文章 "基于暴力算法的 CatBoost 模型高级重采样与选择" - 页 12 1...56789101112131415 新评论 [删除] 2020.12.01 17:56 #111 Evgeni Gavrilovi:添加文件路径 - traing prnew.csv 和 test prnews.csv但接收到的 R2 几乎总是高于 0.9,可能是 look_back 设置不正确,所以接收到的 mqh 文件是错误的,因此终端中的测试不起作用。https:// colab.research.google.com/drive/1eeyRA5bGaFMfX1THnMsL5hwKmxBkqvqPhttps://drive.google.com/file/d/1LIRhpk5iU_dYQbefZ-FFQM6XMV_cOh26/view?usp=sharing 测试数据https://drive.google.com/file/d/18RpJec9EGSCSknwaHsevgHcZuCeoOvP5/view?usp=sharing 训练数据 我一会儿再看,我工作很忙。 Evgeni Gavrilovi 2020.12.01 18:23 #112 Maxim Dmitrievsky:等我忙完工作再看。 好的。 这是 mqh 文件:https://drive.google.com/file/d/1UquXcaRJjIR2lxE81P8Pm2BWFQ9uM0N1/view?usp=sharing 测试仪显示以下错误: 2020.12.01 21:19:23.252 2020.08.03 00:05:00 'cat_model.mqh' 中的数组超出范围 (288,51) Rasoul Mojtahedzadeh 2020.12.01 21:40 #113 Maxim Dmitrievsky : 你好,拉苏尔。试着减少训练集的大小。这取决于不同的设置,但关键诀窍在于,训练集越小,对新数据的泛化效果就越好。在下一篇文章中,我会尝试解释这种效果。 你好,马克西姆, ,我把训练集的周期改为如下、 1.训练集:从 2018.01.01 到 2019.01.01 这仅用于训练 GMM。 2.验证集:从 2019.01.01 到 2020.01.01 该集将用于蛮力算法,以找到最佳模型。 3.测试集:2020.01.01 至 2021.01.01 该集仅用于测试蛮力算法得到的最佳模型。 下面是运行脚本的典型结果、 我附上了代码,你可以看一看,找出可能的错误。 附加的文件: clustering_catboost_orig.py 12 kb [删除] 2020.12.01 23:13 #114 Rasoul Mojtahedzadeh:你好,马克西姆, ,我将各组的周期改为如下、1.训练集:从 2018.01.01 到 2019.01.01 这只能用于训练 GMM。 2.验证集:2019.01.01 至 2020.01.01 这组数据将用于蛮力算法,以找到最佳模型。 3.测试集:2020.01.01 至 2021.01.01 该测试集仅用于测试通过蛮力算法获得的最佳模型。 以下是运行脚本的典型结果, 。 我在此附上代码,以便您查看,找出可能存在的错误。 有时只需更改学习间隔和设置,模型就能捕捉到更好的依赖关系: LOOK_BACK = 1 MA_PERIODS = [15, 25, 55, 100, 150, 200, 250, 300] SYMBOL = 'EURUSD' MARKUP = 0.00010 TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2018, 9, 1) VSTART_DATE = datetime(2019, 3, 1) TSTART_DATE = datetime(2019, 7, 1) STOP_DATE = datetime(2021, 1, 1) [删除] 2020.12.01 23:20 #115 Evgeni Gavrilovi:好吧这是 mqh 文件:https://drive.google.com/file/d/1UquXcaRJjIR2lxE81P8Pm2BWFQ9uM0N1/view?usp=sharing测试器中列出了错误: 2020.12.01 21:19:23.252 2020.08.03 00:05:00 'cat_model.mqh' 中的数组超出范围 (288,51) 我怀疑你使用的是上一篇文章中的机器人版本。本文中的机器人是不同的。检查一下,应该不会出现这样的错误。 R^2 0.9 很好,我也经常出现这种情况 Rasoul Mojtahedzadeh 2020.12.01 23:21 #116 Maxim Dmitrievsky:例如,有时只需改变学习间隔和设置,模型就能捕捉到更好的依赖关系: 感谢您的快速回复! 您的设置看起来不错!:) 致以最诚挚的问候、 Rasoul [删除] 2020.12.01 23:23 #117 Rasoul Mojtahedzadeh:感谢您的快速回复!您的设置看起来不错!:)致以最崇高的敬意Rasoul 根据我的经验,look_back 只需设置 1...和更多不同的 MA。有时需要改变学习周期 有时需要将 GMM 中的簇数从 75 改为另一个...等等) 也许需要添加更好的特征,而不是 MA,但我不知道具体是哪些特征...需要实验 Evgeni Gavrilovi 2020.12.01 23:38 #118 Maxim Dmitrievsky:我怀疑您使用的是上一篇文章中的机器人版本。本文中的机器人是不同的。请检查一下,应该不会出现这样的错误。R^2 0.9 很好,我也经常用它 只有新版本才有 brute_force 功能,但重点不同 - 接收到的 mqh 文件会给出一个超出范围的 错误数组,无法测试高 R^2 的机器人。 [删除] 2020.12.01 23:40 #119 Evgeni Gavrilovi:只有在新版本中才有一个 brute_force 函数,但问题有所不同--接收到的 mqh 文件会给出一个超出范围的错误数组,无法测试具有高 R^2 的机器人。 我说的是您编译的 EA 文件。 Evgeni Gavrilovi 2020.12.01 23:45 #120 Maxim Dmitrievsky:我说的是你正在编译的 EA 文件。 是的,就是这个。 它说 #include <MT4Orders.mqh> (包含 <MT4Orders.mqh #包含 <Trade\AccountInfo.mqh> #include <cat_model.mqh> 最重要的是,当直接从 jupyter notebook 加载 mqh 时,一切正常,这让我很惊讶。 1...56789101112131415 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
添加文件路径 - traing prnew.csv 和 test prnews.csv
但接收到的 R2 几乎总是高于 0.9,可能是 look_back 设置不正确,所以接收到的 mqh 文件是错误的,因此终端中的测试不起作用。
https:// colab.research.google.com/drive/1eeyRA5bGaFMfX1THnMsL5hwKmxBkqvqP
https://drive.google.com/file/d/1LIRhpk5iU_dYQbefZ-FFQM6XMV_cOh26/view?usp=sharing 测试数据
https://drive.google.com/file/d/18RpJec9EGSCSknwaHsevgHcZuCeoOvP5/view?usp=sharing 训练数据
我一会儿再看,我工作很忙。
等我忙完工作再看。
好的。
这是 mqh 文件:https://drive.google.com/file/d/1UquXcaRJjIR2lxE81P8Pm2BWFQ9uM0N1/view?usp=sharing
测试仪显示以下错误: 2020.12.01 21:19:23.252 2020.08.03 00:05:00 'cat_model.mqh' 中的数组超出范围 (288,51)
你好,马克西姆,
,我把训练集的周期改为如下、
该集仅用于测试蛮力算法得到的最佳模型。
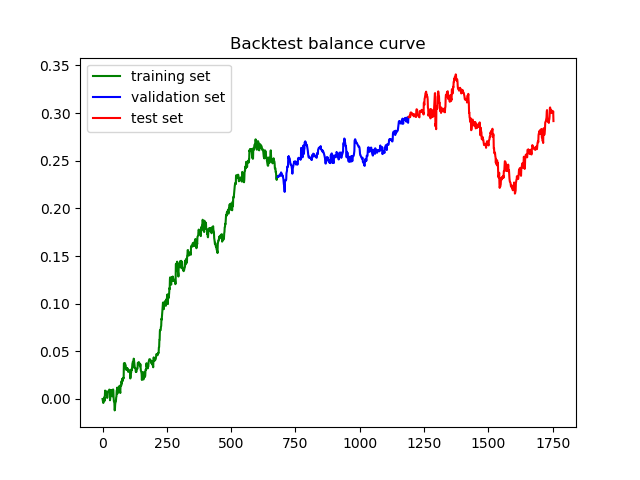
下面是运行脚本的典型结果、
我附上了代码,你可以看一看,找出可能的错误。
你好,马克西姆,
,我将各组的周期改为如下、
该测试集仅用于测试通过蛮力算法获得的最佳模型。
以下是运行脚本的典型结果,
。
我在此附上代码,以便您查看,找出可能存在的错误。
有时只需更改学习间隔和设置,模型就能捕捉到更好的依赖关系:
好吧
这是 mqh 文件:https://drive.google.com/file/d/1UquXcaRJjIR2lxE81P8Pm2BWFQ9uM0N1/view?usp=sharing
测试器中列出了错误: 2020.12.01 21:19:23.252 2020.08.03 00:05:00 'cat_model.mqh' 中的数组超出范围 (288,51)
我怀疑你使用的是上一篇文章中的机器人版本。本文中的机器人是不同的。检查一下,应该不会出现这样的错误。
R^2 0.9 很好,我也经常出现这种情况
例如,有时只需改变学习间隔和设置,模型就能捕捉到更好的依赖关系:
感谢您的快速回复!
您的设置看起来不错!:)
致以最诚挚的问候、
Rasoul
感谢您的快速回复!
您的设置看起来不错!:)
致以最崇高的敬意
Rasoul
根据我的经验,look_back 只需设置 1...和更多不同的 MA。有时需要改变学习周期
有时需要将 GMM 中的簇数从 75 改为另一个...等等)
也许需要添加更好的特征,而不是 MA,但我不知道具体是哪些特征...需要实验
我怀疑您使用的是上一篇文章中的机器人版本。本文中的机器人是不同的。请检查一下,应该不会出现这样的错误。
R^2 0.9 很好,我也经常用它
只有新版本才有 brute_force 功能,但重点不同 - 接收到的 mqh 文件会给出一个超出范围的 错误数组,无法测试高 R^2 的机器人。
只有在新版本中才有一个 brute_force 函数,但问题有所不同--接收到的 mqh 文件会给出一个超出范围的错误数组,无法测试具有高 R^2 的机器人。
我说的是您编译的 EA 文件。
我说的是你正在编译的 EA 文件。
是的,就是这个。
它说
#include <MT4Orders.mqh> (包含 <MT4Orders.mqh
#包含 <Trade\AccountInfo.mqh>
#include <cat_model.mqh>
最重要的是,当直接从 jupyter notebook 加载 mqh 时,一切正常,这让我很惊讶。