Que mettre à l'entrée du réseau neuronal ? Vos idées... - page 37
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Je suppose qu'il s'agit du résultat sans filtre, par exemple, par heure ?
Hmm... Je n'ai bien sûr pas testé avec des filtres, mais le fait est que les transactions sont à moyen terme ou intrajournalières.
L'influence du filtre temporel ne semble pas être très forte. Mais, dans tous les cas, c'est possible, bien sûr.
Hmm... Je n'ai pas testé avec des filtres, mais le fait est que les transactions sont à moyen terme ou intrajournalières.
L'influence du filtre temporel ne semble pas être forte. Mais, dans tous les cas, vous pouvez, bien sûr, le faire.
Un phénomène intéressant :
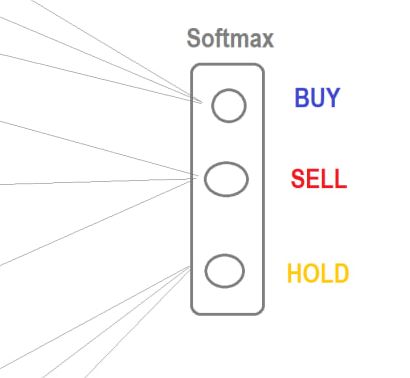
Si vous utilisez la même architecture (n'importe quelle architecture), alors sur EURUSD, lorsque vous utilisez Softmax, l'optimisation donne toujours des ensembles supérieurs où BUY n'est pas du tout utilisé. Tout ne tient qu'à SELL et HOLD.
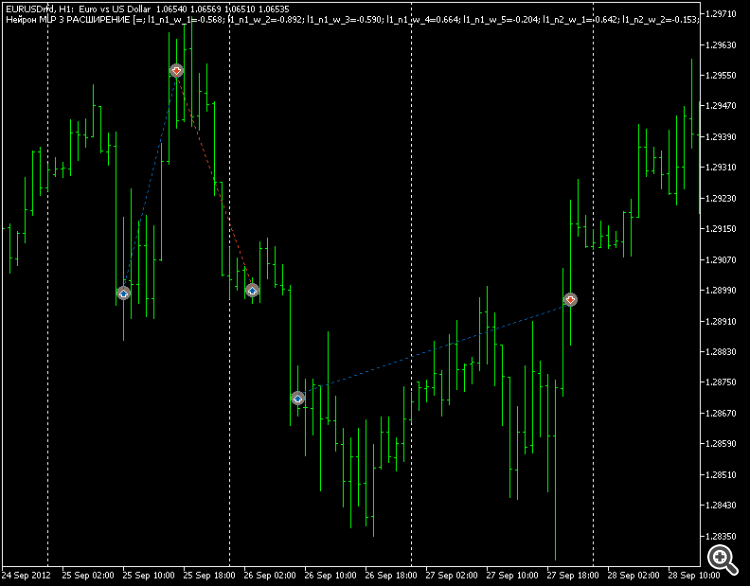
Je regarde le graphique sur 12 ans - il est descendant. En d'autres termes, l'optimiseur MT5 ajuste les pondérations au niveau macro pour les adapter au long terme.
Par conséquent, les zones de tendance haussière de type BUY-eval restent "non négociées" correctement, mais si vous utilisez une tangente régulière comme sortie, il n'y a pas de problème.
Les top sets se négocient à la fois à l'achat et à la vente. J'ai donc abandonné ce softmax, et je me penche maintenant sur les architectures et les entrées uniquement avec la tangente. UPD Autre chose - les transactions se font à la hausse et à la baisse.
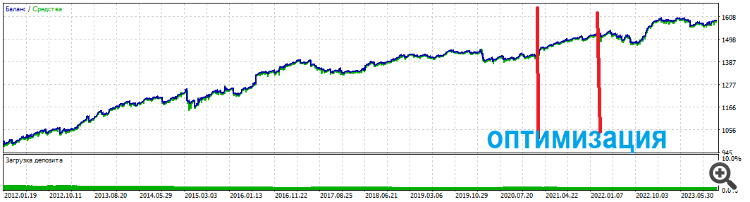
Et les top sets tiennent longtemps
Phénomène intéressant :
...
Et les ensembles supérieurs durent longtemps
Architecture MLP ? Je suppose que les poids sont optimisés par l'optimiseur interne ? Quel est le critère d'optimisation, s'il n'est pas secret ? Et si le même maillage, mais avec un algo backprope, toutes choses égales par ailleurs ?
Architecture MLP ? Si j'ai bien compris, les poids sont optimisés par l'optimiseur interne ? Quel est le critère d'optimisation, s'il n'est pas secret ? Et si la même grille, mais avec un algorithme de rétropropagation, est utilisée toutes choses égales par ailleurs ?
Et les ensembles supérieurs durent longtemps
Et si, en plus, vous entraîniez à nouveau le deuxième modèle ?
Que se passe-t-il si vous entraînez à nouveau le deuxième modèle de manière excessive ?
Veuillez préciser dans le contexte d'un optimiseur MT5 normal et d'un EA normal. Comment cela se passerait-il ? Prenez deux ensembles de la liste d'optimisation (non corrélés), combinez-les et exécutez-les ? Ou avez-vous une autre idée en tête ?
Trop de mots savants
Les experts de la branche MO affirment que : 1. Il n'est pas possible de rechercher un extremum global sur une fonction d'aptitude.
2. les algorithmes d'optimisation par recherche globale (l'AG standard en fait partie) ne conviennent pas aux réseaux neuronaux ; il faut utiliser toutes sortes de retours de gradient pour cela.
En bref, à première vue, vous faites tout de travers (selon les idées des experts de la branche MO).
Les experts de la branche MO soutiennent que : 1. Il n'est pas possible de rechercher un extremum global sur la fonction d'aptitude.
2. les algorithmes d'optimisation par recherche globale (y compris l'AG standard) ne conviennent pas aux réseaux neuronaux ; il convient d'utiliser toutes sortes de retours de gradient à cette fin.
En bref, à première vue, vous faites tout de travers (selon les idées des experts de la branche MO).
Je vais donc gagner cette bataille
Alors je gagnerai cette bataille