MQL5 Cookbook: Implementing an Associative Array or a Dictionary for Quick Data Access
Vasiliy Sokolov | 2 June, 2015
Table Of Contents
- INTRODUCTION
- CHAPTER 1. DATA ORGANIZATION THEORY
- CHAPTER 2. ASSOCIATIVE ARRAY ORGANIZATION THEORY
- CHAPTER 3. PRACTICAL DEVELOPMENT OF AN ASSOCIATIVE ARRAY
- CHAPTER 4. TEST AND EVALUATION OF PERFORMANCE
- CHAPTER 5. CDICTIONARY CLASS DOCUMENTATION
- CONCLUSION
Introduction
This article describes a class for convenient storage of information, namely an associative array or a dictionary. This class allows to gain access to information by its key.
The associative array resembles a regular array. But instead of an index it uses some unique key, for example, ENUM_TIMEFRAMES enumeration or some text. It does not matter what represents a key. It's uniqueness of the key that matters. This data storage algorithm significantly simplifies many programming aspects.
For example, a function, which would take an error code and print a text equivalent of the error, could be as follows:
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
We will look into specific features of this code later.
Before treating a straight description of associative array internal logic, we will consider details of two main methods of data storage, namely arrays and lists. Our dictionary will be based on these two data types, that is why we should have a good understanding of their specific features. Chapter 1 is dedicated to description of data types. The second chapter is devoted to description of the associative array and methods of working with it.
Chapter 1. Data Organization Theory
1.1. Data organization algorithm. Searching the best data storage container
Search, storage and representation of information are the main functions imposed on modern computers. Human-computer interaction usually includes either search for some information or creation and storage of information for further use. Information is not an abstract concept. In a real sense, there is a certain concept underneath this word. For example, a symbol quotation history is a source of information for any trader who makes or is going to make a deal on this symbol. Programming language documentation or a source code of some program can serve as a source of information for a programmer.
Some graphic files (for example, a picture made with a digital camera) can be a source of information for people unrelated to programming or trading. It is evident that these types of information have different structures and their own nature. Consequently, algorithms of storage, representation and processing this information will differ.
For example, it is easier to present a graphic file as a two-dimensional matrix (two-dimensional array) each element or cell of which will store information about color of a small image area — pixel. Quotation data have another nature. Essentially, this is a stream of homogeneous data in OHLCV format. It is better to present this stream as an array or an ordered sequence of structures which is a certain type of data in the programming language combining several data types. Documentation or a source code is usually represented as plain text. This data type can be defined and stored as an ordered sequence of strings, where each string is an arbitrary sequence of symbols.
Type of a container to store data depends on the data type. Using terms of object-oriented programming, it's easier to define a container as a certain class which stores these data and has special algorithms (methods) of manipulating them. There are several types of such data storage containers (classes). They are based on different data organization. But some data organization algorithms allow to combine different data storage paradigms. Thus we can take advantage of combining benefits of all storage types.
You select one or another container to store, process and receive data depending on a supposed method of their manipulation and their nature. It is important to realize that there are no equally efficient data containers. Weaknesses of one data container are the reverse side of its advantages.
For example, you can rapidly gain access to any of the array elements. However, a time-consuming operation is required for inserting an element in a random array spot, as full array resize is demanded in that case. And conversely, inserting an element in a singly-linked list is an effective and high-speed operation, but accessing a random element may take a lot of time. If necessary to insert new elements on frequent occasions, but you do not need frequent access to these elements, the singly-linked list will be your right container. And choose an array as a data class if frequent access to random elements is required.
In order to understand which data storage type is preferable, you should be familiar with arrangement of any given container. This article is devoted to the associative array or the dictionary — a specific data storage container based on combination of an array and a list. But I would like to mention that the dictionary can be implemented in different ways depending on a certain programming language, its means, capabilities and accepted programming rules.
For example, C# dictionary implementation differs from C++. This article does not describe adapted implementation of the dictionary for С++. Described version of the associative array has been created from scratch for the MQL5 programming language and considers its special features and common programming practice. Though their implementation differs, dictionaries' general characteristics and methods of operation should be similar. In this context, the described version fully exhibits all these characteristics and methods.
We will be gradually creating the dictionary algorithm and discoursing upon nature of data storage algorithms in the meantime. And at the end of the article we will have a complete version of the algorithm and be fully aware of its operation principle.
There are no equally efficient containers for different data types. Let us consider a simple example: a paper notebook. It can also be considered as a container/class used in our everyday life . All its notes are entered according to a preliminarily made list (alphabet in this case). If you know a subscriber name, you can easily find his or her phone number, as you just need to open the notebook.
1.2. Arrays and data direct addressing
An array is the simplest and at the same time the most effective way to store information. In programming, an array is a collection of the same type elements, located immediately one after another in the memory. Due to these properties we can calculate the address of each element of the array.
Indeed, if all elements have the same type, they all will have the same size. As array data are located continually, we can calculate an address of a random element and refer directly to this element if we know a basic element's size. A general formula for calculating the address depends on a data type and an index.
For example, you can calculate an address of the fifth element in the array of the uchar type elements using following general formula coming out of properties of the array data organization:
random element address = the first element address + (index of random element in the array * array type size)
Array addressing starts from zero, that is why the first element's address corresponds to the address of the array element having index 0. Consequently, the fifth element will have index 4. Let us assume that the array stores uchar type elements. This is the basic data type in many programming languages. For instance, it is present in all C-type languages. MQL5 is no exception. Each element of the uchar type array occupies 1 byte or 8 bits of memory.
For example, according to the previously mentioned formula the fifth element address in the uchar array will be as follows:
the fifth element address = the first element address + (4 * 1 byte);
In other words, the firth element of the uchar array will be 4 bytes higher than the first element. You can refer to each array element directly by its address during program execution. Such address arithmetic enables to gain really fast access to each array element. But such data organization has disadvantages.
One of them is that you cannot store elements of different types in the array. Such limitation is the consequence of direct addressing. Surely, different data types vary in sizes, which means that calculating an address of a certain element using the above mentioned formula turns to be impossible. But this limitation can be smartly overcome, if the array stores not elements but pointers to them.
It will be the easiest way if you represent a pointer as a link (as shortcuts in Windows). The pointer refers to a certain object in the memory, but the pointer itself is not an object. In MQL5 the pointer can refer to a class only. In object-oriented programming, a class is a particular data type which can include an arbitrary set of data and methods and be created by a user for effective program structuring.
Every class is a unique user-defined data type. Pointers referring to different classes cannot be located in one array. But regardless the referred class, the pointer always has the same size, as it contains only an object address in the operating system's address space which is common for all allocated objects.
1.3. Concept of the node by the example of the CObjectCustom simple class
Now we know enough to design our first universal pointer. The idea is to create a universal pointer array where each pointer would refer to its particular type. Actual types would be different, but owing to the fact that they are referred to by the same pointer, these types could be stored in one container/array. Let us create the first version of our pointer.
This pointer will be represented by the simplest type which we'll name CObjectCustom:
class CObjectCustom
{
};
It would be really hard to invent a class simpler than CObjectCustom, as it does not contain any data or methods. But such implementation is enough for the time being.
Now we will use one of the main concepts of object-oriented programming — inheritance. Inheritance provides a special way of establishing the identity between objects. For example, we can tell a compiler that any class is a derivative of CObjectCustom.
For example, a class of human beings (СHuman), a class of Expert Advisors (CExpert) and a class of weather (CWeather) represent more general concept of the CObjectCustom class. Perhaps these concepts are not actually connected in the real life: weather has nothing in common with people, and Expert Advisors are not associated with weather. But this is us who set up links in the programming world, and if these links are good for our algorithms, there's no reason why we cannot create them.
Let's create some more classes in the same manner: a car class (CCar), a number class (CNumber), a price bar class (CBar), a quotation class (CQuotes), a MetaQuotes company class (CMetaQuotes), and a class describing a ship (CShip). Similar to previous classes, these classes are not actually connected, but they all are descendant of the CObjectCustom class.
Let us create a class library for these objects combining all these classes in one file: ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
Now it is about time to combine these classes into one array.
1.4. Node pointer arrays by the example of the CArrayCustom class
To combine classes, we will need a special array.
In the simplest case it will be enough to write:
CObjectCustom array[];
This string creates a dynamic array which stores CObjectCustom-type elements. Owing to the fact that all classes, which we defined in the previous section, are derived from CObjectCustom, we can store any of these classes in this array. For example, we can locate people, cars and ships there. But declaration of the CObjectCustom array won't be enough for this purpose.
The thing is that when we declare the array in the normal way, all its elements are filled automatically at the moment of array initialization. Thus, after we declare the array, all its elements will be occupied by the CObjectCustom class.
We can check this out if we slightly modify CObjectCustom:
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
Let's run a test code as a script to check this peculiarity:
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
In the OnStart() function we initialized an array consisting of three elements of CObjectCustom.
Compiler filled this array with corresponding objects. You can check it if you read the terminal's log:
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #2 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #1 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #0 - CObjectCustom
That means that the array is filled by the compiler, and we cannot locate any other elements there, for example CWeather or CExpert.
This code will not be compiled:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
The compiler will give an error message:
'=' - structure have objects and cannot be copied Test.mq5 18 13
That means that the array already has objects and new objects cannot be copied there.
But we can break through this impasse! As mentioned above, we should work not with objects but with pointers to these objects.
Rewrite the code in the OnStart() function in such a way that it could work with pointers:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
Now the code is compiled and errors do not occur. What has happened? Firstly, we have replaced the CObjectCustom array initialization with initialization of the array of pointers to CObjectCustom.
In this case the compiler does not create new CObjectCustom objects when initializing the array but leaves it empty. Secondly, now we use a pointer to the CWeather object instead of the object itself. Using the keyword new we created the CWeather object and assigned it to our pointer 'weather', and then we have put the pointer 'weather' (but not the object) in the array.
Now let's put the rest of objects in the array in a similar vein.
For this purpose write the following code:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
This code will work, but it is pretty risky as we directly manipulate the array's indexes.
If we miscalculate about the size of our arrayObj array or address by a wrong index, our program will end up with a critical error. But this code suits our demonstration purposes.
Let's present these elements as a scheme:
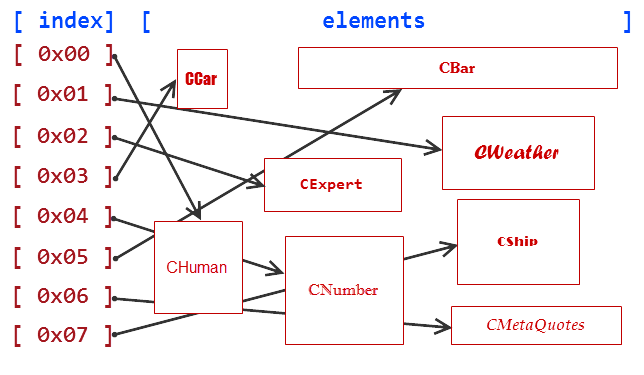
Fig. 1. Scheme of data storage in the pointer array
Elements, created by the operator 'new', are stored in a special part of the random access memory which is called a heap. These elements are unordered as can be clearly seen on the above scheme.
Our arrayObj pointer array has strict indexing, which enables to gain quick access to any element using its index. But gaining access to such element will not be enough, as the pointer array does not know to which particular object it points. The CObjectCustom pointer can point to CWeather or CBar, or CMetaQuotes, as they all are CObjectCustom. So explicit cast of an object to its actual type is required for getting the element type.
For example, it can be done as follows:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
In this code we created the CHuman object and placed it in the arrayObj array as CObjectCustom. Then we extracted CObjectCustom and converted it into CHuman, which is actually the same. In the example conversion had no errors as we remembered the type. In real programming situation it is very difficult to track a type of every object as there may be hundreds of such types and number of objects may be over a million.
That is why we should furnish the ObjectCustom class with additional Type() method which returns a modifier of an actual object type. A modifier is a certain unique number which describes our object allowing to refer to the type by its name. For example, we can define modifiers using preprocessor directive #define. If we know the object type specified by the modifier, we can always safely convert its type to the actual one. Thus, we came close to creation of safe types.
1.5. Check and safety of types
As soon as we start converting one type into another, safety of such conversion becomes a cornerstone of programming. We would not like if our program ends up with a critical error, wouldn't we? But we already know what will be the safety basis for our types — special modifiers. If we know the modifier we can convert it into a required type. For this purpose we need to supplement our CObjectCustom class with several additions.
First of all, let's create type identifiers to refer to them by name. For this purpose we will create a separate file with required enumeration:
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip
Now we will change class codes adding CObjectCustom to the variable which stores object type as a number. Hide it in the private section, so nobody can change it.
Beside that, we will add a special constructor available for classes derived from CObjectCustom. This constructor will allow objects to designate their type during creation.
The common code will be as follows:
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
As we can see, every type derived from CObjectCustom now sets its own type in its constructor during creation. The type can not be changed once it is set, as the field, where it is stored, is private and available only for CObjectCustom. That will prevent you from wrong type manipulation. If the class does not call protected constructor CObjectCustom, its type - TYPE_OBJECT - will be the default type.
So, it is time to learn how to extract types from arrayObj and process them. For this purpose we will furnish CHuman and CWeather classes with public Run() and Temp() methods correspondingly. After we extract the class from arrayObj, we will convert it into required type and start working with it in a proper way.
If the type, stored in the CObjectCustom array, is unknown, we will ignore it writing a message "unknown type":
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
This code will display the following message:
2015.02.13 15:11:24.703 Test (USDCHF,H1) unknown type.
2015.02.13 15:11:24.703 Test (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Test (USDCHF,H1) Human run...
So, we have obtained the looked-for result. Now we can store any types of objects in the CObjectCustom array, get quick access to these objects by their indexes in the array and correctly convert them to their actual types. But we still lack of many things: we need correct deletion of objects after program termination, as we have to delete objects located in the heap by ourselves using the delete operator.
Furthermore, we require means of safe array resize if the array is fully filled. But we are not going to recreate the wheel. The standard MetaTrader 5 set of tools includes classes which implement all these features.
These classes are based on the universal CObject container/class. Similarly to our class, it has the Type() method, which returns the actual type of the class, and two more important pointers of the CObject type: m_prev and m_next. Their purpose will be described in the next section where we will discuss another method of data storage, namely a doubly-linked list, through the example of the CObject container and the CList class.
1.6. The CList class as an example of a doubly-linked list
An array with elements of arbitrary type suffers from only one major flaw: it takes a lot of time and effort if you want to insert a new element, especially if this element has to be inserted in the middle on the array. Elements are located in a sequence, so for inserting you are required to resize the array to increase the total number of elements by one and then to rearrange all elements which follow the inserted object so as their indexes correspond to their new values.
Let us assume that we have an array consisting of 7 elements and want to insert one more element in the fourth position. An approximate insertion scheme will be as follows:

Fig. 2. Array resize and insertion of a new element
There is a data storage scheme which provides fast and effective insertion and deletion of elements. Such scheme is called a singly-linked or a doubly-linked list. The list reminds an ordinary queue. When we are in a queue we only need to know a person we follow (we do not need to know a person who is standing before him or her). We also do not need to know a person standing after us, as this person must control his or her queue position.
A queue is a classic example of a singly-linked list. But lists can also be doubly-linked. In this case every person in a queue knows not only a person before but also a person after him or her. So if you inquire each person, you can move in both direction of the queue.
Standard CList available in the Standard Library offers precisely this algorithm. Let's try to make a queue out of already known classes. But this time they will derive from standard CObject and not from CObjectCustom.
This can be schematically shown as follows:

Fig. 3. Scheme of a doubly-linked list
So this is a source code which creates such scheme:
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
Our classes now have two pointers from CObject: one makes reference to the previous element, the other one — to the next element. The pointer to the previous element of the first element in the list is equal to NULL. The element at the end of the list has a pointer to the next element which is also equal to NULL. So we can enumerate elements one by one thereby enumerating the whole queue.
EnumerateAll() and ReverseEnumerateAll() functions perform enumeration of all elements in the list.
The first one enumerates the list from beginning to end, the second one - from end to beginning. The source code of these functions is as follows:
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
How does this code work? In fact, it's quite simple. At the beginning we get a reference to the first node in the EnumerateAll() function. Then we print a sequence number of this node in the for loop and move to the next node using the command node = node.Next(). Do not forget to iterate the element's current index by one (i++). Enumeration keeps going until the current node is equal to NULL. The Code in the second block of for is responsible for that: node != NULL.
The reverse version of this function ReverseEnumerateAll() behaves similarly with the only difference that at first it gets the last element of the list CObject* node = list.GetLastNode(). In the for loop it gets not the next, but the previous element of the list node = node.Prev().
After launching the code we will receive the following message:
2015.02.13 17:52:02.974 TestList (USDCHF,D1) enumerate complete.
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) <<< enumerate from end to begin <<<
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) >>> enumerate from begin to end >>>
You can easily insert new elements in the list. Just change pointers of the previous and the next elements in such way that they would refer to a new element, and this new element would refer to the previous and the next objects.
The scheme looks easier than it sounds:

Fig. 4. Insertion of a new element in a doubly-linked list
The main disadvantage of the list is impossibility of referencing each element by its index.
For example, if you want to refer to CExpert as shown in Fig. 4, first you have to gain access to CCar, and after this you can move to CExpert. The same is the case for CWeather. It is closer to the end of the list, so it will be easier to gain access from the end. For this purpose you have to refer to CShip first, and then to CWeather.
Moving by pointers is a slower operation comparing to direct indexing. Modern central processing units are optimized for operation particularly with arrays. That is why in practice arrays might be more preferable even if lists potentially shall work faster.
Chapter 2. Associative Array Organization Theory
2.1. Associative arrays in our day-to-day life
We permanently face associative arrays in our day-to-day life. But they seem us so obvious that we perceive them as a matter of course. The simplest example of the associative array or the dictionary is a usual phone book. Each phone number in the book is associated with a name of a certain person. The person's name in such book is a unique key, and phone number is a simple numeric value. Every person in the phone book can have more than one phone number. For example, a person can have home, mobile and business phone numbers.
Generally speaking, there can be an unlimited quantity of numbers, but the person's name is unique. For example, two persons named Alexander in your phone book will confuse you. Sometimes we may dial a wrong number. That is why keys (names in this case) must be unique to avoid such situation. But at the same time the dictionary must know how to resolve collisions and be resistant to them. Two identical names will not destroy the phone book. So our algorithm should know how to process such situations.
We use several types of dictionaries in the real life. For example, the phone book is a dictionary where a unique line (subscriber name) is a key, and a number is a value. Foreign term dictionary has another structure. An English word will be a key, and its translation will be a value. Both these associative arrays are based on the same methods of data handling, that is why our dictionary must be multipurpose and allow to store and compare any types.
In programming, it is also may be convenient to create your own dictionaries and "notebooks".
2.2. Primary associative arrays based on the switch-case operator or a simple array
You can easily create a simple associative array. Just use standard tools of the MQL5 language, for example, the switch operator or an array.
Let's look at such code closer:
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
In this case the switch-case operator acts like a dictionary. Each value of ENUM_TIMEFRAMES has a string value describing this period. Owing to the fact that the switch operator is a switched passage (in Russian), access to required variant of case is instant, and other variants of case are not enumerated. That is why this code is highly efficient.
But its disadvantage is that, first, you have to fill all values, which have to be returned with one or another value of ENUM_TIMEFRAMES, manually. Second, switch can operate only with integer values. But it would be harder to write a reverse function which could return the time frame type depending on a transferred string. The third disadvantage of such approach is that this method is not flexible enough. You should specify all possible variants in advance. But you are often required to fill values in the dictionary dynamically as new data become available.
The second "frontal" method of 'key-value' pair storage involves creating an array where a key is used as an index, and a value is an array element .
For example, let us try to solve the similar task, namely to return timeframe string representation:
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
This code depicts reference by index where ENUM_TIMFRAMES is specified as an index. Before returning the value, the function checks if the array is filled with a required element. If not, the function delegates filling to a special function - InitTimeframes(). It has the same disadvantages as the switch operator.
Moreover, such dictionary structure requires initialization of an array with large values. Thus value of the PERIOD_MN1 modifier is 49153. It means that we need 49153 cells to store only nine time frames. Other cells stay unfilled. This method of data allocation is far from being a compact one, but it might be appropriate when enumeration consists of a small and successive range of numbers.
2.3. Conversion of base types into a unique key
As algorithms used in the dictionary are similar regardless certain types of keys and values, we need to perform data alignment, so as different data types could be processed by one algorithm. Our dictionary algorithm will be universal and allow to store values where any basic type can be specified as a key, for example int, enum, double or even string.
Actually, in MQL5 any basic data type can be represented as some unsigned ulong number. For example, short or ushort data types are "short" versions of ulong.
With express understanding that the ulong type stores the ushort value, you can always make safe explicit type conversion:
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)
The same is the case for char and int types and their unsigned analogues, as ulong can store any type, size of which is less or equal to ulong. Datetime, enum and color types are based on integer 32-bit uint number, which means that they can be safely converted into ulong. The bool type possesses only two values: 0, which means false, and 1, which means true. Thus, values of the bool type can also be stored in the ulong type variable. Besides, a lot of MQL5 system functions are based on this feature.
For example, the AccountInfoInteger() function returns the integer value of the long type, which can also be an account number of the ulong type and a Boolean value of permission to trade - ACCOUNT_TRADE_ALLOWED.
But MQL5 has three basic types which stand apart from integer types. They cannot be directly converted to the integer ulong type. Among these types are floating points types, such as double and float, and strings. But some simple actions can convert them to unique integer keys/values.
Each floating point value can be set out as some base raised to an arbitrary power, where both the base and the power are stored separately as an integer value. That sort of storage method is used in double and float values. The float type uses 32 digits to store mantissa and power, the double type uses 64 digits.
If we try to convert them directly to the ulong type, a value will be simply rounded. In this case 3.0 and 3.14159 will give the same ulong value — 3. This is inappropriate for us, as we will need different keys for these two different values. One uncommon feature, which can be used in C-type languages, comes to the rescue. It is called structure conversion. Two different structures can be converted if they have one size (converting one structure to another).
Let's analyze this example on two structures one of which stores the ulong type value, and another stores the double type value:
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
This code copies the DoubleValue structure in the ULongValue structure byte by byte. As they have the same size and order of variables, the double value of dValue.value is byte-by-byte copied to the ulong variable of lValue.value.
After that this variable value is printed out. If we change dValue.value to 3.14160, lValue.value will also be changed.
Here is the result which will be displayed by the printf() function:
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
The float type is a short version of the double type. Accordingly, before converting the float type to the ulong type you can safely extend the float type to double:
float fl = 3.14159f; double dbl = fl;
After that convert double to the ulong type via structure conversion.
2.4. String hashing and using a hash as a key
In the above examples keys were represented by one data type — strings. However, there might be different situations. For example, the first three digits of a phone number indicate a phone provider. In this case particularly these three digits represent a key. On the other side, each string can be represented as a unique number each digit of which means a sequence number of a letter in the alphabet. Thus, we can convert the string to unique number and use this number as an integer key to its associated value.
This method is good but not multiple-purpose enough. If we use a string containing hundreds of symbols as a key, the number will be incredibly large. It will be impossible to capture it into a simple variable of any type. Hash functions will help us to solve this problem. Hash function is a particular algorithm which accepts any data types (for example, a string) and returns some unique number characterizing this string.
Even if one symbol of entry data is changed, the number will be absolutely different. Numbers returned by this function have a fixed range. For example, the Adler32() hash function accepts parameter in the form of an arbitrary string, and returns a number in the range from 0 to 2 raised to the power of 32. This function is pretty simple, but it suits our tasks fine.
There is its source code in MQL5:
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
Let's see what numbers it returns depending on a transferred string.
For this purpose we will write a simple script which calls this function and transfers different strings:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
This script output revealed following:
2015.02.16 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Peace - 91685343
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world! - 487130206
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world - 413860925
As we can see, each string has a corresponding unique number. Turn attention to strings "Hello world" and "Hello world!" - they are almost identical. The only difference is an exclamation point at the end of the second string.
But numbers given by Adler32() were absolutely different in both cases.
Now we know how to convert the string type to the unsigned uint value, and we can store its integer hash instead of the string type key. If two strings will have one hash, it's most likely that it is the same string. Thus, a key to a value is not a string but an integer hash generated on the basis of this string.
2.5. Figuring an index by a key. List array
Now we know how to convert any basic type of MQL5 to the ulong unsigned type. Exactly this type will be an actual key to which our value will correspond. But it is not enough to have a unique key of the ulong type. Of course if we know a unique key of each object, we could invent some primitive storage method based on the switch-case operator or an array of an arbitrary length.
Such methods have been described in section 2.2 of the current chapter. But they are not flexible and efficient enough. As for switch-case, it does not seem possible to describe all variants of this operator.
As if there are dozens of thousands of objects, we will have to describe the switch operator, consisting of dozens of thousands of keys, at the stage of compilation, which is impossible. The second method is using an array where an element's key is also its index. It allows to resize the array in a dynamic manner adding necessary elements. Thereby we can constantly refer to it by its index which will be the element's key.
Let's make a draft of this solution:
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
But in real life this code rather poses problems, but does not solve them. Let us assume that a hash function will output a large hash. As in the given example the array index is equal to its hash, we have to resize the array which will make it huge. And it does not necessarily mean that we will succeed. Do you want to store one string in a container the size of which can reach several gigabytes?
The second problem is that in case of collisions the previous value will be replaced with a new one. After all, it is not improbable that the Adler32() function will return one hash key for two different strings. Do you want to lose a part of your data just because you want to refer to it rapidly using a key? The answer to these questions is obvious — no, you don't. In order to avoid such situations, we have to modify storage algorithm and develop a special-purpose hybrid container based on a list array.
A list array combines the best features of arrays and lists. These two classes are represented in the Standard Library. It bears reminding that arrays allow to refer to their undefined elements in a very rapid manner, but arrays themselves resize at a slow pace. But lists allow to add and remove new elements in less than no time, but access to each element of a list is a rather slow operation.
A list array can be represented as follows:

Fig. 5. Scheme of a list array
It is evident from the scheme that a list array is an array each element of which has a form of a list. Let's see what advantages it offers. First and foremost, we can rapidly refer to any list by its index. For another thing, if we store each data element in a list, we will be able to promptly add and remove elements from the list not resizing the array. The array index can be empty or equal to NULL. That means that elements corresponding to this index have not been added yet.
Combination of an array and a list offers one more uncommon opportunity. We can store two or more elements using one index. To understand its necessity, we can suppose that we need to store 10 numbers in an array with 3 elements. As we can see there are more numbers than elements in the array. We will solve this problem storing lists in an array. Let us assume that we will need one of three lists attached to one of three array indexes to store one or another number.
To determine the list index, we need to find out a remainder in division of our number by amount of elements in the array:
array index = number % elements in the array;
For example, the list index for number 2 will be as follows: 2%3 = 2. That means that index 2 will be stored in the list by index. Number 3 will be stored by index 3%3 = 0. Number 7 will be stored by index 7%3 = 1. After we determined the list index, we just need to add this number at the end of the list.
Similar actions are required to extract the number from the list. Let's assume that we want to extract number 7 from the container. For this purpose we need to find out in what container it is located: 7%3=1. After we have determined that number 7 can be located in the list by index 1, we will have to sort out the whole list and return this value if one of elements is equal to 7.
If we can store several elements using one index, we don't have to create huge arrays to store small amount of data. Let's assume that we need to store number 232,547,879 in an array consisting of 0-10 digits and having three elements. This number will have its list index equal to (232,547,879 % 3 = 2).
If we replace numbers with hash, we will be able to find an index of any element which has to be located in the dictionary. Because hash is a number. Moreover, owing to possibility to store several elements in one list, hash does not have to be unique. Elements with the same hash will be in one list. If we need to extract an element by its key, we will compare these elements and extract the one corresponding to the key.
This is possible as two elements with the same hash will have two unique keys. Uniqueness of keys can be controlled by the function which adds an element to the dictionary. It simply will not add a new element if its corresponding key is already in the dictionary. This is like a control over correspondence of a subscriber only to one phone number.
2.6. Array resize, minimizing list length
The smaller the list array and the more elements we add, the longer chains of lists will be formed by the algorithm. As has been said in the first chapter, access to an element of this chain is an inefficient operation. The shorter our list is, the more our container will look like an array which provides access to each element by an index. We need to aim at short lists and long arrays. A perfect array for ten elements is an array consisting of ten lists each of which will have one element.
The worst variant will be an array ten elements in length consisting of one list. As all elements are dynamically added to our container during the flow of the program, we cannot foresee how many elements will be added. That is why we need to think over dynamic resize of the array. And moreover, number of chains in lists should tend to one element. It is obvious that for this purpose the array size should be kept equal to the total number of elements. Permanent addition of elements requires permanent resize of the array.
The situation is also complicated by the fact that alongside with the array resize we will have to resize all lists, as the list index, the element might belong to, can be changed after resize. For example, if the array has three elements, number 5 will be stored in the second index (5%3 = 2). If there are six elements, number 5 will be stored in the fifth index (5%6=5). So, the dictionary resize is a slow operation. It should be performed as seldom as possible. On the other hand, if we do not perform it at all, chains will grow with each new element, and access to each element will be becoming less and less efficient.
We can create an algorithm which implements a reasonable compromise between amount of the array resizes and average length of the chain. It will be based on the fact that each next resize will increase the current size of the array twice. Thus if the dictionary initially has two elements, the first resize will increase its size by 4 (2^2), the second - by 8 (2^3), the third - by 16 (2^3). After the sixteenth resize there will be space for 65 536 chains (2^16). Each resize will be performed if amount of added elements coincides with recurrent power of two. Thus, total required actual main memory will not exceed memory required for storing all elements more than twice. On the other hand, the logarithmic law will help to avoid frequent resizes of the array.
Similarly, removing elements from the list we can reduce the array in size and by doing so save allocated main memory.
Chapter 3. Practical Development of an Associative Array
3.1. The template CDictionary class, the AddObject and the DeleteObjectByKey methods and the KeyValuePair container
Our associative array must be multi-purpose and allow to work with all types of keys. At the same time we will use objects based on standard CObject as values. Since we can locate any basic variables in classes, our dictionary will be a one-stop solution. Of course, we could create several classes of dictionaries. We could use a separate class type for each basic type.
For instance we could create following classes:
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...
But MQL5 has too many basic types. Furthermore, we would have to fix every code error many times, as all types have one core code. We will use templates to avoid duplication. We will have one class, but it will process several data types simultaneously. That is why main methods of classes will be template.
First of all, let's create our first template method — Add(). This method will be adding an element with an arbitrary key to our dictionary. The dictionary class will be named CDictionary. Alongside with the element, the dictionary will contain an array of pointers to CList lists. And we will store elements in these chains:
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
The AddObject() method works as follows. First it checks whether the dictionary has an element with a key which has to be added. The ContainsKey() method carries out this check. If the dictionary already has the key, a new element will not be added, as it will cause uncertainties given that two elements will correspond to one key.
Then the method learns about the size of the array where CList chains are stored. If the array size is equal to the number of elements, it is time to make a resize. This task is delegated to the Resize() method.
The next steps are simple. If according to the determined index the CList chain does not exist yet, this chain has to be created. The index is determined beforehand by the ContainsKey() method. It saves the determined index in the m_index variable. Then the method adds a new element at the end of the list. But before this the element is packed in a special container — KeyValuePair. It is based on standard CObject and expands the latter with additional pointers and data. Container class arrangement will be described a while later. Along with additional pointers, the container also stores an original key of the object and its hash.
The AddObject() method is a template method:
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
This record means that the key argument type is substitutional and its actual type is determined at compile time.
For example, the AddObject() method can be activated in its code as follows:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
Any of these activations will perfectly work due to templates.
There is also the DeleteObjectByKey() method which stays opposite to the AddObject() method. This method deletes an object from the dictionary by its key.
For example, you can delete an object with the key "Car" if it exists:
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
The code is much similar to the AddObject() method code, so we will not illustrate it here.
AddObject() and DeleteObjectByKey() methods do not work directly with objects. Instead of this they pack each object to the KeyValuePair container based on the standard CObject class. This container has additional pointers, which enable to relate elements, and also has an original key and a hash determined for the object. The container also tests the passed key for equality which allows to avoid collisions. We will discuss this in the next section dedicated to the ContainsKey() method.
Now we will illustrate content of this class:
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. Runtime type identification based on typename, hash sampling
Now when we know how to take undefined types in our methods, we will have to determine their hash. For all integer types a hash will be equal to the value of this type expanded to the ulong type.
To calculate the hash for double and float types, we need to use casting via structures, described in section "Conversion of base types into a unique key". A hash function should be used for strings. Anyway, every data type requires its own method of hash sampling. So all we need is to determine the transferred type and activate a method of hash sampling depending on this type. For this purpose we will need a special directive typename.
A method which determines the hash basing on the key is called GetHashByKey().
It includes:
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
Its logic is simple. Using the typename directive the method gets the string name of the transferred type. If the string is transferred as a key, typename will return the "string" value, in case of the int value it will return "int". The same will happen with any other type. Thus, all that we have to do is to compare the returned value with required string constants and activate corresponding handler if this value coincides with one of constants.
If the key is the string type, its hash is calculated by the Adler32() function. If the key is represented by real types, they are converted into the hash owing to structure conversion. All other types explicitly convert into the ulong type which will become the hash.
3.3. The ContainsKey() method. Reaction to hash collision
The main problem of any hashing function lies in collisions — situations when different keys give the same hash. In such case if hashes coincide, ambiguousness will arise (two objects will be similar in terms of the dictionary logic). To avoid such situation we need to check actual and requested key types and return a positive value only if actual keys coincide. That's how the ContainsKey() method works. It returns true if an object having the requested key exists, and otherwise it returns false.
Perhaps, this is the most useful and convenient method in the whole dictionary. It allows to know whether an object with a definite key exists:
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
For example, the above code checks availability of the CCar type object and adds CCar, if such object does not exist. This method also allows to check key uniqueness of each new object being added.
If the object key is already used, the AddObject() method simply will not add this new object to the dictionary.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
This is such a universal method that it is abundantly used both by users and other class methods.
Its content:
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
First the method finds a hash using GetHashByKey(). Than basing on the hash it gets an index of the CList chain, where an object with the given hash may be located. If there is not such chain, the object with such key does not exist either. In this case it will early terminate its operation and return false (object with such key does not exist). If the chain exists, it is started to be enumerated.
Each element of this chain is represented by the KeyValuePair type object, which is offered to compare an actual transferred key with a key stored by an element. If keys are the same, the method returns true (object having such key exists). The code, which tests keys for equality, is given in the listing of the KeyValuePair class.
3.4. Dynamic allocation and deallocation of memory
The Resize() method is responsible for dynamic allocation and deallocation of memory in our associative array. This method is activated every time when number of elements is equal to the m_array size. It is also activated when elements are deleted from the list. This method overrides storage indexes for all elements, so it works exceptionally slow.
To avoid frequent activation of the Resize() method, volume of allocated memory is increased twice each time comparing to its previous volume. In other words, if we want our dictionary to store 65,536 elements, the Resize() method will be activated 16 times (2^16). After twenty activations the dictionary could contain over one million elements (1,048,576). The FindNextLevel() method is responsible for exponential growth of required elements.
Here is the source code of the Resize() method:
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
This method works both to the higher and to the lower sides. When there are less elements than an actual array can contain, an element reduction code is initiated. And conversely when the current array is not enough, the array is resized for more elements. This code requires a lot of computing resources.
The whole array has to be resized, but all its elements should be previously removed to a temporary copy of the array. Then you need to determine new indexes for all elements and only after this you can locate these elements at their new spots.
3.5. Finishing strokes: searching objects and a handy indexer
Thus, our CDictionary class already has the main methods for working with it. We can use the ContainsKey() method if we want to know if an object with a certain key exists. We can add an object to the dictionary using the AddObject() method. We can also delete an object from the dictionary using the DeleteObjectByKey() method.
Now we need only to make a convenient enumeration of all objects in the container. As we already know, all elements are stored there in a particular order according to their keys. But it would be convenient to enumerate all elements in the same order in which we added them to the associative array. For this purpose the KeyValuePair container has two additional pointers to previous and next added elements of the KeyValuePair type. We can perform a sequential enumeration owing to these pointers.
For instance, if we added elements to our associative array as follows:
CNumber --> CShip --> CWeather --> CHuman --> CExpert --> CCar
enumeration of these elements will also be sequential, as it will be performed using references to KeyValuePair, as shown in Fig. 6:

Fig. 6. Scheme of sequential array enumeration
Five methods are used to performs such enumeration.
Here are their contents and brief description:
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
Due to these simple iterators we can perform a sequential enumeration of added elements:
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
This code will output string values of objects in the same order in which they have been added to the dictionary:
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
Change two strings of the code in the OnStart() function to output all elements backwards:
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
Accordingly, outputted values are inverted:
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
Chapter 4. Test and Evaluation of Performance
4.1. Writing tests and evaluating performance
Performance evaluation is a core ingredient of designing a class, especially if we are talking about a class for data storage. After all, the most diverse programs can take advantage of this class. These programs' algorithms may be critical to speed and require high performance. That is why it is so important to know how to evaluate performance and search weaknesses of such algorithms.
For a start, we will write a simple test which measures a speed of adding and extracting elements from the dictionary. This test will look like a script.
Its source code is attached below:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
This code sequentially adds elements to the dictionary and then refers to them measuring their speed. After this each element is deleted using the DeleteObjectByKey() method. The GetTickCount() system function measures the speed.
Using this script, we made a diagram depicting time dependencies of these three main methods:
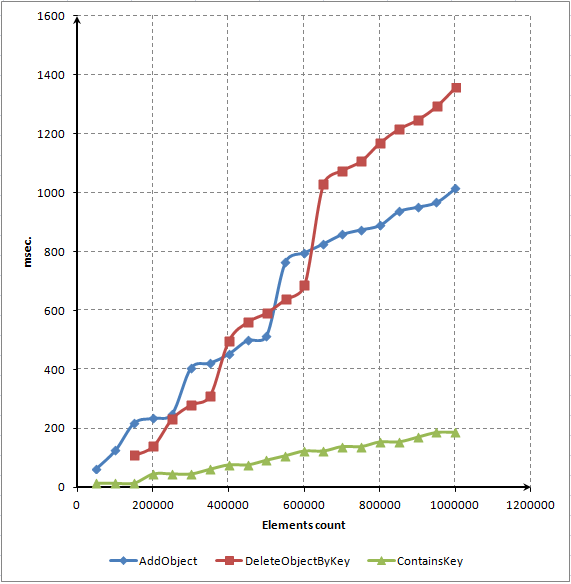
Fig. 7. Dot diagram of dependency between number of elements and methods' operate time in millisecond
As you can see, most of the time is spent on locating and deleting elements from the dictionary. Nevertheless, we expected that elements would be deleted much faster. We will try to improve performance of the method using a code profiler. This procedure will be described in the next section.
Turn attention to the diagram of the ContainsKey() method. It's linear. That means that access to a random element requires approximately one amount of time regardless of a number of these elements in the array. This is a must-have feature of a real associative array.
To illustrate this feature we will show a diagram of dependency between the average access time to one element and a number of elements in the array:
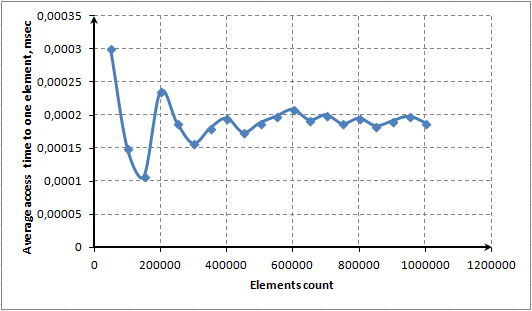
Fig. 8. Average access time to one element using the ContainsKey() method
4.2. Code profiling. Speed towards automatic memory management
Code profiling is a special technique which measures time expenditures of all functions. Just launch any MQL5 program by clicking ![]() in MetaEditor.
in MetaEditor.
We will do the same and send our script for profiling. After a while our script is performed and we get a time profile of all methods performed during operation of the script. The screenshot below shows that most of the time was spent for performing three methods: AddObject() (40% of time), GetObjectByKey() (7% of time) and DeleteObjectByKey() (53% of time):
 function")
Fig. 9. Code profiling in the OnStart() function
And over 60% of DeleteObjectByKey() call was spent for calling the Compress() method.
But this method is almost empty, the main time is spent for calling the Resize() method.
It includes:
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
The problem is clear. When we delete all elements, the Resize() method is occasionally launched. This method reduce the array size dynamically releasing storage.
Disable this method if you want to delete elements faster. For example, you can introduce the special AutoFreeMemory() method, setting the compression flag, to the class. It will be set by default, and in such case the compression will be performed automatically. But if we need additional speed, we will perform compression manually at a well-chosen moment. For this purpose we will make the Compress() method public.
If compression is disabled, elements are deleted three times faster:
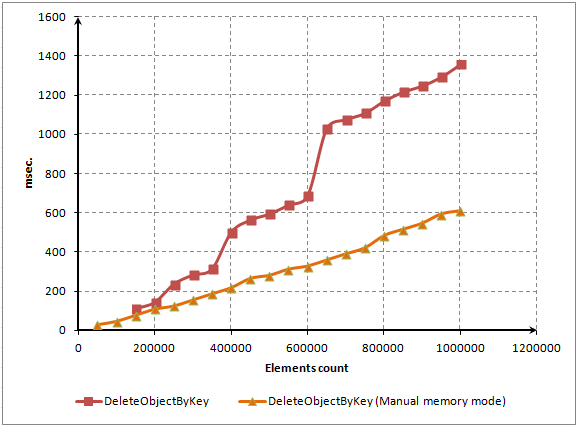
Fig. 10. Element deletion time with human monitoring the occupied storage (comparison)
The Resize() method is called not only for data compression but also when there are too many elements and we require a bigger array. In this case we cannot avoid calling the Resize() method. It must be called in order not to create long and slow CList chains in the future. But we can specify the required volume of our dictionary in advance.
For example, a number of added elements is often known beforehand. Knowing the number of elements, the dictionary will preliminarily create an array of the required size, so extra resizes during filling the array will not be required.
For this purpose we will add one more constructor which will accept required elements:
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
The private Init() method performs the main operation:
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
Our improvements are done. Now it is about time to evaluate performance of the AddObject() method with the initially specified array size. For this purpose we will change two first strings of the OnStart() function of our script:
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
In this case END is represented by a large number equal to 1,000,000 elements.
These innovations significantly sped up the AddObject() method performance:

Fig. 11. Time of adding elements with the preset array size
Solving real programming problems, we always have to choose between memory footprint and performance speed. It takes significant amount of time to free the memory. But in this case we will have more available memory. If we keep everything the way it is, the CPU time will not be spent for additional complicated computational problems, but at the sane time we will have less available memory. Using containers, object-oriented programming enables to allocate resources between the CPU memory and the CPU time in a flexible manner selecting a certain execution policy for each particular problem.
All in all, CPU performance is scaled much worse than the memory capacity. That is why in most instances we give preference to the execution speed rather than the memory footprint. Besides, memory control on a user level is more efficient than an automated control, as we usually do not know the finite state of the task.
For example, in case of our script we foreknow that at the end on enumeration the total number of elements will be null, as the DeleteObjectByKey() method will delete them all by the time of the end of the task. That is why we do not need to compress the array automatically. It will be enough to clear it at the very end by calling the Compress() method.
Now, when we have good linear metrics of adding and deleting elements from the array, we will analyze an average time of adding and deleting an element depending on the total number of elements:
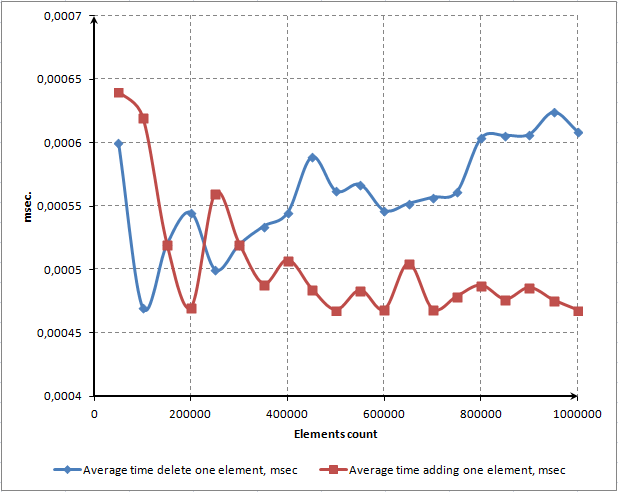
Fig. 12. Average time of adding and deleting one element
We can see that average time of adding one element is pretty stationary and does not depend on the total number of elements in the array. Average time of deleting one element moves slightly upwards which is undesirable. But we can not precisely say whether we deal with results within the error rate or this is a regular tendency.
4.3. Performance of CDictionary comparing to standard CArrayObj
It is about time for the most interesting test: we will compare our CDictionary with the standard CArrayObj class. The CArrayObj does not have mechanisms for manual memory allocation like indication of an assumptive size in the construction phase, that is why we will disable manual memory control in CDictionary and the AutoFreeMemory() mechanism will be enabled.
Strengths and weaknesses of each class have been described in the first chapter. CDictionary allows to add an element in an undefined spot as well as to extract it from the dictionary in a very rapid manner. But CArrayObj allows to make very fast enumeration of all elements. Enumeration in CDictionary will be slower, as it will be performed by means of moving by a pointer, and this operation is slower than direct indexing.
So here we go. For a start, let us create a new version of our test:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
It uses the TEST_ARRAY macros. If it is identified, the test performs operations on CArrayObj, otherwise operations are performed on CDictionary. The first test for adding new elements is won by CDictionary.
Its way of memory reallocation has appeared to be better in this particular case:
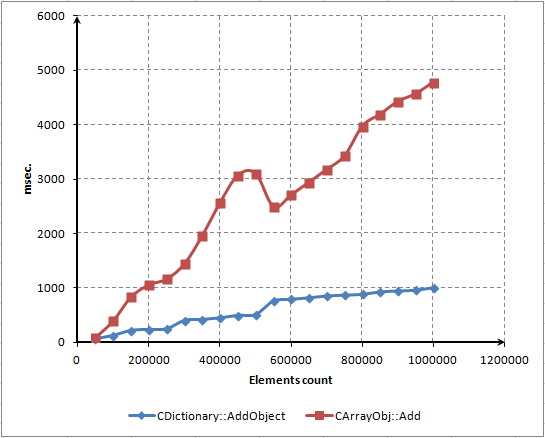
Fig. 13. Time spent for adding new elements to CArrayObj and CDictionary (comparison)
It is critical to underscore that slower operation was caused by a particular way of memory reallocation in CArrayObj.
It is described by only one string of the source code:
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize);
This is a linear algorithm of memory allocation. It is called by default after filling every 16 elements. CDictionary uses an exponential algorithm: every next memory reallocation allocates twice as much memory as the previous call. This diagram perfectly illustrates the dilemma between performance and used memory. The Reserve() method of the CArrayObj class is more economical and requires less memory but works slower. The Resize() method of the CDictionary class works faster but requires more memory, and half of this memory may stay unused at all.
Let us perform the last test. We will calculate time for full enumeration of CArrayObj and CDictionary containers. CArrayObj uses direct indexing, and CDictionary uses referencing. CArrayObj allows to refer to any element by its index, but in CDictionary reference to any element by its index is hampered. Sequential enumeration is highly competitive with direct indexing:
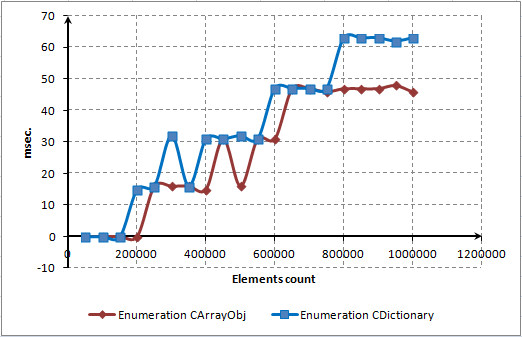
Fig. 14. Time for complete enumeration of CArrayObj and CDictionary
The MQL5 language developers did a great job and optimized references. They are highly competitive in speed with direct indexing which is illustrated in the diagram.
It is important to realize that element enumeration takes such short time, that it is almost on the verge of resolution of the GetTickCount() function. It is difficult to use it for measuring time intervals which are less than 15 milliseconds.
4.4. General recommendations when using CArrayObj, CList and CDictionary
We will make a table where we will describe main tasks which may occur in programming and features of containers which must be known to solve these tasks.
Features with good task performance are written in green, features, which do not allow to complete tasks efficiently, are written in red.
| Purpose | CArrayObj | CList | CDictionary |
|---|---|---|---|
| Sequential adding new elements at the end of the container. | The container has to allot new memory for a new element. Transfer of existing elements to new indexes is not required. CArrayObj will perform this operation very quickly. | The container remembers the first, the current and the last elements. Due to this fact a new element will be attached to the end of the list (the last remembered element) very quickly. | The dictionary does not have such concepts as "end" or "beginning". A new element is attached very quickly and does not depend on a number of elements. |
| Access to an arbitrary element by its index. | Due to direct indexing, the access is gained very quickly, it takes O(1) of time. | The access to each element is gained via enumeration of all previous elements. This operation takes O(n) of time. | The access to each element is gained via enumeration of all previous elements. This operation takes O(n) of time. |
| Access to an arbitrary element by its key. | Not available | Not available | Figuring a hash and an index by a key is an efficient and fast operation. Hashing function efficiency is very important for string keys. This operation takes O(1) of time. |
| New elements are added/deleted by an undefined index. | CArrayObj has not only to allot memory for a new element but also to remove all elements indexes of which are higher than an index of the inserted element. That is why CArrayObj is a slow operation. | The element is added or deleted from CList very quickly, but necessary index can be accessed for O(n). This is a slow operation. |
In CDictionary, the access to the element by its index is performed basing on the CList list and takes a lot of time. But adding and deleting are performed very fast. |
| New elements are added/deleted by an undefined key. | Not available | Not available | As every new element is inserted in CList, new elements are added and deleted very fast since the array does not have to be resized after each addition/deletion. |
| Usage and memory management. | Dynamic array resize is required. This is a resource-intensive operation, it requires either a lot of time or a lot of memory. | Memory management is not used. Each element takes the right amount of memory. | Dynamic array resize is required. This is a resource-intensive operation, it requires either a lot of time or a lot of memory. |
| Enumeration of elements. Operations which must be performed for each element of the vector. | Performed very fast due to direct element indexing. But in some cases enumeration must be performed in reverse order (for example, when sequentially deleting the last element). | As we need to enumerate all elements only once, direct referencing is a fast operation. | As we need to enumerate all elements only once, direct referencing is a fast operation. |
Chapter 5. CDictionary Class Documentation
5.1. Key methods to add, delete and access to elements
5.1.1. The AddObject() method
Adds new element of the CObject type with T Key. Any base type can be used as a key.
template<typename T> bool AddObject(T key,CObject *value);
Parameters
- [in] key – unique key represented by one of base types (string, ulong, char, enum etc.).
- [in] value - object with CObject as a base type.
Returned value
Returns true, if the object has been added to the container, otherwise returns false. If the key of the added object already exists in the container, the method will return a negative value and the object will not be added.
5.1.2. The ContainsKey() method
Checks whether there is an object with a key equal to T Key in the container. Any base type can be used as a key.
template<typename T> bool ContainsKey(T key);
Parameters
- [in] key – unique key represented by one of base types (string, ulong, char, enum etc.).
Returns true, if the object having the checked key exists in the container. Otherwise returns false.
5.1.3. The DeleteObjectByKey() method
Deletes an object by preset T Key. Any base type can be used as a key.
template<typename T> bool DeleteObjectByKey(T key);
Parameters
- [in] key – unique key represented by one of base types (string, ulong, char, enum etc.).
Returned value
Returns true, if the object having the preset key has been deleted. Returns false, if the object having the preset key does not exist or its deletion has failed.
5.1.4. The GetObjectByKey() method
Returns an object by preset T Key. Any base type can be used as a key.
template<typename T> CObject* GetObjectByKey(T key);
Parameters
- [in] key – unique key represented by one of base types (string, ulong, char, enum etc.).
Returned value
Returns an object corresponding to the preset key. Returns NULL, if the object with the preset key does not exist.
5.2. Memory management methods
5.2.1. CDictionary() constructor
The base constructor creates the CDictionary object with initial size of the base array equal to 3 elements.
The array is increased or compressed automatically with filling the dictionary or deleting elements from it.
CDictionary();
5.2.2. CDictionary(int capacity) constructor
The constructor creates the CDictionary object with initial size of the base array equal to 'capacity'.
The array is increased or compressed automatically with filling the dictionary or deleting elements from it.
CDictionary(int capacity);
Parameters
- [in] capacity – number of initial elements.
Note
Setting array size limit immediately after its initialization will help you to avoid calls of the Resize() method and thus increase efficiency when inserting new elements.
However, it must be noted that if you delete elements with enabled (AutoMemoryFree(true)), the container will be automatically compressed despite of capacity setting. To avoid early compression, perform the first operation of object deletion after containers are fully filled, or if that cannot be done, disable (AutoMemoryFree(false)).
5.2.3. The FreeMode(bool mode) method
Sets the mode of deleting objects existing in the container.
If the deletion mode is enabled, the container is also subject to the 'delete' procedure after the object has been deleted. Its destructor is activated and it becomes unavailable. If the deletion mode is disabled, the object's destructor is not activated and it keeps being available from other points of the program.
void FreeMode(bool free_mode);
Parameters
- [in] free_mode – object deletion mode indicator.
5.2.4. The FreeMode() method
Returns the indicator of deleting objects located in the container (see FreeMode(bool mode)).
bool FreeMode(void);
Returned value
Returns true, if the object is deleted by the delete operator after it has been deleted from the container. Otherwise returns false.
5.2.5. The AutoFreeMemory(bool autoFree) method
Sets the automatic memory management indicator. Automatic memory management is enabled by default. In such case the array is compressed automatically (resized from larger to smaller size). If disabled, the array is not compressed. It significantly increases the speed of the program execution, as the resource-intensive Resize() method does not have to be called. But in this case you have to have an eye on the array size and compress it manually by means of the Compress() method.
void AutoFreeMemory(bool auto_free);
Parameters
- [in] auto_free – memory management mode indicator.
Returned value
Returns true, if you need to enable memory management and call the Compress() method automatically. Otherwise returns false.
5.2.6. The AutoFreeMemory() method
Returns the indicator which specifies whether the automated memory management mode is used (see the FreeMode(bool free_mode) method).
bool AutoFreeMemory(void);
Returned value
Returns true, if the memory management mode is used. Otherwise returns false.
5.2.7. The Compress() method
Compresses the dictionary and resizes elements. The array is compressed only if it is possible.
This method should be called only if the automated memory management mode is disabled.
void Compress(void);
5.2.8. The Clear() method
Deletes all elements in the dictionary. If the memory management indicator is enabled, the destructor is called for each element being deleted.
void Clear(void);
5.3. Methods of searching over the dictionary
All dictionary's elements are interconnected. Each new element is connects with the previous one. Thus sequential search of all elements of the dictionary becomes possible. In such case reference is performed by a linked list. Methods in this section facilitate search and make the dictionary iteration more convenient.
You can use the following construction while searching over the dictionary:
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }
5.3.1. The GetFirstNode() method
Returns the very first element added to the dictionary.
CObject* GetFirstNode(void);
Returned value
Returns the pointer to the CObject type object, which has been primarily added to the dictionary.
5.3.2. The GetLastNode() method
Returns the last element of the dictionary.
CObject* GetLastNode(void);
Returned value
Returns the pointer to the CObject type object, which has been added to the dictionary at the very end.
5.3.3. GetCurrentNode() method
Returns the current selected element. The element should be preliminary selected by one of methods of searching elements over the dictionary or by the method of access to the dictionary's element (ContainsKey(), GetObjectByKey()).
CObject* GetLastNode(void);
Returned value
Returns the pointer to the CObject type object, which has been added to the dictionary at the very end.
5.3.4. The GetNextNode() method
Returns the element which follows the current one. Returns NULL if the current element is the last one or is not selected.
CObject* GetLastNode(void);
Returned value
Returns the pointer to the CObject type object, which follows the current one. Returns NULL if the current element is the last one or is not selected.
5.3.5. The GetPrevNode() method
Returns the element which is previous to the current one. Returns NULL if the current element is the first one or is not selected.
CObject* GetPrevNode(void);
Returned value
Returns the pointer to the CObject type object, which is previous to the current one. Returns NULL if the current element is the first one or is not selected.
Conclusion
We have considered the main features of widespread data containers. Each data container should be used where its features allow to solve the problem in the most efficient way.
Regular arrays should be used where sequential access to an element is enough for solving the problem. Dictionaries and associated arrays are better to use where the access to an element by its unique key is required. Lists are better to use in case of frequent element replacement: deletion, insertion, adding new elements.
The dictionary allows to solve challenging algorithmic problems in a nice and simple manner. Where other data containers require additional processing features, the dictionary allows to arrange access to existing elements in the most effective way. For example, basing on the dictionary, you can make an event model where each event of the OnChartEvent() type is delivered to the class which manages one or another graphical element. For this purpose, just associate every class instance with the name of the object managed by this class.
As the dictionary is a universal algorithm, it can be applied in the most various fields. This article clarifies that its operation is based on pretty simple yet robust algorithms which make its application convenient and effective.