文章 "生长型神经气:MQL5 中的实施"
看起来很酷)
但它到底是什么,如何使用,我还没有搞清楚。)
看起来很酷:)
但它到底是什么,如何使用,我们还需要进一步研究:)
可用作第一隐藏层--用于降维或聚类本身,可用于概率网络,还有很多其他选项。
感谢您提供的资料!
我会在闲暇时努力学习的 :)
感谢您发表新文章,介绍一种有趣的联网方法。如果你翻阅文献,会发现有几十种,甚至上百种。但交易者的问题不在于缺乏工具,而在于如何正确使用它们。如果文章能举例说明如何在智能交易系统中使用这种方法,那就更有意思了。

1.文章很好。文章以通俗易懂的方式呈现,代码并不复杂。
2.2. 这篇文章的不足之处包括没有提及网络的输入数据。 您本可以写几句话说明输入的内容--周期/指标数据的报价向量、价格偏差向量、归一化报价或其他。对于算法的实际使用,输入数据及其准备是关键。 我建议此类算法使用相对价格变化向量:x[i]=price[i+1]-price[i]。
此外,可以事先对输入向量进行归一化处理(x_normal[i]=x[i]/M),为此,可以使用考虑期间的价格最大偏差作为 M(此处和下文,为简洁起见,我不写变量声明):
M=x[ArrayMaximum(x)]-x[ArrayMinimum(x)];
在这种情况下,所有输入向量都将位于边长为 [-0.5,0.5] 的单位超立方体中,这将大大提高聚类的质量。您也可以使用标准正态偏差或其他任何平均变量,将期间内报价的相对偏差作为 M。
3.论文建议使用差值的平方准则作为神经元权重向量与输入向量之间的距离:
for(i=0, sum=0; i<m; i++, sum+=Pow(x[i]-w[i],2));
在我看来,这种距离函数在聚类任务中并不有效。更有效的方法是计算标量乘积或归一化标量乘积,即权重向量与输入向量之间夹角的余弦:
for(i=0, norma_x=0, norma_w=0; i<m; i++, norma_x+=x[i]*x[i], norma_w+=w[i]*w[i]); norma_x=sqrt(norma_x); norma_w=sqrt(norma_w); for(i=0, sum=0; i<m; i++, sum+=x[i]*w[i]); if(norma_x*norma_w!=0) sum=sum/(norma_x*norma_w);
这样,在每个聚类中,将根据振荡方向而不是振荡幅度,对彼此相似的向量进行分组,这将大大降低待解决问题的维度,并增加训练后神经网络权值分布的特征。
4.我们已经正确地认识到,有必要为训练网络确定一个停止标准。 停止标准应确定训练网络所需的簇数。而它的数量又取决于要解决的一般问题。例如,如果任务是预测未来 1-2 个样本的时间序列,并为此使用多层perseptron,那么簇的数量不应与perseptron 输入层的神经元数量相差太多。

一般来说,在最详细的分钟图(10 年*365 天*24 小时*60 分钟)上,历史条数不超过 530 万条。小时图上的历史记录为 87,000 条。也就是说,当每个报价向量都有自己独立的群集时,由于 "过度训练 "效应,创建群集数超过 10000-20000 的分类器是不合理的。
对于可能出现的错误,我深表歉意。
3. 我不明白这些公式的等价性在哪里。向量(x,w)/(|x|||w||)之间的夹角余弦的公式与|x-w|^ 2 "不太 "相似。对输入进行归一化并不能改变这些度量之间的根本差异:
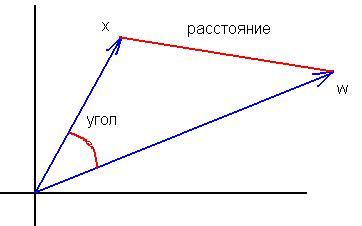
等价关系是距离的最大值总是对应于标量积的最小值,反之亦然。归一化矢量的关系是相互明确和单调的,因此计算距离的平方还是角度并不重要。
你好,亚历克斯、
谢谢你对这个问题的清晰解释。
能否分享一些实用的代码,用于重建未来价格,例如从最优信号重建未来价格。
我的想法是
1.输入(来源):多种货币(18 种)
2.目的地:我们想要预测的货币的最佳信号(图:2.Optimal_Signals)
3.找到来源和目的地之间的神经连接,并在交易中加以扩展。

另一个关于 NN 重构的问题:
是否可以使用我们的样本来代替随机样本?
我们的大脑可以在不到一秒的时间内重建图片,让我们看看 NN 做同样的事情需要多少时间,这只是一个玩笑,不是挑战。

随机生成的样本并不有趣,因为其背后没有任何意义或用途,但如果我们能自己画出有意义的点,那就有趣多了。)

新文章 生长型神经气:MQL5 中的实施已发布:
本文会举例说明如何开发一个可以实施名为“生长型神经气” (GNG) 自适应聚类算法的 MQL5 程序。本文针对已研究过语言文档、且已具备一定编程能力和神经信息学基础知识的用户。
作者:Алексей