点密切相关。这个版本是经验重放主题的变体。它不会不断更新表格,也不会重新训练森林(这会耗费更多资源),而只会在新经验结束时重新训练。例如,DeepMind 在阿塔里 游戏中就使用了这种方法,但在那里,一切都更加复杂,而且使用迷你批次来防止过度拟合。
为了实现流式学习,最好能有一个具有额外学习能力的 NS,我正在考虑贝叶斯网络。如果您或其他人有关于贝叶斯网络的例子,我将不胜感激:)
同样,如果近似器没有重新训练的可能性,那么要进行实时更新,就必须拖动过去状态的整个矩阵,而每次只对整个样本进行重新训练并不是一个非常优雅和缓慢的解决方案(随着状态和特征数量的增加)。
此外,我还想将 Q-phrase 和 NN 与 mql 结合起来,但我不明白为什么要使用 mql 并循环使用状态到状态的转换概率,而我可以像本文一样,仅限于通常的时差估计。因此,"行为批判 "在这里更符合主题。
我并不认为,以批量学习为形式的经验再现变体是 RL 的合法实现,但它也证明了 RL 的一个主要缺点--长期学分分配。 因为其中的奖励(强化)是滞后发生的,这可能是低效的。
同时,另一个众所周知的缺点是违反了平衡--探索与探索,因为直到通道结束,所有的经验都只能被积累,而不能以任何方式用于当前的操作环节。因此,在我看来,没有流式学习的 RL 很可能不会有什么好事发生。
关于新的网络实例,如果我们谈论的是我在论坛上提到过的 P-net,那么它仍处于 NDA 状态,因此我无法分享源代码。从技术上讲,它当然有利也有弊,从积极的方面讲--学习速度快、可处理不同的数据对象、将来会有额外的训练,也许是 LSTM。
目前有一个 Python 库和本地 MT4 EA 生成器,都处于测试阶段。对于直接编码,有一种使用引擎内置的 Python 解释器的变体,您可以通过命名通道直接从 EA 传递代码块来使用它。
关于 RL 的纯 MQL 实现,我不知道,直觉上,它似乎应该在于决策树(策略树)的动态构建或 MLP 之间权重数组的操作,也许在 Alglib.... 中相应类的基础上进行修改。
干得好,米哈伊尔!你已经成功了20%。这是表扬,另外 3% 已经过去了。你的方向是正确的。
很多人在一个有 37 个指标的智能交易系统上增加了 84 个指标,然后认为 "现在肯定能用了"。太天真了。
现在进入正题。您只有机器和机器之间的对话。在我看来,您应该增加机器-人-机器的对话。
我来解释一下。在博弈论中,战略博弈具有以下属性:大量的随机因素、常规因素和心理因素。
心理因素就好比:有好电影,有坏电影,还有印度电影。你明白了吗?
如果你感兴趣,你会问下一步该怎么做,如何实现它吗?我会回答--我还不知道,我自己也在努力寻找答案。
但如果你只专注于汽车,那就会像 84 个指示器一样:加或不加,你都会绕圈子。
新文章 强化学习中的随机决策森林已发布:
使用 bagging 的随机森林(Random Forest, RF) 是最强大的机器学习方法之一, 它略微弱于梯度 boosting,这篇文章尝试开发了一个自我学习的交易系统,它会根据与市场的交互经验来做出决策。
之后,所有训练过的决策树被组合到一起,使用所有用本的平均误差来做简单投票。Bootstrap聚合的使用减少了均方误差,降低了训练分类器的方差。误差在不同的样本间不会相差太大。这样,根据作者的意见,模型将会较少有过度拟合的问题。bagging 方法的效果依赖于基本算法 (决策树) 是在随机变化的样本中训练的,它们的结果可能相差很大,而误差会在投票中大幅抵消。
可以说随机森林是 bagging 的一个特例,在其中决策树是用作基本单元的。同时,与传统的决策树构建方法不同,没有使用修剪(pruning),这种方法是为了整合大量数据样本的时候能够尽可能的快。每个数是使用特定方法创建的,用于构建树节点的特性 (属性) 不是从全部的特性中选择的,而是从它们的随机子集中选择的。当构建回归模型时,特性的数量是 n/3,如果是分类,它就是 √n. 所有这些都是经验的建议,被称为去相关:不同的特征集落入不同的树,并且树被训练在不同的样本上。
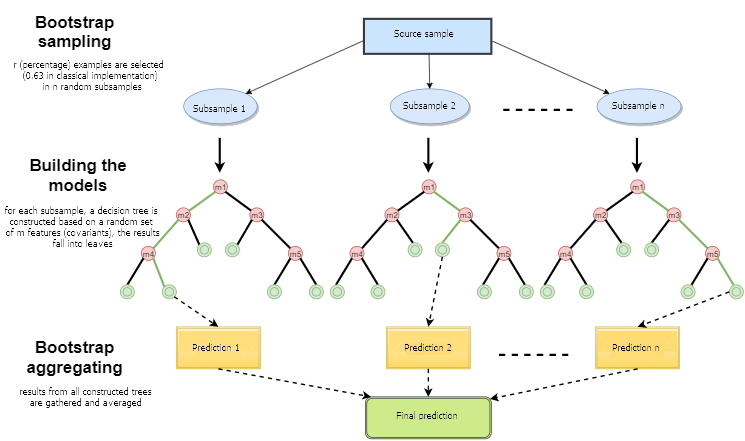
图 1. 随机森林运行框架作者:Maxim Dmitrievsky