文章 "神经网络变得轻松(第十一部分):自 GPT 获取"
非常感谢你的文章。他的算法非常好,对我来说,它们是 mql5 神经网络中最好的算法,因为它们允许在市场期间逐行实时更新网络。我正在巴西期货市场上测试他的算法,结果令人鼓舞,在过去的 100 个条形图中,预测效率超过了 80%,从而带来了积极的交易。我期待着下一篇文章。 
有趣的资料,但代码都在一个巨大的意大利面碗里,很难掌握。每个文件一个类会更容易。
如果能提供一个图表,说明所有类是如何组合在一起的,那就更好了。
现在我使用的 NeuronBase 从 Object 派生,但又使用了 NeuronProof,而 NeuronProof 又是从 NeuronBase 派生的,还有 Layer,它几乎使用了定义的所有类型的 Neuron 类。
为了将所有内容放入不同的文件中并熟练掌握,需要进行大量的前向声明。
也许从头开始,使用你在各章中解释的概念会更容易些。
我试着运行意大利面碗,它让我的 GPU 冒烟,遗憾的是没有产生任何有用的东西。
不管怎样,还是要感谢您提供的这些好材料。
:-)
有趣的资料,但代码都是一个大面条碗,很难掌握。每个文件一个类会更容易些。
如果能提供一个图表,说明所有类是如何组合在一起的,那就更好了。
现在我使用的 NeuronBase 源自 Object,但使用了 NeuronProof,而 NeuronProof 源自 NeuronBase 和 Layer,后者几乎使用了定义的所有类型的 Neuron 类。
为了把所有东西都放在不同的文件中并掌握它,需要大量的前向声明。
也许从头开始并使用您在各章节中解释的概念会更容易一些。
我试着运行了意大利面碗,它让我的 GPU 冒烟,遗憾的是没有产生任何有用的东西。
不管怎样,还是要感谢您提供了这么好的资料。
:-)
你好,
查看 NN.chm。也许会对您有所帮助。
您好、
是的,谢谢你。
现在代码不那么糟糕了,而且我可以清楚地看到如何在必要时改变网络结构。
我把所有东西都放在单独的类文件中,再加上一个小得多的意大利面碗,这仍然是必要的,因为 mt5 把定义和实现都放在同一个文件中。
我试着用原代码对英镑兑美元进行了一些训练,但结果似乎并不理想,误差从自然的 50%上升到了 70%,而且在随后的历时中没有任何改善。
有什么建议可以从哪里开始调整?
顺便提一下这一行:
#define FileName Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_"+IntegerToString(HistoryBars,3)+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
需要更正为
#define FileName Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_"+IntegerToString(HistoryBars)+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))

起初,我并没有真正理解这篇文章,因为我并没有真正领会文章的主旨。
当我向 ChatGPT 本人询问 这篇文章时,他澄清了很多事情,我才理解了我读到的大部分内容:
"Transformer 算法是一种用于处理自然语言(即文本)的模型。该模型将文本分解为一系列单词(或 "标记"),然后对每个单词执行一系列操作,以更好地理解其含义。
该模型执行的操作之一是自我关注,包括计算每个词相对于序列中其他词的重要性。为此,该模型使用三个向量:查询向量、关键向量和价值向量,这三个向量是为每个单词计算的。
然后,模型会计算关注度,即每个词相对于序列中其他词的重要性。它使用一种名为 softmax 的数学函数对注意力系数进行归一化处理。
最后,该模型将所有自我注意力操作结合起来,得出最终结果,用于预测文本的含义。
简而言之,Transformer 算法使用复杂的数学运算来理解文本的含义"。
新文章 神经网络变得轻松(第十一部分):自 GPT 获取已发布:
也许,GPT-3 是目前已有语言类神经网络中最先进的模型之一,它的最大变体可包含 1750 亿个参数。 当然,我们不打算在家用 PC 上创建如此庞然之物。 然而,我们可以看看在我们的操作中能够采用哪种体系解决方案,以及如何从中受益。
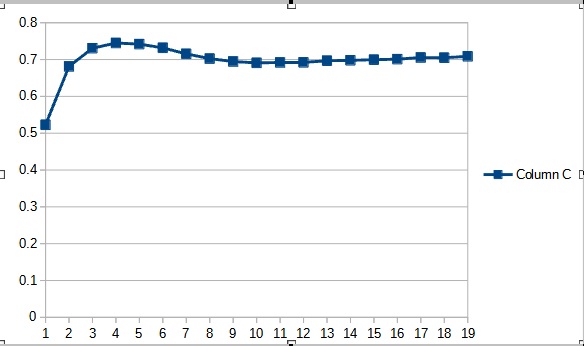
在同一数据集上测试了新的神经网络类,该数据集在之前的测试中曾经用过:神经网络馈入 EURUSD,时间帧为 H1,最后 20 根烛条的历史数据。
测试结果证实了这个假设,即更多的参数需要更长的训练时间。 在第一个训练迭代,参数较少的智能交易系统展现出的结果更稳定。 然而,随着训练时间的延申,带有大量参数的智能交易系统会展现出更佳的数值。 通常,在 33 个迭代之后,Fractal_OCL_AttentionMLMH_v2 的误差降低到 Fractal_OCL_AttentionMLMH EA 的误差水平以下,且它会进一步保持低水平。
作者:Dmitriy Gizlyk