L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 851
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
2 classi
Caricato 1 nucleo
Impostazione, rfeControl = rfeControl(numero = 1,ripetizioni = 1) - tempo ridotto a 10-15 minuti. Cambiamenti nei risultati - 2 coppie di predittori scambiati, ma nel complesso simile a quello che era il default.
Beh, ecco, i tuoi 10 minuti su un nucleo sono i miei 2 su 4, e due minuti che non ricordo.
Non aspetto mai qualcosa per ore, se 10-15 minuti non hanno funzionato, allora c'è qualcosa che non va, quindi spendere più tempo non servirà a niente. Qualsiasi ottimizzazione quando si costruisce un modello che dura ore è un fallimento totale nel comprendere l'ideologia della modellazione, che dice che il modello dovrebbe essere il più grezzo possibile e in nessun caso il più accurato possibile.
Ora sulla selezione dei predittori.
Perché lo stai facendo e perché? Quale problema sta cercando di risolvere?
La cosa più importante nella selezione è cercare di risolvere il problema della riqualificazione. Se no, la selezione può accelerare l'apprendimento riducendo il numero di predittori. Ma ridurre il numero è molto più efficiente isolando le componenti principali. Non influenzano nulla, ma possono ridurre il numero di predittori di un ordine di grandezza e di conseguenza aumentare la velocità di adattamento del modello.
Quindi, per cominciare: perché ne avete bisogno?
Ho trovato un altro pacchetto interessante per setacciare i predittori. Si chiama FSelector. Offre circa una dozzina di metodi per setacciare i predittori, compresa l'entropia.
Ho preso un file con predittori e un obiettivo da qui -https://www.mql5.com/ru/forum/86386/page6#comment_2534058
La valutazione del predittore per ogni metodo che ho mostrato nel grafico alla fine.
Il blu è buono, il rosso è cattivo (per il corrplot i risultati sono stati scalati a [-1:1], per la valutazione esatta vedere i risultati di cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable), ecc.)
Puoi vedere che X3, X4, X5, X19, X20 sono ben valutati da quasi tutti i metodi, puoi iniziare con loro, poi provare ad aggiungere/rimuovere altro.
Tuttavia, i modelli in rattle hanno fallito il test con questi 5 predittori su Rat_DF2, di nuovo nessun miracolo. Cioè, anche con i predittori rimanenti devi regolare i parametri del modello, fare la validazione incrociata, aggiungere/rimuovere i predittori da solo.
Ho fatto la stessa cosa con CORElearn usando i dati degli articoli di Vladimir.
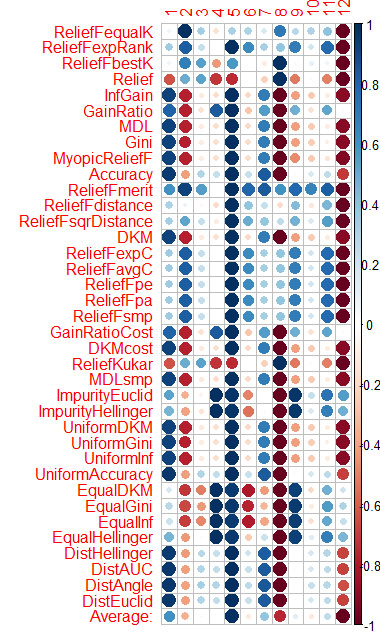
Ho calcolato la media delle colonne (la riga inferiore è Media) e l'ho ordinata in base ad essa. È più facile percepire l'importanza totale in questo modo.
Ci sono voluti 1,6 minuti - e sono 37 algoritmi lavorati. La velocità è molto meglio di Caret (16 minuti), con risultati simili.
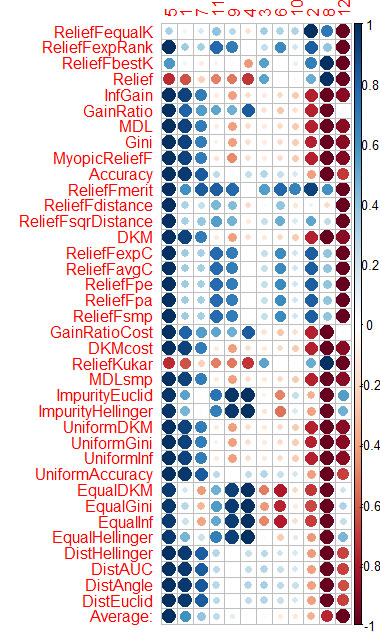
Ho fatto la stessa cosa con CORElearn usando i dati degli articoli di Vladimir.
Ho calcolato la media per colonne (la media della riga inferiore) e l'ho ordinata. È più facile percepire l'importanza totale in questo modo.
Ci sono voluti 1,6 minuti e 37 algoritmi.
Allora, qual è il risultato finale? Hai risposto alla domanda sull'importanza dei predittori o no, perché non capisco un po' queste immagini.
Per me ora non c'è nessun problema quando costruisco e seleziono un modello, seleziono i predittori, poi costruisco 10 modelli su di essi, poi l'informazione reciproca seleziona quello che funziona meglio. Sai come si fa? È una sfida mentale!!! Va bene, chi lo risolve è il migliore !!!!!
Sono riuscito a ottenere un set di modelli. E in realtà vporez: quale dei modelli sta funzionando e perché??????
O meglio, funzionano tutti, ma solo uno di loro può comporre. E spiegare perché?
Allora, qual è il risultato finale? Hai risposto alla domanda sull'importanza dei predittori o no, perché non capisco un po' queste immagini.
Per me ora non c'è nessun problema quando costruisco e seleziono un modello, seleziono i predittori, poi costruisco 10 modelli su di essi, poi l'informazione reciproca seleziona quello che funziona meglio. Sai come si fa? È una sfida mentale!!! Va bene, chi lo risolve è il migliore !!!!!
Sono riuscito a ottenere un set di modelli. E in realtà vporez: quale dei modelli sta funzionando e perché??????
O meglio, funzionano tutti, ma solo uno di loro può comporre. E spiegare perché?
Vtreat ordina i predittori in modo molto simile (importante prima)
5 1 7 11 4 10 3 9 6 2 12 8
Ed ecco l'ordinamento per media in CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
Non credo che mi preoccuperò con altri pacchetti di selezione dei predittori.
Quindi Vtreat è sufficiente. Solo che l'interazione dei predittori non è presa in considerazione. Probabilmente anche.
Sono in lacrime quando vedo che continuate a prendere in considerazione l'importanza dei predittori per alcuni pezzi di storia del mercato. Perché è una profanazione dei metodi statistici.
Verificato in pratica che se il predittore numero 2 è alimentato nel NS - l'errore sale dal 30% a quasi il 50%
e sull'OOS, come cambia l'errore?
Come cambia l'errore sull'OOS?
allo stesso modo. Come negli articoli di Vladimir - i dati provengono da lì.
e se è su un altro OOS?
In pratica, ho verificato che se si alimenta il predittore numero 2 al NS, l'errore sale dal 30% a quasi il 50%.
Sputa i predittori e alimenta la serie temporale normalizzata al NS. Il NS troverà da solo i predittori - +1-2 strati, ed ecco fatto