또한 그래프의 다른 부분에 대해 신경망의 입력에 공급되는 샘플의 깊이가 달라야 합니다. 즉, 샘플링 깊이가 다른 신경망은 그래프의 다른 부분에서 다른 정확도를 갖습니다. 따라서 "올바른" 위원회는 전체 샘플 길이에 대해 올바르게 응답할 수 있습니다. 그리고 특히이위원회 자체가이 정확성을 결정합니다. 아마도 이것은 이미 AI의 기초 일 것입니다 ... :)
나는 5,10,20,50 만 행을 훈련하고 비교하고 모든 사람이 다른 결과를 가지고 다르게 거래합니다. 그것들을 함께 결합하는 것은 흥미로운 아이디어입니다. 평균을 내시나요? 일반적으로 서로 다른 거래 모델을 평균화하면 서로 모순되고 대다수가 동의 할 때만 거래가 덜 자주 시작됩니다.
흥미롭군요. 저는 5,10,20,50,000 라인에서 가르치고 비교하는데 모든 사람이 다른 결과로 다르게 거래합니다. 그것들을 함께 결합하는 것은 흥미로운 아이디어입니다. 평균을 내시나요? 일반적으로 거래 모델을 평균화하면 서로 모순되고 대부분의 모델이 동의 할 때만 거래 빈도가 줄어 듭니다.
5-10개의 모델이 어떻게 스스로 정확성을 판단할 수 있을까요? 평균을 말하는 건가요?
당신은 올바른 질문을합니다 !!! :)
하지만 이 비밀은 밝히지 않겠습니다. :) 그러나 한 가지 말씀 드리고 싶은 것은위원회의 결과 자체가이 네트워크 또는 해당 네트워크의 "정확성"을 결정한다는 것입니다. 평균화하지 않습니다.
글쎄요, 이것은 순전히 귀하의 시스템이며 제가 제공 한 데이터와는 아무런 관련이 없습니다. 분석에 다른 데이터를 사용하지 않았으므로 그렇죠?
이전에 훈련 한 모델을 적용하여 결과에 관심이있는 파일을 첨부하고 있습니다.
PR=183856 +거래량=693 -거래량=18
스프레드=0, 커미션=0에서.
그럼 유전학이 네트워크에 입력되는 데이터에 대한 책임이 있다는 건가요? 그리고 데이터 자체가 시계열 편향인가요?
나는 이미 첫 번째 질문에 대한 답을 썼습니다 ... :) 편견이 없습니다.
안부, 롬필.
또한 그래프의 다른 부분에 대해 신경망의 입력에 공급되는 샘플의 깊이가 달라야 합니다. 즉, 샘플링 깊이가 다른 신경망은 그래프의 다른 부분에서 다른 정확도를 갖습니다. 따라서 "올바른" 위원회는 전체 샘플 길이에 대해 올바르게 응답할 수 있습니다. 그리고 특히이위원회 자체가이 정확성을 결정합니다. 아마도 이것은 이미 AI의 기초 일 것입니다 ... :)
나는 5,10,20,50 만 행을 훈련하고 비교하고 모든 사람이 다른 결과를 가지고 다르게 거래합니다. 그것들을 함께 결합하는 것은 흥미로운 아이디어입니다. 평균을 내시나요?
일반적으로 서로 다른 거래 모델을 평균화하면 서로 모순되고 대다수가 동의 할 때만 거래가 덜 자주 시작됩니다.
5-10개의 모델이 어떻게 스스로 정확성을 판단할 수 있을까요? 평균을 말하는 건가요?
PR=183856 +거래=693 -거래=18
스프레드=0, 수수료=0에서.
이 데이터에 모델을 적용해 보시면 더 이상 고문하지 않겠습니다 :)
글쎄요, 이것은 순전히 귀하의 시스템이며 제가 제공 한 데이터와는 아무런 관련이 없습니다. 분석에 다른 데이터를 사용하지 않았으므로 그렇죠?
이전에 훈련 한 모델을 적용하여 결과에 관심이있는 파일을 첨부하고 있습니다.
결과적으로 어떤 데이터는 중요하지 않습니다 ...
실제로이 알고리즘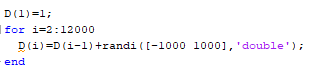 에 의해 형성된 그래프는 다음과 같습니다 (그리고 각 실행에서 알려진 이유로 다른 그래프를 얻습니다):
에 의해 형성된 그래프는 다음과 같습니다 (그리고 각 실행에서 알려진 이유로 다른 그래프를 얻습니다):
훈련 샘플 첫 번째 10000 값, 나머지 2000은 테스트입니다.
결과는 다음과 같습니다:
PR=406206 +거래=299 -거래=34
이것이 이야기의 끝입니다. 모든 최고와 꿈이 이루어집니다.
안부, 롬필.
이 데이터에 모델을 다시 적용해 보시면 더 이상 고문하지 않겠습니다 :)
PR=116823 +trades=977 -trades=16
첫 번째 질문에 대한 답변은 이미 작성되었습니다 ... :) 오프셋이 없습니다.
안부, RomFil.
당신은 자신이 " 예, 거의 순수한 값, 다른 깊이, 다른 창 등 ".
결과는 이것입니다:
PR=406206 +거래=299 -거래=34
차트에 2000 개의 신호가 있지만 설명에 333 개가 있거나 다시 이해하지 못합니다....
좋아, 이것이 마지막 샘플의 차트라면 EURUSD에서 훈련 된 모델이 십자가를 포함한 3 가지 통화 상품에서 완벽하게 작동한다는 것이 밝혀졌습니다. 노벨상을 받을 때가 된 것 같네요!
이것이 이야기의 끝입니다. 모든 최고와 꿈이 이루어집니다.
안부, 롬필.
흥미로운 저녁을 보내 주셔서 감사합니다.
PR=116823 +거래=977 -거래=16
충격, 충격.
실제로 이 알고리즘에 의해 생성된 그래프는 다음과 같습니다(실행할 때마다 잘 알려진 이유로 다른 그래프를 얻게 됩니다):
임의의 그래프와 그것에 대한 훈련?
흥미롭군요.
저는 5,10,20,50,000 라인에서 가르치고 비교하는데 모든 사람이 다른 결과로 다르게 거래합니다. 그것들을 함께 결합하는 것은 흥미로운 아이디어입니다. 평균을 내시나요?
일반적으로 거래 모델을 평균화하면 서로 모순되고 대부분의 모델이 동의 할 때만 거래 빈도가 줄어 듭니다.
5-10개의 모델이 어떻게 스스로 정확성을 판단할 수 있을까요? 평균을 말하는 건가요?
당신은 올바른 질문을합니다 !!! :)
하지만 이 비밀은 밝히지 않겠습니다. :) 그러나 한 가지 말씀 드리고 싶은 것은위원회의 결과 자체가이 네트워크 또는 해당 네트워크의 "정확성"을 결정한다는 것입니다. 평균화하지 않습니다.