Применение OpenCL для тестирования свечных моделей
Serhii Shevchuk | 9 ноября, 2018
Введение
Когда человек начинает осваивать OpenCL, перед ним встаёт вопрос, куда его применить. Такие показательные примеры, как перемножение матриц или сортировка больших объемов данных, на практике не находят массового внедрения в построении индикаторов или автоматических торговых систем. Ещё один распространённый способ применения — работа с нейросетями — требует определённых познаний в этой области, и знакомство с ними для непосвящённого программиста может стоить уймы времени, без гарантии каких-либо результатов в трейдинге. Всё это служит отталкивающим фактором для тех, что хотел бы ощутить всю мощь OpenCL на примерах решения элементарных задач.
В данной статье мы рассмотрим применение OpenCL для решения простейшей задачи алготрейдинга — поиска свечных моделей и тестирования их на истории. Разработаем алгоритм тестирования одиночного прохода и оптимизации двух параметров в режиме торговли "OHLC на M1". А затем сравним производительность встроенного тестера стратегий с тестером, написанным на OpenCL, и выясним, кто из них быстрее, и во сколько раз.
Предполагается, что читатель уже знаком с основами OpenCL. Если нет, рекомендуется прочесть статьи "OpenCL: Мост в параллельные миры" и "OpenCL: от наивного кодирования - к более осмысленному". Также, не помешает иметь под рукой спецификацию "The OpenCL Specification Version 1.2". В статье основное внимание будет уделяться алгоритму построения тестера, не фокусируясь на основах программирования на OpenCL.
- Введение
- 1. Реализация на MQL5
- 2. Реализация на OpenCL
- 2.1 Загрузка ценовых данных
- 2.2 Одиночное тестирование
- 2.2.1. Поиск паттернов на OpenCL
- 2.2.2. Перенос ордеров на таймфрейм M1
- 2.2.3. Получение результатов сделок
- 2.3. Запуск тестирования
- 2.4. Оптимизация
- 2.4.1. Подготовка ордеров
- 2.4.2. Получение результатов сделок
- 2.4.3. Поиск паттернов и формирование результатов тестирования
- 2.5. Запуск оптимизации
- 3. Сравнение производительности
- 3.1. Оптимизация на паре EURUSD
- 3.2. Оптимизация на паре GBPUSD
- 3.3. Оптимизация на паре USDJPY
- 3.4. Сводная таблица соотношения производительности
- Заключение
1. Реализация на MQL5
Для того, чтобы убедиться, что реализация тестера на OpenCL работает правильно, нужно на что-то опираться. Поэтому, для начала мы напишем эксперт на MQL5, а затем будем сравнивать результаты его тестирования и оптимизации штатным тестером с соответствующими результатами тестера, реализованного на OpenCL.
- Медвежий пин бар
- Бычий пин бар
- Медвежье поглощение
- Бычье поглощение
Стратегия будет простая:
- Медвежий пин бар или медвежье поглощение — продажа
- Бычий пин бар или бычье поглощение — покупка
- Количество одновременно открытых позиций — не ограничено
- Максимальное время удержания открытой позиции — ограничено, задаётся пользователем
- Уровни Take Profit и Stop Loss фиксированные, задаются пользователем
Наличие паттерна будем проверять на полностью закрытых барах. Иными словами, в момент появления нового бара мы будем искать паттерн на трёх предыдущих.
Условия обнаружения паттернов будут следующие:

Рис.1. Паттерны "Медвежий пин бар" (a) и "Бычий пин бар" (b)
Для медвежьего пин бара (Рис. 1, a):
- Верхняя тень ("хвост") первого бара больше заданной опорной величины: tail>=Reference
- Нулевой бар - бычий: Close[0]>Open[0]
- Второй бар - медвежий: Open[2]>Close[2]
- Цена High первого бара является локальным максимумом: High[1]>MathMax(High[0],High[2])
- Тело первого бара меньше его верхней тени: MathAbs(Open[1]-Close[1])<tail
- "Хвост" tail = High[1]-max(Open[1],Close[1])
Для бычьего пин бара (Рис. 1, b):
- Нижняя тень ("хвост") первого бара больше заданной опорной величины: tail>=Reference
- Нулевой бар - медвежий: Open[0]>Close[0]
- Второй бар - бычий: Close[2]>Open[2]
- Цена Low первого бара является локальным минимумом: Low[1]<MathMin(Low[0],Low[2])
- Тело первого бара меньше его нижней тени: MathAbs(Open[1]-Close[1])<tail
"Хвост" tail = min(Open[1],Close[1])-Low[1]

Рис. 2. Паттерны "Медвежье поглощение" (a) и "Бычье поглощение" (b)
Для медвежьего поглощения (Рис. 2, a):
- Первый бар бычий, его тело больше заданной опорной величины: (Close[1]-Open[1])>=Reference
- Цена High нулевого бара ниже цены закрытия первого бара: High[0]<Close[1]
- Цена открытия второго бара больше цены закрытия первого бара: Open[2]>CLose[1]
- Цена закрытия второго бара меньше цены открытия первого бара: Close[2]<Open[1]
Для бычьего поглощения (Рис. 2, b):
- Первый бар медвежий, его тело больше заданной опорной величины: (Open[1]-Close[1])>=Reference
- Цена Low нулевого бара выше цены закрытия первого бара: Low[0]>Close[1]
- Цена открытия второго бара меньше цены закрытия первого бара: Open[2]<Close[1]
- Цена закрытия второго бара больше цены открытия первого бара: Close[2]>Open[1]
1.1 Поиск паттернов
ENUM_PATTERN Check(MqlRates &r[],uint flags,double ref) { //--- медвежий пин бар if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-MathMax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>MathMax(H(0),H(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- бычий пин бар if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=MathMin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<MathMin(L(0),L(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- медвежье поглощение if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- бычье поглощение if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- ничего не найдено return PAT_NONE; }
Здесь следует обратить внимание на энумератор ENUM_PATTERN, значения которого являются флагами, которые можно комбинировать и передавать в качестве одного аргумента, используя побитовое ИЛИ:
enum ENUM_PATTERN { PAT_NONE=0, PAT_PINBAR_BEARISH = (1<<0), PAT_PINBAR_BULLISH = (1<<1), PAT_ENGULFING_BEARISH = (1<<2), PAT_ENGULFING_BULLISH = (1<<3) };
Также, для более компактной записи условий введены макросы:
#define O(i) (r[i].open) #define H(i) (r[i].high) #define L(i) (r[i].low) #define C(i) (r[i].close)
Функция Check() будет вызвана из функции IsPattern(), которая предназначена для проверки наличия указанных паттернов на момент открытия нового бара:
ENUM_PATTERN IsPattern(uint flags,uint ref) { MqlRates r[]; if(CopyRates(_Symbol,_Period,1,PBARS,r)<PBARS) return 0; ArraySetAsSeries(r,false); return Check(r,flags,double(ref)*_Point); }
1.2 Сборка эксперта
Для начала определимся с входными параметрами. Во-первых, в условиях определения паттернов у нас фигурирует опорная величина. Это минимальная длина "хвоста" для пин-бара или области пересечения тел для поглощения. Будем задавать её в пунктах:
input int inp_ref=50;
Второе, это набор паттернов, с которыми работаем. Для удобства, во входных параметрах не будем использовать регистр флагов, а распишем его на четыре параметра типа bool:
input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true;
Которые соберём в беззнаковую переменную в функции инициализации:
p_flags = 0; if(inp_bullish_pin_bar==true) p_flags|=PAT_PINBAR_BULLISH; if(inp_bearish_pin_bar==true) p_flags|=PAT_PINBAR_BEARISH; if(inp_bullish_engulfing==true) p_flags|=PAT_ENGULFING_BULLISH; if(inp_bearish_engulfing==true) p_flags|=PAT_ENGULFING_BEARISH;
Далее задаётся допустимое время удержания позиции, выраженное в часах, уровни Take Profit, Stop Loss, и объём лота:
input int inp_timeout=5; input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true; input double inp_lot_size=1;Для торговли будем использовать класс CTrade из стандартной библиотеки. Для измерения скорости тестера будем использовать класс CDuration, который позволяет измерять промежутки времени между контрольными точками выполнения программы в микросекундах и выводить в удобном виде. В данном случае мы будем измерять время между функциями OnInit() и OnDeinit(). Полный код класса содержится в файле Duration.mqh во вложении.
CDuration time; int OnInit() { time.Start(); // ... return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { time.Stop(); Print("Тестирование длилось "+time.ToStr()); }
Работа эксперта предельно простая и заключается в следующем.
В функции OnTick() на первом месте находится обработка открытых позиций. Она состоит в том, чтобы принудительно закрыть позицию, если время её удержания превысило значение, заданное во входных параметрах. Далее следует проверка открытия нового бара. Если проверка прошла, то проверяем наличие паттерна при помощи функции IsPattern(). При нахождении какого-либо паттерна открываем позицию на покупку или продажу согласно стратегии. Полный код функции OnTick() приведён ниже:
void OnTick() { //--- обработка открытых позиций int total= PositionsTotal(); for(int i=0;i<total;i++) { PositionSelect(_Symbol); datetime t0=datetime(PositionGetInteger(POSITION_TIME)); if(TimeCurrent()>=(t0+(inp_timeout*3600))) { trade.PositionClose(PositionGetInteger(POSITION_TICKET)); } else break; } if(IsNewBar()==false) return; //--- проверка на наличие паттерна ENUM_PATTERN pat=IsPattern(p_flags,inp_ref); if(pat==PAT_NONE) return; //--- открытие позиций double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); if((pat&(PAT_ENGULFING_BULLISH|PAT_PINBAR_BULLISH))!=0)//покупка trade.Buy(inp_lot_size,_Symbol,ask,NormalizeDouble(ask-inp_sl*_Point,_Digits),NormalizeDouble(ask+inp_tp*_Point,_Digits),DoubleToString(ask,_Digits)); else//продажа trade.Sell(inp_lot_size,_Symbol,bid,NormalizeDouble(bid+inp_sl*_Point,_Digits),NormalizeDouble(bid-inp_tp*_Point,_Digits),DoubleToString(bid,_Digits)); }
1.3 Тестирование
Для начала запустим оптимизацию, чтобы иметь представление, при каких значениях входных параметров данный эксперт может прибыльно торговать, или хотя бы открывать какие-то позиции. Оптимизировать будем два параметра — опорную величину для паттернов и уровень Stop Loss в пунктах. Уровню Take Profit установим значение 50 пунктов, паттерны для тестирования выберем все.
Оптимизацию будем проводить на паре EURUSD и таймфрейме M5. Интервал времени: 01.01.2018 — 01.10.2018. Оптимизация быстрая (генетический алгоритм), режим торговли "OHLC на M1".
Значения оптимизируемых параметров выберем в широком диапазоне с большим числом градаций:
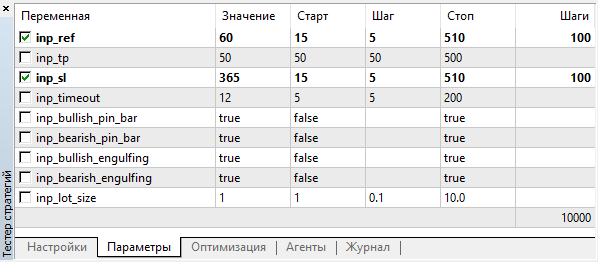
Рис. 3. Параметры оптимизации
После завершения оптимизации результаты отсортируем по размеру прибыли:
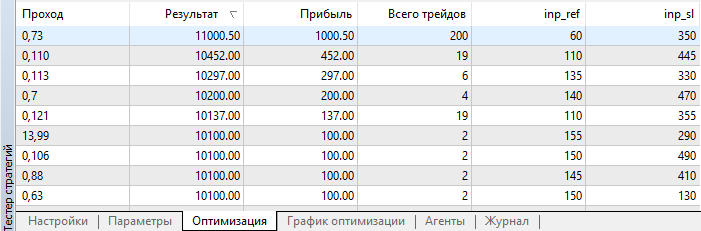
Рис. 4. Результаты оптимизации
Как видим, наилучший результат с прибылью 1000.50 был получен при опорной величине 60 пунктов и уровне Stop Loss 350 пунктов. Запустим тестирование с этими параметрами и обратим внимание на его время выполнения.
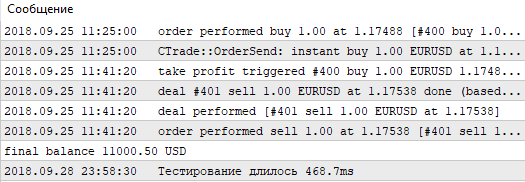
Рис. 5. Время тестирования одиночного прохода штатным тестером
Запомним эти значения и переходим к тестированию этой же стратегии, но уже без привлечения штатного тестера. Напишем свой, используя возможности OpenCL.
2. Реализация на OpenCL
Для работы с OpenCL будем использовать класс COpenCL из стандартной библиотеки с небольшими доработками. Цель доработок в том, чтобы получать максимум информации о возникающих ошибках, но при этом не загромождать код выводами в консоль и условиями. Для этого создадим класс COpenCLx, полный код которого содержится во вложенном файле OpenCLx.mqh:
class COpenCLx : public COpenCL { private: COpenCL *ocl; public: COpenCLx(); ~COpenCLx(); STR_ERROR m_last_error; // структура последней ошибки COCLStat m_stat; // статистика OpenCL //--- работа с буферами bool BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line); template<typename T> bool BufferFromArray(const ENUM_BUFFERS buffer_index,T &data[],const uint data_array_offset,const uint data_array_count,const uint flags,const string function,const int line); template<typename T> bool BufferRead(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); template<typename T> bool BufferWrite(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); //--- установка аргументов template<typename T> bool SetArgument(const ENUM_KERNELS kernel_index,const int arg_index,T value,const string function,const int line); bool SetArgumentBuffer(const ENUM_KERNELS kernel_index,const int arg_index,const ENUM_BUFFERS buffer_index,const string function,const int line); //--- работа с кернелом bool KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line); bool Execute(const ENUM_KERNELS kernel_index,const int work_dim,const uint &work_offset[],const uint &work_size[],const string function,const int line); //--- bool Init(ENUM_INIT_MODE mode); void Deinit(void); };
Как видим, класс содержит указатель на объект COpenCL, а также несколько методов, которые служат обёртками для одноимённых методов класса COpenCL. Каждый из этих методов имеет среди аргументов имя функции и строку, из которой он вызван. Кроме того, вместо индексов кернелов и буферов применены энумераторы. Это сделано для того, чтобы в сообщении об ошибке можно было применить EnumToString(), что намного более информативно, чем просто индекс.
Рассмотрим один из таких методов более детально.
bool COpenCLx::KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL объект не существует",function,line); return false; } //--- Запуск выполнения кернела ::ResetLastError(); if(!ocl.KernelCreate(kernel_index,kernel_name)) { string comment="Ошибка создания кернела "+EnumToString(kernel_index)+", имя \""+kernel_name+"\""; SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_KERNEL_CREATE,comment,function,line); return(false); } //--- return true; }
Здесь две проверки: на существование объекта класса COpenCL и на успешность выполнения метода создания кернела. Но вместо вывода текста функцией Print(), сообщения передаются в макросы, вместе с кодом ошибки, именем функции, и строкой вызова. Эти макросы сохраняют информацию об ошибке в члене класса m_last_error, струкрура которого приведена ниже:
struct STR_ERROR { int code; // код string comment; // комментарий string function; // функция, в которой произошла ошибка int line; // строка, в которой произошла ошибка };
Всего таких макросов четыре. Рассмотрим их по порядку.
Макрос SET_ERR записывает последнюю ошибку выполнения, функцию и строку, из которой он вызван, и комментарий, который передаётся в качестве параметра:
#define SET_ERR(c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
Макрос SET_ERRx аналогичен макросу SET_ERR:
#define SET_ERRx(c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
Отличается тем, что имя функции и строка передаются в качестве параметров. Для чего это сделано? Представьте, что в методе KernelCreate() произошла ошибка. В случае использования макроса SET_ERR мы увидим имя метода KernelCreate(), но намного полезнее знать, откуда был вызван сам метод. Для этого функцию и строку вызова данного метода мы передаём в качестве аргументов, а эти аргументы подставляем в макрос.
Далее, макрос SET_UERR. Он предназначен для записи пользовательских ошибок:
#define SET_UERR(err,c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
В нём, вместо вызова GetLastError(), код ошибки передаётся в качестве параметра. В остальном он аналогичен макросу SET_ERR.
Макрос SET_UERRx предназначен для записи пользовательских ошибок с передачей имени функции и строки вызова в качестве пареметров:
#define SET_UERRx(err,c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
Итак, в случае возникновения ошибки у нас на руках оказывается вся необходимая информация. И самое важное отличие от ошибок, которые выводятся в консоль из класса COpenCL, это конкретизация, о каком именно кернеле идёт речь и откуда вызван метод его создания. Достаточно сравнить вывод из класса COpenCL (верхняя строка) и расширенный вывод из класса COpenCLx (две нижние строки):

Рис. 6. Ошибка создания кернела
Рассмотрим ещё один пример метода-обёртки. А именно, метод создания буфера:
bool COpenCLx::BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL объект не существует",function,line); return false; } //--- учёт и проверка свободной памяти if((m_stat.gpu_mem_usage+=size_in_bytes)==false) { CMemsize cmem=m_stat.gpu_mem_usage.Comp(size_in_bytes); SET_UERRx(UERR_NO_ENOUGH_MEM,"Нет свободной памяти GPU. Не хватает "+cmem.ToStr(),function,line); return false; } //--- создание буфера ::ResetLastError(); if(ocl.BufferCreate(buffer_index,size_in_bytes,flags)==false) { string comment="Ошибка создания буфера "+EnumToString(buffer_index); SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_BUFFER_CREATE,comment,function,line); return(false); } //--- return(true); }
В нём, кроме проверки существования объекта класса COpenCL и результата выполнения операции, есть также функция учета и проверки свободной памяти. Так как мы будем иметь дело с относительно большими объемами памяти (сотни мегабайт), нужно контролировать процесс её расхода. Этим занимается класс СMemsize, полный код которого содержится в файле Memsize.mqh.
Здесь есть одна неприятная мелочь. При всём удобстве отладки, код становится громоздким. Например, код создания буфера будет выглядеть так:
if(BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE,__FUNCTION__,__LINE__)==false) return false;
Здесь есть слишком много лишней информации, которая мешает сосредоточиться на алгоритме. И вот опять на помощь приходят макросы. Каждый из методов-обёрток продублирован макросом, который делает его вызов более компактным. Для метода BufferCreate() это макрос _BufferCreate:
#define _BufferCreate(buffer_index,size_in_bytes,flags) \ if(BufferCreate(buffer_index,size_in_bytes,flags,__FUNCTION__,__LINE__)==false) return false
Благодаря ему, вызов метода создания буфера принимает вид:
_BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
А создание кернелов принимает вид:
_KernelCreate(k_FIND_PATTERNS,"find_patterns");
Здесь нужно обратить внимание, что большинство подобных макросов заканчивается на "return false", кроме _KernelCreate, который заканчивается на "break". Это нужно учитывать при построении кода. Все макросы определены в файле OCLDefines.mqh.
В классе также содержатся методы инициализации и деинициализации. Первый, кроме создания объекта класса COpenCL, также занимается проверкой поддержки double, созданием кернелов, и получением размера доступной памяти:
bool COpenCLx::Init(ENUM_INIT_MODE mode) { if(ocl) Deinit(); //--- создание объекта класса COpenCL ocl=new COpenCL; while(!IsStopped()) { //--- инициализация OpenCL ::ResetLastError(); if(!ocl.Initialize(cl_tester,true)) { SET_ERR("Ошибка инициализации OpenCL"); break; } //--- проверка поддержки работы с double if(!ocl.SupportDouble()) { SET_UERR(UERR_DOUBLE_NOT_SUPP,"Работа с double (cl_khr_fp64) не поддерживается устройством"); break; } //--- установка количества кернелов if(!ocl.SetKernelsCount(OCL_KERNELS_COUNT)) break; //--- создание кернелов if(mode==i_MODE_TESTER) { _KernelCreate(k_FIND_PATTERNS,"find_patterns"); _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_ORDER_TO_M1,"order_to_M1"); _KernelCreate(k_TESTER_STEP,"tester_step"); }else if(mode==i_MODE_OPTIMIZER){ _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_TESTER_OPT_PREPARE,"tester_opt_prepare"); _KernelCreate(k_TESTER_OPT_STEP,"tester_opt_step"); _KernelCreate(k_FIND_PATTERNS_OPT,"find_patterns_opt"); } else break; //--- создание буферов if(!ocl.SetBuffersCount(OCL_BUFFERS_COUNT)) { SET_UERR(UERR_SET_BUF_COUNT,"Ошибка создания буферов"); break; } //--- получения размера оперативной памяти long gpu_mem_size; if(ocl.GetGlobalMemorySize(gpu_mem_size)==false) { SET_UERR(UERR_GET_MEMORY_SIZE,"Ошибка получения размера оперативной памяти"); break; } m_stat.gpu_mem_size.Set(gpu_mem_size); m_stat.gpu_mem_usage.Max(gpu_mem_size); return true; } Deinit(); return false; }
Аргумент mode задаёт режим инициализации. Это может быть оптимизация или одиночное тестирование. В зависимости от этого создаются разные кернелы.
Энумераторы кернелов и буферов объявлены в файле OCLInc.mqh. Там же исходные коды кернелов прикреплены в виде ресурса, как строка cl_tester.
Метод Deinit() удаляет OpenCL программы и объекты:
void COpenCLx::Deinit() { if(ocl!=NULL) { //--- remove OpenCL objects ocl.Shutdown(); delete ocl; ocl=NULL; } }
Теперь, когда созданы все удобства, можно приступить к творчеству. Имея при этом относительно компактный код, и в то же время исчерпывающую информацию об ошибках.
Но для начала нужно загрузить данные, с которыми мы будем работать. И это не так просто, как может показаться на первый взгляд.
2.1 Загрузка ценовых данных
Загрузкой данных занимается класс CBuffering.
class CBuffering { private: string m_symbol; ENUM_TIMEFRAMES m_period; int m_maxbars; uint m_memory_usage; //сколько памяти занято bool m_spread_ena; //загружать буфер спреда datetime m_from; datetime m_to; uint m_timeout; //таймаут загрузки в миллисекундах ulong m_ts_abort; //метка времени в микросекундах, когда нужно прервать операцию //--- принудительная загрузка bool ForceUploading(datetime from,datetime to); public: CBuffering(); ~CBuffering(); //--- количество данных в буферах int Depth; //--- буферы double Open[]; double High[]; double Low[]; double Close[]; double Spread[]; datetime Time[]; //--- получение реальных границ времени загруженных данных datetime TimeFrom(void){return m_from;} datetime TimeTo(void){return m_to;} //--- int Copy(string symbol,ENUM_TIMEFRAMES period,datetime from,datetime to,double point=0); uint GetMemoryUsage(void){return m_memory_usage;} bool SpreadBufEnable(void){return m_spread_ena;} void SpreadBufEnable(bool ena){m_spread_ena=ena;} void SetTimeout(uint timeout){m_timeout=timeout;} };
Мы не будем углубляться в его работу, так как загрузка данных не имеет прямого отношения к теме статьи. Только вкратце рассмотрим его использование.
Класс содержит буферы Open[], High[], Low[], Close[], Time[] и Spread[]. С ними можно работать после успешной отработки метода Copy(). Обратите внимание, что буфер Spread[] имеет тип double, и выражается не в пунктах, а в разнице цен. Кроме того, копирование буфера Spread[] изначально выключено, и при необходимости его нужно включить, используя метод SpreadBufEnable();
Для загрузки используется метод Copy(). Предустановленный аргумент point используется только для пересчёта спреда из пунктов в разницу цен. Если копирование спреда выключено, этот аргумент не используется.
Главные причины, почему для загрузки данных понадобилось создавать отдельный класс, это:
- Невозможность загрузки данных в количестве, превышающем TERMINAL_MAXBARS, при помощи функции CopyTime() и ей подобных.
- Отсутствие гарантий того, что у терминала есть локально эти данные.
Класс CBuffering умеет копировать большие объёмы данных, превышающие TERMINAL_MAXBARS. А также, инициировать загрузку отсутствующих данных с сервера и дожидаться её окончания. Именно из-за этого ожидания следует обратить внимание на метод SetTimeout(), который предназначен для установки максимального времени загрузки данных (включая ожидание) в миллисекундах. По умолчанию, в конструкторе класса установлено значение 5000, то есть 5 секунд. Установка таймаута в ноль отключит его использование. Это крайне нежелательно, но в отдельных случаях может быть полезным.
При этом, всё же действуют некоторые ограничения: данные периода M1 не закачиваются за период больше года, что в какой-то мере сужает диапазон работы нашего тестера.
2.2 Одиночное тестирование
Процесс одиночного тестирования будет состоять из следующих пунктов:
- Загрузка буферов таймсерий
- Инициализация OpenCL
- Копирование буферов таймсерий в буферы OpenCL
- Запуск кернела, который находит паттерны на текущем графике и складывает результаты в буфер ордеров в качестве точек входа в рынок
- Запуск кернела, который переносит ордера на график M1
- Запуск кернела, который считает результаты сделок по ордерам на графике M1 и складывает их в буфер
- Обработка буфера результатов и подсчёт результатов тестирования
- Деинициализация OpenCL
- Удаление буферов таймсерий
Загрузкой таймсерий занимается класс CBuffering. Затем эти данные нужно скопировать в буферы OpenCL, чтобы кернелы могли с ними работать. Для этого предназначен метод LoadTimeseriesOCL(), код которого приведён ниже:
bool CTestPatterns::LoadTimeseriesOCL() { //--- буфер Open: _BufferFromArray(buf_OPEN,m_sbuf.Open,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- буфер High: _BufferFromArray(buf_HIGH,m_sbuf.High,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Low: _BufferFromArray(buf_LOW,m_sbuf.Low,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Close: _BufferFromArray(buf_CLOSE,m_sbuf.Close,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Time: _BufferFromArray(buf_TIME,m_sbuf.Time,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Open (M1): _BufferFromArray(buf_OPEN_M1,m_tbuf.Open,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- буфер High (M1): _BufferFromArray(buf_HIGH_M1,m_tbuf.High,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Low (M1): _BufferFromArray(buf_LOW_M1,m_tbuf.Low,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Close (M1): _BufferFromArray(buf_CLOSE_M1,m_tbuf.Close,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Spread (M1): _BufferFromArray(buf_SPREAD_M1,m_tbuf.Spread,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- буфер Time (M1): _BufferFromArray(buf_TIME_M1,m_tbuf.Time,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- копирование выполнено успешно return true; }
Итак, данные загружены. И мы подошли вплотную к реализации алгоритма тестирования.
2.2.1 Поиск паттернов на OpenCL
Код определения паттерна на OpenCL мало чем отличается от кода на MQL5:
//--- паттерны #define PAT_NONE 0 #define PAT_PINBAR_BEARISH (1<<0) #define PAT_PINBAR_BULLISH (1<<1) #define PAT_ENGULFING_BEARISH (1<<2) #define PAT_ENGULFING_BULLISH (1<<3) //--- цены #define O(i) Open[i] #define H(i) High[i] #define L(i) Low[i] #define C(i) Close[i] //+------------------------------------------------------------------+ //| Проверка наличия паттернов | //+------------------------------------------------------------------+ uint Check(__global double *Open,__global double *High,__global double *Low,__global double *Close,double ref,uint flags) { //--- медвежий пин бар if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-fmax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>fmax(H(0),H(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- бычий пин бар if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=fmin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<fmin(L(0),L(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- медвежье поглощение if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- бычье поглощение if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- ничего не найдено return PAT_NONE; }
Из небольших отличий — передача буферов по указателю, а не по ссылке. Плюс наличие модификатора __global, который указывает на то, что буферы таймсерий находятся в глобальной памяти. Все буферы OpenCL, которые мы будем создавать, находятся в глобальной памяти.
Функцию Check() вызывает кернел find_patterns():
__kernel void find_patterns(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global int *Order, // буфер ордеров __global int *Count, // количество ордеров в буфере const double ref, // параметр паттерна const uint flags) // какие паттерны искать { //--- работает в одном измерении //--- индекс бара size_t x=get_global_id(0); //--- размер пространства поиска паттернов size_t depth=get_global_size(0)-PBARS; if(x>=depth) return; //--- проверка на наличие паттернов uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref,flags); if(res==PAT_NONE) return; //--- установка ордеров if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) {//sell int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL; } else if(res==PAT_PINBAR_BULLISH || res==PAT_ENGULFING_BULLISH) {//buy int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_BUY; } }
Именно его мы будем использовать для поиска паттернов и размещения ордеров в специально отведённом для этого буфере.
Кернел find_patterns() работает в одномерном пространстве задач. При его запуске будет создано то число work-items, которое мы укажем в размере пространства задач для измерения 0. В данном случае это количество баров на текущем периоде. Чтобы понять, какой бар обрабатывается, нужно получить индекс задачи:
size_t x=get_global_id(0);Где ноль — индекс измерения.
Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL;
Чтобы получить этот порядковый номер ордера, используем атомарную функцию atomic_inc(). Дело в том, что в момент выполнения задачи мы понятия не имеем, какие задачи и с какими барами уже выполнены. Это параллельные вычисления, и здесь нет абслютно никакой последовательности ни в чём. И номер задачи никак не связан с количеством уже выполненных задач. Следовательно, мы не знаем, сколько ордеров уже размещено в буфере. Если мы попытаемся прочитать их количество, которое расположено в ячейке 0 буфера Count[], в это же время другая задача может туда что-то писать. Для выхода из подобных ситуаций используются атомарные функции.
В нашем случае функция atomic_inc() для начала запрещает доступ другим задачам к ячейке Count[0], затем увеличивает её значение на единицу, а предыдущее возвращает в виде результата.
int i=atomic_inc(&Count[0]);
Разумеется, это замедляет работу, потому что пока доступ к Count[0] заблокирован, другие задачи просто ждут. Но в некоторых случаях, как и в нашем, другого выхода просто нет.
После того, как будут выполнены все задачи, мы получим сформированный буфер ордеров Order[], и их количество в ячейке Count[0].
2.2.2 Перенос ордеров на таймфрейм M1
Итак, мы нашли паттерны на текущем таймфрейме, но тестирование нужно проводить на таймфрейме M1. Это значит, что для всех найденных на текущем периоде точек входа необходимо найти соответствующие бары на периоде M1. Пользуясь тем, что торговля по паттернам предусматривает относительно небольшое количество точек входа даже на малых таймфреймах, выберем достаточно грубый, но в данном случае вполне подходящий способ.
А именно — перебор. Будем сравнивать время каждого найденного ордера со временем каждого бара периода M1. Для этого создадим кернел order_to_M1():
__kernel void order_to_M1(__global ulong *Time,__global ulong *TimeM1, __global int *Order,__global int *OrderM1, __global int *Count, const ulong shift) // сдвиг по времени в секундах { //--- работает в двух измерениях size_t x=get_global_id(0); //индекс индекса Time в Order if(OrderM1[x*2]>=0) return; size_t y=get_global_id(1); //индекс в TimeM1 if((Time[Order[x*2]]+shift)==TimeM1[y]) { atomic_inc(&Count[1]); //--- по чётным индексам кладём индексы в буфере TimeM1 OrderM1[x*2]=y; //--- по нечётным индексам кладём операции (OP_BUY/OP_SELL) OrderM1[(x*2)+1]=Order[(x*2)+1]; } }
Здесь уже двухмерное пространство задач. Размерность пространства 0 равна количеству установленных ордеров, а размерность пространства 1 равна количеству баров периода M1. При совпадении времени открытия бара ордера и бара M1, в буфер OrderM1[] копируется операция текущего ордера и устанавливается найденный индекс бара в таймсериях периода M1.
Но здесь есть две вещи, которых не должно быть на первый взгляд.
- Первое — это атомарная функция atomic_inc(), которая зачем-то считает найденные точки входа на периоде M1. В измерении 0 каждый ордер работает со своим индексом, а в измерении 1 не может быть более одного совпадения. Значит, попытка общего доступа полностью исключена. Зачем тогда нужно вести подсчёт?
- Второе — аргумент shift, который добавляется ко времени бара текущего периода.
На это есть особые причины. В мире не всё идеально. И наличие бара на графике M5 со временем открытия 01:00:00 совсем не означает наличие бара на графике M1 с таким же временем открытия.
Соответствующий бар на графике М1 может иметь время открытия как 01:01:00, так и 01:04:00. То есть, количество вариаций будет равно соотношению длительности таймфреймов. Именно для этого введена функция подсчёта количества найденных точек входа для периода M1:
atomic_inc(&Count[1]);
Если после завершения работы кернела количество найденных ордеров М1 будет равно количеству найденных ордеров на текущем таймфрейме, значит, задача выполнена в полном объёме. В противном случае понадобится повторный запуск с другим значением аргумента shift. Таких запусков может быть столько, сколько периодов М1 вмещает в себя текущий период.
Чтобы при повторном запуске с ненулевым значением аргумента shift найденные точки входа не были переписаны другими значениями, введена следующая проверка:
if(OrderM1[x*2]>=0) return;
Но для того, чтобы она работала, перед запуском кернела необходимо заполнить буфер OrderM1[] значением -1. Для этого создадим кернел заполнения буфера array_fill():
__kernel void array_fill(__global int *Buf,const int value) { //--- работает в одном измерении size_t x=get_global_id(0); Buf[x]=value; }
2.2.3 Получение результатов сделок
После того, как точки входа на М1 найдены, можно приступить к получению результатов сделок. Для этого понадобится кернел, который будет сопровождать открытые позиции. Другими словами — ждать, пока они закроются по одной из четырёх причин. А именно:
- Достижение уровня Take Profit
- Достижение уровня Stop Loss
- Истечение максимального времени удержания открытой позиции
- Окончание периода тестирования
Пространство задач для кернела будет одномерным и его размер будет равен количеству ордеров. Кернел будет перебирать бары, начиная с бара открытия позиции, и проверять условия, описанные выше. Внутри бара тики будут моделироваться в режиме "1 minute OHLC", который описан в документации в разделе "Тестирование торговых стратегий".
Важно то, что какая-то позиция закроется практически сразу после открытия, какая-то позже, а какая-то вообще по таймауту или окончанию тестирования. Это значит, что время выполнения задач для разных точек входа будет существенно отличаться.
Практика показала, что сопровождение позиции до закрытия за один проход не есть эффективным. Существенно лучшие результаты по быстродействию можно получить, если разбить пространство тестирования (то есть количество баров до принудительного закрытия по истечению времени удержания позиции) на несколько частей, и выполнять обработку за несколько проходов.
Те задачи, которые не завершились на текущем проходе, откладываются на следующий. Таким образом, с каждым проходом размер пространства задач будет уменьшаться. Но чтобы реализовать подобное, необходимо задействовать ещё один буфер для хранения индексов задач. Каждая задача — это индекс точки входа в буфере ордеров. В момент первого запуска содержимое буфера задач будет полностью соответствовать буферу ордеров. При следующих запусках в нём будут находиться индексы тех ордеров, по которым позиции ещё не закрылись. Чтобы иметь возможность работать с буфером задач и в то же время складывать туда задачи для следующего запуска, он должен иметь два банка: с одним банком мы работаем на текущем запуске, а в другом банке формируем задания для следующего.
В работе это будет выглядеть следующим образом. Допустим, у нас 1000 точек входа, по которым нужно получить результаты сделок. Время удержания открытой позиции эквивалентно 800 барам. Мы решили разбить тестирование на 4 прохода. Графически это будет выглядеть так, как изображено на рисунке 7.
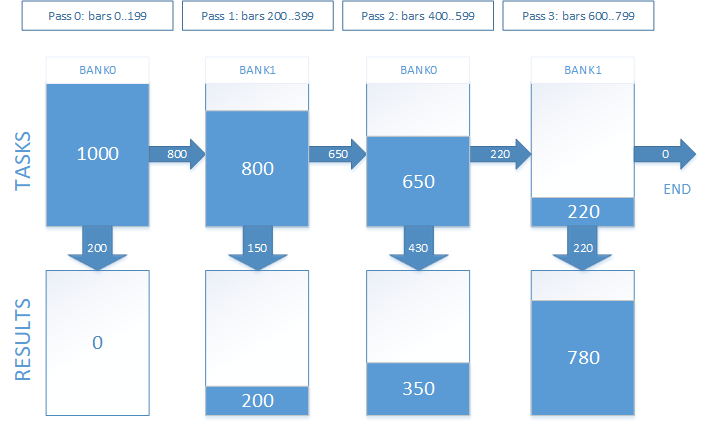
Рис. 7. Выполнение сопровождения открытых позиций за несколько проходов
Опытным путём было установлено оптимальное число проходов, равное 8, для таймаута удержания открытой позиции, равного 12 часов (или 720 минутных баров). Именно это значение установлено по умолчанию. Оно будет варьироваться для разных значений таймаута и разных устройств OpenCL. И рекомендуется к подбору для получения максимальной производительности.
Итак, к аргументам кернела, помимо таймсерий, уже добавился буфер задач Tasks[] и номер банка задач, с которым работаем. Кроме того, добавляем буфер Res[] для сохранения результатов.
Количество актуальных данных в буфере задач возвращается через буфер Left[], который имеет размер два элемента — для каждого из банков соответственно.
Так как тестирование выполняется частями, среди аргументов кернела нужно передать, с какого и по какой бар сопровождать позицию. Это относительная величина, которая суммируется с индексом бара открытия позиции, чтобы получить абсолютный индекс текущего бара в таймсериях. Также, необходимо передать кернелу максимально допустимый индекс бара в таймсериях, чтобы не выйти за пределы буферов.
В результате, набор аргументов кернела tester_step(), который и будет заниматься сопровождением открытых позиций, принимает следующий вид:
__kernel void tester_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1, // выражен в разнице цен, а не в пунктах __global ulong *TimeM1, __global int *OrderM1, // буфер ордеров, где [0] - индекс в OHLC(M1), [1] - операция (Buy/Sell) __global int *Tasks, // буфер задач (открытых позиций), в нём лежат индексы на ордера в буфере OrderM1 __global int *Left, // количество оставшихся задач, два элемента: [0] - для bank0, [1] - для bank1 __global double *Res, // буфер результатов const uint bank, // текущий банк const uint orders, // количество ордеров в OrderM1 const uint start_bar, // какой по счёту бар обрабатывается (как сдвиг от указанного индекса в OrderM1) const uint stop_bar, // по какой бар обрабатывать (включительно) const uint maxbar, // максимально допустимый индекс бара (последний бар массива) const double tp_dP, // TP в разнице цен const double sl_dP, // SL в разнице цен const ulong timeout) // через какое время после открытия закрывать сделку принудительно (в секундах)
Кернел tester_step() работает в одном измерении. Размерность задач этого измерения будет изменяться при каждом вызове, начиная с количества ордеров, и уменьшаясь с каждым проходом.
В самом начале кода кернела мы получаем идентификатор задачи:
size_t id=get_global_id(0);Затем, исходя из индекса текущего банка, который передаётся через аргумент bank, считаем индекс следующего:
uint bank_next=(bank)?0:1;
Вычисляем индекс ордера, с которым будем работать. При первом запуске (при start_bar равном нулю) буфер задач соответствует буферу ордеров, поэтому, индекс ордера равен индексу задачи. При последующих запусках индекс ордера получаем из буфера задач, учитывая текущий банк и индекс задачи:
if(!start_bar) idx=id; else idx=Tasks[(orders*bank)+id];
Зная индекс ордера, получаем индекс бара в таймсериях и код операции:
//--- индекс бара в буфере M1, на котором была открыта позиция uint iO=OrderM1[idx*2]; //--- операция (OP_BUY/OP_SELL) uint op=OrderM1[(idx*2)+1];
Исходя из значения аргумента timeout считаем время принудительного закрытия позиции:
ulong tclose=TimeM1[iO]+timeout;Дальше идёт обработка открытой позиции. Рассмотрим на примере операции BUY (для операции SELL аналогично).
if(op==OP_BUY) { //--- цена открытия позиции double open=OpenM1[iO]+SpreadM1[iO]; double tp = open+tp_dP; double sl = open-sl_dP; double p=0; for(uint j=iO+start_bar; j<=(iO+stop_bar); j++) { for(uint k=0;k<4;k++) { if(k==0) { p=OpenM1[j]; if(j>=maxbar || TimeM1[j]>=tclose) { //--- принудительное закрытие по времени Res[idx]=p-open; return; } } else if(k==1) p=HighM1[j]; else if(k==2) p=LowM1[j]; else p=CloseM1[j]; //--- проверка на срабатывание TP или SL if(p<=sl) { Res[idx]=sl-open; return; } else if(p>=tp) { Res[idx]=tp-open; return; } } } }
Если не сработало ни одно из условий для выхода из кернела, задача откладывается на следующий проход:
uint i=atomic_inc(&Left[bank_next]);
Tasks[(orders*bank_next)+i]=idx;После отрабатывания всех проходов, в буфере Res[] будут находиться результаты всех сделок. Чтобы получить результат тестирования, нужно их просуммировать.
Теперь, когда понятен алгоритм и готовы кернелы, можно приступать к их запуску.
2.3 Запуск тестирования
В этом нам поможет класс CTestPatterns:
class CTestPatterns : private COpenCLx { private: CBuffering *m_sbuf; // Таймсерии текущего периода CBuffering *m_tbuf; // Таймсерии периода M1 int m_prepare_passes; uint m_tester_passes; bool LoadTimeseries(datetime from,datetime to); bool LoadTimeseriesOCL(void); bool test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); bool optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); void buffers_free(void); public: CTestPatterns(); ~CTestPatterns(); //--- запуск одиночного тестирования bool Test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); //--- запуск оптимизации bool Optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); //--- получение указателя на статистику выполнения программы COCLStat *GetStat(void){return &m_stat;} //--- получение кода последней ошибки int GetLastError(void){return m_last_error.code;} //--- получение структуры последней ошибки STR_ERROR GetLastErrorExt(void){return m_last_error;} //--- сброс последней ошибки void ResetLastError(void); //--- на сколько проходов разбить запуск кернела тестирования void SetTesterPasses(uint tp){m_tester_passes=tp;} //--- на сколько проходов разбить запуск кернела подготовки ордеров void SetPrepPasses(int p){m_prepare_passes=p;} };
Рассмотрим детальнее метод Test():
bool CTestPatterns::Test(STR_TEST_RESULT &result,datetime from,datetime to,STR_TEST_PARS &par) { ResetLastError(); m_stat.Reset(); m_stat.time_total.Start(); //--- загрузка данных таймсерий m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- инициализация OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_TESTER)==false) return false; m_stat.time_ocl_init.Stop(); //--- запуск тестирования bool result=test(stat,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return result; }
На входе он имеет диапазон дат, в котором необходимо тестировать стратегию, и ссылки на структуры параметров и результатов тестирования.
В случае успешной работы метод вернёт "true" и запишет результаты в аргумент result. Если в ходе выполнения возникла ошибка, метод вернёт "false", а для получения подробностей об ошибке нужно вызвать GetLastErrorExt().
Сначала загружаем данные таймсерий. Далее производим инициализацию OpenCL. Сюда входит создание объектов и кернелов. Если всё прошло успешно, вызываем метод test(), в котором и реализован весь алгоритм тестирования. По сути, метод Test() служит обёрткой для test(). Это сделано для того, чтобы при любом выходе из метода test всегда была произведена деинициализация и освобождение буферов таймсерий.
В методе test() всё начинается с загрузки буферов таймсерий в буферы OpenCL:if(LoadTimeseriesOCL()==false) return false;
Это делается при помощи метода LoadTimeseriesOCL(), который уже рассматривали выше.
Первым запускается кернел find_patterns(), которому соответствует энумератор k_FIND_PATTERNS. Но перед запуском необходимо создать буферы ордеров и результатов:
_BufferCreate(buf_ORDER,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
Буфер ордеров имеет размер, вдвое больший количества баров на текущем таймфрейме. Так как мы не знаем, сколько паттернов будет найдено, то допускаем, что паттерн будет найден на каждом баре. Эта мера предосторожности кажется на первый взгляд абсурдной, учитывая паттерны, с которыми мы работаем на текущий момент. Но в дальнейшем, при добавлении других паттернов, это может избавить от многих неприятностей.
Далее устанавливаем аргументы:
_SetArgumentBuffer(k_FIND_PATTERNS,0,buf_OPEN); _SetArgumentBuffer(k_FIND_PATTERNS,1,buf_HIGH); _SetArgumentBuffer(k_FIND_PATTERNS,2,buf_LOW); _SetArgumentBuffer(k_FIND_PATTERNS,3,buf_CLOSE); _SetArgumentBuffer(k_FIND_PATTERNS,4,buf_ORDER); _SetArgumentBuffer(k_FIND_PATTERNS,5,buf_COUNT); _SetArgument(k_FIND_PATTERNS,6,double(par.ref)*_Point); _SetArgument(k_FIND_PATTERNS,7,par.flags);
Для кернела find_patterns() зададим одномерное пространство задач с начальным смещением, равным нулю:
uint global_size[1]; global_size[0]=m_sbuf.Depth; uint work_offset[1]={0};
Запускаем выполнение кернела find_patterns():
_Execute(k_FIND_PATTERNS,1,work_offset,global_size);Следует отметить, что выход из метода Execute() не означает, что программа выполнена. Она может ещё выполняться или стоять в очереди на выполнение. Чтобы узнать её состояние на текущий момент, нужно использовать функцию CLExecutionStatus(). Если нужно дождаться завершения выполнения программы, можно периодически опрашивать её состояние. Или выполнить чтение буфера, в который программа помещает результаты. Во втором случае ожидание завершения выполнения программы будет происходить в методе чтения буфера BufferRead().
_BufferRead(buf_COUNT,count,0,0,2);
Теперь в буфере count[] по индексу 0 размещено количество найденных паттернов, или количеству ордеров, размещённых в соответствующем буфере. Следующий шаг — найти соответствующие точки входа на таймфрейме M1. Кернел order_to_M1() будет накапливать найденное количество в том же буфере count[], но по индексу 1. Успешным завершением будет считаться срабатывание условия (count[0]==count[1]).
Но для начала нужно создать буфер ордеров для M1 и заполнить его значением -1. Так как мы уже знаем количество ордеров, укажем точный размер буфера без запаса:
int len=count[0]*2; _BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
Устанавливаем аргументы для кернела array_fill():
_SetArgumentBuffer(k_ARRAY_FILL,0,buf_ORDER_M1); _SetArgument(k_ARRAY_FILL,1,int(-1));
Устанавливаем одномерное пространство задач с начальным смещением, равным нулю, и размером, равным размеру буфера. Запустим выполнение:
uint opt_init_work_size[1]; opt_init_work_size[0]=len; uint opt_init_work_offset[1]={0}; _Execute(k_ARRAY_FILL,1,opt_init_work_offset,opt_init_work_size);
Следующий шаг — подготовка к запуску выполнения кернела order_to_M1():
//--- устанавливаем аргументы _SetArgumentBuffer(k_ORDER_TO_M1,0,buf_TIME); _SetArgumentBuffer(k_ORDER_TO_M1,1,buf_TIME_M1); _SetArgumentBuffer(k_ORDER_TO_M1,2,buf_ORDER); _SetArgumentBuffer(k_ORDER_TO_M1,3,buf_ORDER_M1); _SetArgumentBuffer(k_ORDER_TO_M1,4,buf_COUNT); //--- пространство задач для кернела k_ORDER_TO_M1 - двухмерное uint global_work_size[2]; //--- 1-е измерение это ордеры, оставленные кернелом k_FIND_PATTERNS global_work_size[0]=count[0]; //--- 2-е измерение это все бары графика M1 global_work_size[1]=m_tbuf.Depth; //--- начальное смещение в пространстве задач для обоих измерений равно нулю uint global_work_offset[2]={0,0};
Аргумент под индексом 5 не был установлен, потому что его значение будет разным и его установка будет производиться непосредственно перед запуском выполнения кернела. По причине, оговоренной выше, выполнение кернела order_to_M1() может понадобиться несколько раз с разным значением смещения в секундах. Максимальное количество запусков будет ограничено соотношением длительностей периодов текущего графика и графика M1:
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1);
Весь цикл будет выглядеть следующим образом:
for(int s=0;s<maxshift;s++) { //--- установка смещения для текущего прохода _SetArgument(k_ORDER_TO_M1,5,ulong(s*60)); //--- выполниение кернела _Execute(k_ORDER_TO_M1,2,global_work_offset,global_work_size); //--- читаю результатов _BufferRead(buf_COUNT,count,0,0,2); //--- по индексу 0 находится количество ордеров на текущем графике //--- по индексу 1 находится количество найденных соответствующих им баров на графике М1 //--- оба значения совпадают, выходим из цикла if(count[0]==count[1]) break; //--- в противном случае, идём на следующую итерацию и запускаем кернел с другим смещением } //--- на случай, если мы вышли из цикла не по break, проверим ещё раз соответствие количества ордеров if(count[0]!=count[1]) { SET_UERRt(UERR_ORDERS_PREPARE,"Ошибка подготовки ордеров M1"); return false; }
Пришло время запустить кернел tester_step(), который посчитает результаты сделок, открытых по найденным точкам входа. Для начала создадим недостающие буферы и установим аргументы:
//--- создаём буфер Tasks, в котором будет формироваться количество задач для следующего прохода _BufferCreate(buf_TASKS,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); //--- создаём буфер Result, в который будут складываться результаты сделок _BufferCreate(buf_RESULT,m_sbuf.Depth*sizeof(double),CL_MEM_READ_WRITE); //--- уствновим аргументы для кернела одиночного тестирования _SetArgumentBuffer(k_TESTER_STEP,0,buf_OPEN_M1); _SetArgumentBuffer(k_TESTER_STEP,1,buf_HIGH_M1); _SetArgumentBuffer(k_TESTER_STEP,2,buf_LOW_M1); _SetArgumentBuffer(k_TESTER_STEP,3,buf_CLOSE_M1); _SetArgumentBuffer(k_TESTER_STEP,4,buf_SPREAD_M1); _SetArgumentBuffer(k_TESTER_STEP,5,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_STEP,6,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_STEP,7,buf_TASKS); _SetArgumentBuffer(k_TESTER_STEP,8,buf_COUNT); _SetArgumentBuffer(k_TESTER_STEP,9,buf_RESULT); uint orders_count=count[0]; _SetArgument(k_TESTER_STEP,11,uint(orders_count)); _SetArgument(k_TESTER_STEP,14,uint(m_tbuf.Depth-1)); _SetArgument(k_TESTER_STEP,15, double(par.tp)*_Point); _SetArgument(k_TESTER_STEP,16, double(par.sl)*_Point); _SetArgument(k_TESTER_STEP,17,ulong(par.timeout));
Затем пересчитаем максимальное время удержания позиции в количество баров на графике M1:
uint maxdepth=(par.timeout/PeriodSeconds(PERIOD_M1))+1;
Далее проверим на корректность заданное количество проходов выполнения кернела. По умолчанию его значение равно 8, но с целью подбора оптимальной производительности для разных устройств OpenCL допускается установка других значений при помощи метода SetTesterPasses().
if(m_tester_passes<1) m_tester_passes=1; if(m_tester_passes>maxdepth) m_tester_passes=maxdepth; uint step_size=maxdepth/m_tester_passes;
Установим размер пространства задач для единственного измерения, и запускаем цикл расчёта результатов сделок:
global_size[0]=orders_count; m_stat.time_ocl_test.Start(); for(uint i=0;i<m_tester_passes;i++) { //--- установка индекса текущего банка _SetArgument(k_TESTER_STEP,10,uint(i&0x01)); uint start_bar=i*step_size; //--- установка индекса бара, с которого начнётся тестирование в текущем проходе _SetArgument(k_TESTER_STEP,12,start_bar); //--- установка индекса бара, на котором закончится тестирование в текущем проходе (включительно) uint stop_bar=(i==(m_tester_passes-1))?(m_tbuf.Depth-1):(start_bar+step_size-1); _SetArgument(k_TESTER_STEP,13,stop_bar); //--- обнуление количества задач в следующем банке //--- в нём сейчас будет формироваться количество ордеров, которые остались на следующий проход count[(~i)&0x01]=0; _BufferWrite(buf_COUNT,count,0,0,2); //--- запуск выполнения кернела тестирования _Execute(k_TESTER_STEP,1,work_offset,global_size); //--- чтение количества ордеров, которые остались на следующий проход _BufferRead(buf_COUNT,count,0,0,2); //--- устанавливаем новое количество задач, которое равно числу этих ордеров global_size[0]=count[(~i)&0x01]; //--- если задач не осталось, выходим из цикла if(!global_size[0]) break; } m_stat.time_ocl_test.Stop();
Создаём буфер для чтения результатов сделок:
double Result[]; ArrayResize(Result,orders_count); _BufferRead(buf_RESULT,Result,0,0,orders_count);
Чтобы получить результаты, которые можно сравнить с результатами штатного тестера, прочитанные значения нужно будет разделить на _Point. Код подсчёта результата и статистики тестирования приведён ниже:
m_stat.time_proc.Start(); result.trades_total=0; result.gross_loss=0; result.gross_profit=0; result.net_profit=0; result.loss_trades=0; result.profit_trades=0; for(uint i=0;i<orders_count;i++) { double r=Result[i]/_Point; if(r>=0) { result.gross_profit+=r; result.profit_trades++; }else{ result.gross_loss+=r; result.loss_trades++; } } result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; m_stat.time_proc.Stop();
Напишем короткий скрипт, который позволит нам запустить наш тестер.
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- установка параметров тестирования STR_TEST_PARS pars; pars.ref= 60; pars.sl = 350; pars.tp = 50; pars.flags=15; // все паттерны pars.timeout=12*3600; //--- структура результатов STR_TEST_RESULT res; //--- запуск тестирования tpat.Test(res,from,to,pars); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- результаты тестирования Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //--- статистика выполнения COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
Диапазон времени тестирования, а также символ и период, выбраны те, на которых мы запускали тестирование эксперта, реализованного на MQL5. Значения опорной величины и уровня Stop Loss установлены те, что были найдены в процессе оптимизации. Осталось запустить скрипт и сравнить полученный результат с результатом штатного тестера.
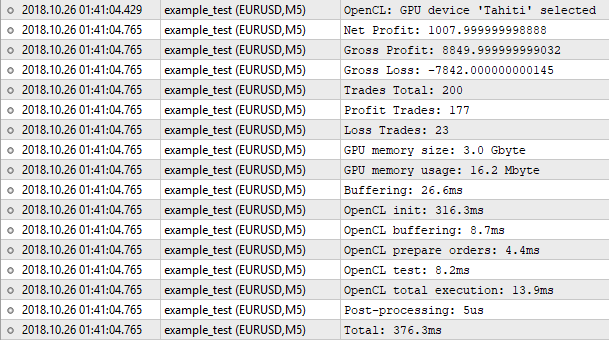
Рис.8. Результаты тестера, реализованного на OpenCL
Итак, количество трейдов совпадает. А вот значение чистой прибыли — нет. Штатный тестер показывает число 1000.50, а наш 1007.99. Всё дело в следующем. Чтобы добиться таких же результатов, нужно учитывать, как минимум, своп. Но его внедрение в наш тестер будет не оправдано. Для грубой оценки, где и применяется тестирование в режиме OHLC на M1, подобными мелочами можно пренебречь. Важно то, что результат очень близок, значит, наш алгоритм работает правильно.
Теперь обратим внимание на статистику выполнения программы. Памяти заняли не много, всего лишь 16 мегабайт. Времени больше всего ушло на инициализацию OpenCL. Весь процесс тестирования при этом занял 376 миллисекунд, что почти один-в-один соизмеримо со штатным тестером. Ожидать какого-то прироста производительности здесь не стоит. При количестве 200 трейдов больше времени уйдёт на накладные расходы: инициализация, копирование буферов, и так далее. Чтобы ощутить разницу, нужно в сотни раз больше ордеров для тестирования. Пора переходить к оптимизации.
2.4. Оптимизация
Алгоритм оптимизации будет похож на алгоритм одиночного тестирования, но в то же время будет иметь одно принципиальное отличие. Если в тестере мы сначала искали паттерны, а потом считали результаты сделок, то здесь будет всё наоборот. Мы сначала посчитаем результаты сделок, а потом уже приступим к поиску паттернов. На это есть причина.
У нас два оптимизируемых параметра. Первый — это опорная величина для нахождения паттернов. Второй — уровень Stop Loss, который участвует в процессе рассчёта результата сделки. То есть, один из них влияет на количество точек входа, а второй на результаты сделок и продолжительность сопровождения открытой позиции. Если сохранить ту же последовательность действий, что и в алгоритме одиночного тестирования, нам не избежать повторного тестирования одних и тех же точек входа, а это колоссальная потеря времени. Потому что пин бар с "хвостом" в 300 пунктов будет найден при любых значениях опорной величины, кооторая равна или меньше данного значения.
Поэтому, в нашем случае намного экономичнее посчитать результаты сделок с точками входа на каждом баре (включая и покупку, и продажу), а затем уже оперировать этими данными в процессе поиска паттернов. Таким образом, последовательность действий при оптимизации будет следующая:
- Загрузка буферов таймсерий
- Инициализация OpenCL
- Копирование буферов таймсерий в буферы OpenCL
- Запуск кернела подготовки ордеров (на каждый бар текущего таймфрейма по два ордера - покупка и продажа)
- Запуск кернела, который переносит ордера на график M1
- Запуск
кернела, который считает результаты сделок по ордерам
- Запуск кернела, который находит паттерны и формирует результаты тестирования для каждой комбинации оптимизируемых параметров из готовых результатов сделок
- Обработка буфера результатов и нахождение оптимизируемых параметров, соотвуетствующих наилучшему результату
- Деинициализация OpenCL
- Удаление буферов таймсерий
Кроме того, количество задач для поиска паттернов будет умножено на количество значений опорной величины, а количество задач для расчёта результатов сделок будет умножено на количество значений уровня Stop Loss.
2.4.1 Подготовка ордеров
Мы допускаем, что искомые паттерны могут быть найдены на любом баре. Это значит, что на каждом баре нужно установить ордер на покупку и продажу. При этом размер буфера ордеров можно выразить через формулу:
N = Depth*4*SL_count;
где Depth - размер буферов таймсерий, а SL_count - количество значений Stop Loss.
Кроме того, индексы баров должны быть из таймсерий M1. Кернел tester_opt_prepare() будет искать в таймсериях M1 бары с таким временем открытия, которое соответствует времени открытия баров текущего периода, и укладывать их в буфер ордеров в указанном выше формате. В целом, его работа будет очень похожей на работу кернела order_to_M1():
__kernel void tester_opt_prepare(__global ulong *Time,__global ulong *TimeM1, __global int *OrderM1,// буфер ордеров __global int *Count, const int SL_count, // количество значений SL const ulong shift) // сдвиг по времени в секундах { //--- работает в двух измерениях size_t x=get_global_id(0); //индекс в Time if(OrderM1[x*SL_count*4]>=0) return; size_t y=get_global_id(1); //индекс в TimeM1 if((Time[x]+shift)==TimeM1[y]) { //--- попутно нахожу максимальный индекс бара для периода М1 atomic_max(&Count[1],y); uint offset=x*SL_count*4; for(int i=0;i<SL_count;i++) { uint idx=offset+i*4; //--- для каждого бара добавляю два ордера: покупку и продажу OrderM1[idx++]=y; OrderM1[idx++]=OP_BUY |(i<<2); OrderM1[idx++]=y; OrderM1[idx] =OP_SELL|(i<<2); } atomic_inc(&Count[0]); } }
Но будет иметь одно важное отличие — нахождение максимального индекса таймсерий M1. Сейчас объясню, зачем это сделано.
В случае с тестированием одиночного прохода, мы имели дело с относительно малым количеством ордеров. И количество задач, которое равняется количеству ордеров, умноженному на размер буферов таймсерий M1, был также невелик. Если взять во внимание те данные, на которых мы производили тестирование, то это 200 ордеров, умноженные на 279039 баров М1, что в итоге даёт 55,8 миллионов задач.
В текущей ситуации количество задач будет значительно большим. К примеру, это 279039 баров M1, умноженные на 55843 бара текущего периода (M5), что равняется 15,6 миллиардам задач. А ещё стоит учесть, что придётся запускать этот кернел повторно с другим значением сдвига по времени. Здесь метод перебора будет слишком затратным.
Для решения этого вопроса мы всё же оставим перебор, но разобьём диапазон обработки баров текущего периода на несколько частей. Также ограничим и диапазон соответствующих им минутных баров. Но так как расчётное значение индекса верхней границы диапазона минутных баров будет в большинстве случаев больше фактического, то через Count[1] мы будет возвращать максимальный индекс минутного бара, чтобы следующий проход начать с этого места.
2.4.2 Получение результатов сделок
После подготовки ордеров можно приступать к получению результатов сделок.
Кернел tester_opt_step() будет очень похож на tester_step(). Поэтому я не буду приводить код целиком, рассмотрю только отличия. Во-первых, изменились входные параметры:
__kernel void tester_opt_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1,// выражен в разнице цен, а не в пунктах __global ulong *TimeM1, __global int *OrderM1, // буфер ордеров, где [0] - индекс в OHLC(M1), [1] - операция (Buy/Sell) __global int *Tasks, // буфер задач (открытых позиций), в нём лежат индексы на ордера в буфере OrderM1 __global int *Left, // количество оставшихся задач, два элемента: [0] - для bank0, [1] - для bank1 __global double *Res, // буфер результатов, складываются по мере получения, const uint bank, // текущий банк const uint orders, // количество ордеров в OrderM1 const uint start_bar, // какой по счёту бар обрабатывается (как сдвиг от указанного индекса в OrderM1) - по сути, "i" из цикла, запускающего кернел const uint stop_bar, // по какой бар обрабатывать (включительно) - для большинства случаев будет равен значению bar const uint maxbar, // максимально допустимый индекс бара (последний бар массива) const double tp_dP, // TP в разнице цен const uint sl_start, // SL в пунктах - начальное значение const uint sl_step, // SL в пунктах - шаг const ulong timeout, // через какое время после открытия закрывать сделку принудительно (в секундах) const double point) // _Point
Вместо аргумента sl_dP, через который передавалось значение уровня SL, выраженное в разнице цен, добавилось два аргумента: sl_start и sl_step, а также аргумент point. Теперь, чтобы посчитать значение уровня SL, нужно применить формулу:
SL = (sl_start+sl_step*sli)*point;
где sli — индекс значения Stop Loss, который содержится в ордере.
Второе отличие — это код получения индекса sli из буфера ордеров:
//--- операция (биты 1:0) и индекс SL (биты 9:2) uint opsl=OrderM1[(idx*2)+1]; //--- получим индекс SL uint sli=opsl>>2;
В остальном код идентичен кернелу tester_step().
После выполнения мы получим в буфере Res[] результаты покупки и продажи для каждого бара и каждого из значений Stop Loss.
2.4.3 Поиск паттернов и формирование результатов тестирования
В отличии от тестирования, здесь мы будем суммировать результаты сделок прямо в кернеле, а не в коде MQL. В этом есть один неприятный минус — придётся переводить результаты в целочисленный тип, что обязательно даст потерю точности. Именно по этой причине в аргументе point следует передавать значение _Point делённое на 100.
Вынужденный перевод результатов в тип int обусловлент тем, что атомарные функции не работают с типом double. А для суммирования результатов мы будем использовать atomic_add().
Кернел find_patterns_opt() будет работать в трехмерном пространстве задач:
- Измерение 0: индекс бара на текущем таймфрейме
- Измерение 1: индекс значения опорной величины для паттернов
- Измерение 2: индекс значения уровня Stop Loss
В процессе работы будет формироваться буфер результатов, который будет содержать статистику тестирования для каждой комбинации уровня Stop Loss и опорной величины. Под статистикой тестирования подразумевается структура, которая содержит следующие величины:
- Общая прибыль
- Общий убыток
- Количество прибыльных трейдов
- Количество убыточных трейдов
Все они имеют тип int. Исходя из них можно также вычислить чистую прибыль и общее количество трейдов. Код кернела приведён ниже:
__kernel void find_patterns_opt(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global double *Test, // буфер результатов тестирования для каждого бара, размер 2*x*z ([0]-buy, [1]-sell ... ) __global int *Results, // буфер результатов, размер 4*y*z const double ref_start, // параметр паттерна const double ref_step, // const uint flags, // какие паттерны искать const double point) // _Point/100 { //--- работает в трёх измерениях //--- индекс бара size_t x=get_global_id(0); //--- индекс значения ref size_t y=get_global_id(1); //--- индекс значения SL size_t z=get_global_id(2); //--- количество баров size_t x_sz=get_global_size(0); //--- количество значений ref size_t y_sz=get_global_size(1); //--- количество значений sl size_t z_sz=get_global_size(2); //--- размер пространства поиска паттернов size_t depth=x_sz-PBARS; if(x>=depth)//рядом с концом буфера не открываюсь return; // uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref_start+ref_step*y,flags); if(res==PAT_NONE) return; //--- считаем индекс результата сделки в буфере Test[] int ri; if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) //sell ri = (x+PBARS)*z_sz*2+z*2+1; else //buy ri=(x+PBARS)*z_sz*2+z*2; //--- получаем результат по рассчитанному индексу и переводим в центы int r=Test[ri]/point; //--- считаем индекс результатов тестирования в буфере Results[] int idx=z*y_sz*4+y*4; //--- добавляем результат сделки по текущему паттерну if(r>=0) {//--- profit //--- суммируем общую прибыль в центах atomic_add(&Results[idx],r); //--- увеличиваем количество прибыльных сделок atomic_inc(&Results[idx+2]); } else {//--- loss //--- суммируем общий убыток в центах atomic_add(&Results[idx+1],r); //--- увеличиваем количество убыточных сделок atomic_inc(&Results[idx+3]); } }
Буфер Test[] в аргументах — это результаты, полученные после выполнения кернела tester_opt_step().
2.5 Запуск оптимизации
Код запуска выполнения кернелов из MQL5 в процессе оптимизации построен аналогично процессу тестирования. Публичный метод Optimize() является обёрткой метода optimize() в котором реализован порядок подготовки и запуск выполнения кернелов.
bool CTestPatterns::Optimize(STR_TEST_RESULT &result,datetime from,datetime to,STR_OPT_PARS &par) { ResetLastError(); if(par.sl.step<=0 || par.sl.stop<par.sl.start || par.ref.step<=0 || par.ref.stop<par.ref.start) { SET_UERR(UERR_OPT_PARS,"Параметры оптимизации заданы неверно"); return false; } m_stat.Reset(); m_stat.time_total.Start(); //--- загрузка данных таймсерий m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- инициализация OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_OPTIMIZER)==false) return false; m_stat.time_ocl_init.Stop(); //--- запуск оптимизации bool res=optimize(result,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return res; }
Не будем подробно рассматривать каждую строку, разберём только те места, которые отличаются. А именно, запуск кернела tester_opt_prepare().
Для начала создадим буфер для контроля количества обработанных баров и возврата максимального индекса бара М1:
int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
Затем устанавливаем аргументы и размеры пространства задач.
_SetArgumentBuffer(k_TESTER_OPT_PREPARE,0,buf_TIME); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,1,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,2,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,3,buf_COUNT); _SetArgument(k_TESTER_OPT_PREPARE,4,int(slc)); // количество значений SL //--- кернел k_TESTER_OPT_PREPARE будет иметь двухмерное пространство задач uint global_work_size[2]; //--- 0-е измерение - это ордера на текущем периоде global_work_size[0]=m_sbuf.Depth; //--- 1-е измерение - все бары М1 global_work_size[1]=m_tbuf.Depth; //--- для первого запуска установим смещение в пространстве задач равным нулю для обоих измерений uint global_work_offset[2]={0,0};
Смещение в пространстве задач 1-го измерения будем увеличивать после обработки части баров. Его значение будет равно максимальному значению бара М1, которое вернёт кернел, увеличенному на 1.
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1); int prep_step=m_sbuf.Depth/m_prepare_passes; for(int p=0;p<m_prepare_passes;p++) { //оффсет для пространства задач текущего периода global_work_offset[0]=p*prep_step; //оффсет для пространства задач периода M1 global_work_offset[1]=count[1]; //размерность задач для текущего периода global_work_size[0]=(p<(m_prepare_passes-1))?prep_step:(m_sbuf.Depth-global_work_offset[0]); //размерность задач для периода M1 uint sz=maxshift*global_work_size[0]; uint sz_max=m_tbuf.Depth-global_work_offset[1]; global_work_size[1]=(sz>sz_max)?sz_max:sz; // count[0]=0; _BufferWrite(buf_COUNT,count,0,0,2); for(int s=0;s<maxshift;s++) { _SetArgument(k_TESTER_OPT_PREPARE,5,ulong(s*60)); //--- execute kernel _Execute(k_TESTER_OPT_PREPARE,2,global_work_offset,global_work_size); //--- читаю результат (количество должно совпадать с m_sbuf.Depth) _BufferRead(buf_COUNT,count,0,0,2); if(count[0]==global_work_size[0]) break; } count[1]++; } if(count[0]!=global_work_size[0]) { SET_UERRt(UERR_ORDERS_PREPARE,"Ошибка подготовки ордеров M1"); return false; }
Параметр m_prepare_passes означает количество проходов, на которые нужно разбить процесс подготовки ордеров. По умолчанию его значение равно 64, изменить его можно при помощи метода SetPrepPasses().
После чтения результатов тестирования в буфер OptResults[], выполняется поиск такой комбинации оптимизируемых параметров, при которой была получена максимальная чистая прибыль.
int max_profit=-2147483648; uint idx_ref_best= 0; uint idx_sl_best = 0; for(uint i=0;i<refc;i++) for(uint j=0;j<slc;j++) { uint idx=j*refc*4+i*4; int profit=OptResults[idx]+OptResults[idx+1]; //sum+=profit; if(max_profit<profit) { max_profit=profit; idx_ref_best= i; idx_sl_best = j; } }
После чего пересчитываем результаты в double и устанавливаем искомые значения оптимизируемых параметров в соответствующую структуру.
uint idx=idx_sl_best*refc*4+idx_ref_best*4; result.gross_profit=double(OptResults[idx])/100; result.gross_loss=double(OptResults[idx+1])/100; result.profit_trades=OptResults[idx+2]; result.loss_trades=OptResults[idx+3]; result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; //--- par.ref.value= int(par.ref.start+idx_ref_best*par.ref.step); par.sl.value = int(par.sl.start+idx_sl_best*par.sl.step);
Нужно учитывать, что перевод из int в double и обратно обязательно скажется на значениях результатов, и они будут немного отличаться от тех, что получены при одиночном тестировании.
Напишем небольшой скрипт для запуска оптимизации:
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- установка параметров оптимизации STR_OPT_PARS optpar; optpar.ref.start = 15; optpar.ref.step = 5; optpar.ref.stop = 510; optpar.sl.start = 15; optpar.sl.step = 5; optpar.sl.stop = 510; optpar.flags=15; optpar.tp=50; optpar.timeout=12*3600; //--- структура результатов STR_TEST_RESULT res; //--- запуск оптимизации tpat.Optimize(res,from,to,optpar); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- значения оптимизируемых параметров Print("Ref: ",optpar.ref.value,", SL: ",optpar.sl.value); //--- результаты тестирования Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //--- статистика выполнения COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
Входные параметры подставлены те же, которые мы использовали при оптимизации на штатном тестере. Запускаем:
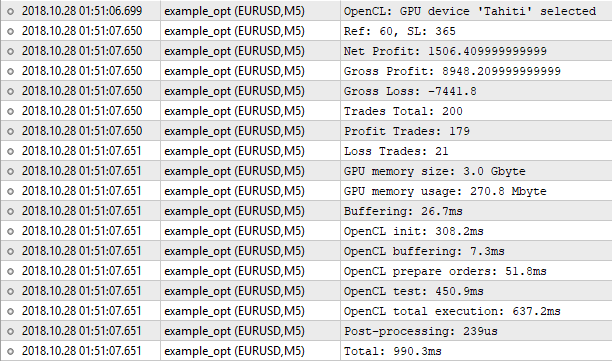
Рис. 9. Оптимизация на тестере OpenCL
И видим, что результаты совершенно не совпадают с теми, что были найдены штатным тестером. Почему так произошло? Неужели потеря точности при переводе double в int и обратно сыграла решающую роль? Теоретически, если результаты отличались долями после запятой, такое могло произойти. Но результаты отличаются существенно.
Штатный тестер нашёл значения Ref = 60 и SL = 350 при чистой прибыли 1000.50. Наш OpenCL тестер нашёл значения Ref = 60 и SL = 365 при чистой прибыли 1506.40. Попробуем запустить штатный тестер со значениями, которые нашёл тестер OpenCL:

Рис. 10. Проверка результатов оптимизации, найденных тестером OpenCL
Результат очень похож на наш. Значит, это не потеря точности. Это генетический алгоритм пропустил данную комбинацию оптимизируемых параметров. Запустим встроенный тестер в режиме медленной оптимизации, с полным перебором параметров.
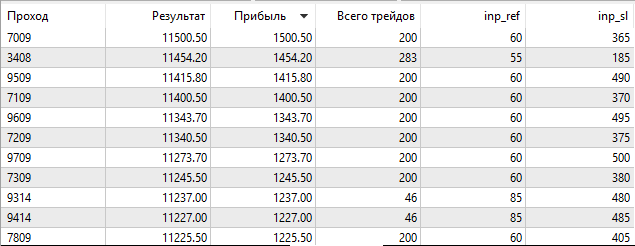
Рис. 11. Запуск встроенного тестера стратегий в режиме медленной оптимизации
И видим, что в режиме полного перебора параметров встроенный тестер нашёл те же искомые значения Ref = 60 и SL = 365, что и наш OpenCL тестер. Это значит, что реализованный нами алгоритм оптимизации работает правильно.
3. Сравнение производительности
Пришло время сравнить производительность штатного тестера и тестера, реализованного с применением OpenCL.
Сравнивать будем временные затраты на оптимизацию параметров описанной выше стратегии. Встроенный тестер будем запускать в двух режимах: быстрой оптимизации (генетический алгоритм) и медленной (полный перебор параметров). Запуск будет производиться на ПК со следующими характеристиками:
| Операционная система | Windows 10 (build 17134) x64 |
| Процессор | AMD FX-8300 Eight-Core Processor, 3600MHz |
| Объём ОЗУ | 24574 Mb |
| Тип носителя, на котором установлен MetaTrader | HDD |
Для агентов тестирования выделено 6 ядер из 8-ми.
Тестер OpenCL будет запускаться на видеоадаптере AMD Radeon HD 7950 с объёмом памяти 3Gb и частотой GPU 800Mhz.
Оптимизацию будем проводить на трёх парах: EURUSD, GBPUSD и USDJPY. При чём, на каждой паре выполним её на четырёх временных диапазонах для каждого из режимов оптимизации, для которых примем следующие сокращения:
| Режим оптимизации | Описание |
|---|---|
| Tester Fast | Встроенный тестер стратегий, генетический алгоритм |
| Tester Slow | Встроенный тестер стратегий, полный перебор параметров |
| Tester OpenCL | Тестер, реализованный с применением OpenCL |
Обозначения диапазонов тестирования:
| Период | Интервал дат |
|---|---|
| 1 месяц | 2018.09.01 - 2018.10.01 |
| 3 месяца | 2018.07.01 - 2018.10.01 |
| 6 месяцев | 2018.04.01 - 2018.10.01 |
| 9 месяцев | 2018.01.01 - 2018.10.01 |
Из полученных результатов для нас будут важны значения искомых памаетров, величина чистой прибыли, количество трейдов, и время, потраченное на оптимизацию.
3.1. Оптимизация на паре EURUSD
Период H1, 1 месяц:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 15 | 15 | 15 |
| Stop Loss | 330 | 510 | 500 |
| Чистая прибыль | 942.5 | 954.8 | 909.59 |
| Количество трейдов | 48 | 48 | 47 |
| Длительность оптимизации | 10 сек | 6 мин 2 сек | 405.8 мс |
Период H1, 3 месяца:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 50 | 65 | 70 |
| Stop Loss | 250 | 235 | 235 |
| Чистая прибыль | 1233.8 | 1503.8 | 1428.35 |
| Количество трейдов | 110 | 89 | 76 |
| Длительность оптимизации | 9 сек | 8 мин 8 сек | 457.9 мс |
Период H1, 6 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 15 | 20 | 20 |
| Stop Loss | 455 | 435 | 435 |
| Чистая прибыль | 1641.9 | 1981.9 | 1977.42 |
| Количество трейдов | 325 | 318 | 317 |
| Длительность оптимизации | 15 сек | 11 мин 13 сек | 405.5 мс |
Период H1, 9 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 15 | 15 | 15 |
| Stop Loss | 440 | 435 | 435 |
| Чистая прибыль | 1162.0 | 1313.7 | 1715.77 |
| Количество трейдов | 521 | 521 | 520 |
| Длительность оптимизации | 20 сек | 16 мин 44 сек | 438.4 мс |
Период M5, 1 месяц:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 135 | 45 | 45 |
| Stop Loss | 270 | 205 | 205 |
| Чистая прибыль | 47 | 417 | 419.67 |
| Количество трейдов | 1 | 39 | 39 |
| Длительность оптимизации | 7 сек | 9 мин 27 сек | 418 мс |
Период M5, 3 месяца:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 120 | 70 | 70 |
| Stop Loss | 440 | 405 | 405 |
| Чистая прибыль | 147 | 342 | 344.85 |
| Количество трейдов | 3 | 16 | 16 |
| Длительность оптимизации | 11 сек | 8 мин 25 сек | 585.9 мс |
Период M5, 6 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 85 | 70 | 70 |
| Stop Loss | 440 | 470 | 470 |
| Чистая прибыль | 607 | 787 | 739.6 |
| Количество трейдов | 22 | 47 | 46 |
| Длительность оптимизации | 21 сек | 12 мин 03 сек | 796.3 мс |
Период M5, 9 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 60 | 60 | 60 |
| Stop Loss | 495 | 365 | 365 |
| Чистая прибыль | 1343.7 | 1500.5 | 1506.4 |
| Количество трейдов | 200 | 200 | 200 |
| Длительность оптимизации | 20 сек | 16 мин 44 сек | 438.4 мс |
3.2. Оптимизация на паре GBPUSD
Период H1, 1 месяц:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 175 | 90 | 90 |
| Stop Loss | 435 | 185 | 185 |
| Чистая прибыль | 143.40 | 173.4 | 179.91 |
| Количество трейдов | 3 | 13 | 13 |
| Длительность оптимизации | 10 сек | 4 мин 33 сек | 385.1 мс |
Период H1, 3 месяца:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 175 | 145 | 145 |
| Stop Loss | 225 | 335 | 335 |
| Чистая прибыль | 93.40 | 427 | 435.84 |
| Количество трейдов | 13 | 19 | 19 |
| Длительность оптимизации | 12 сек | 7 мин 37 сек | 364.5 мс |
Период H1, 6 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 165 | 170 | 165 |
| Stop Loss | 230 | 335 | 335 |
| Чистая прибыль | 797.40 | 841.2 | 904.72 |
| Количество трейдов | 31 | 31 | 32 |
| Длительность оптимизации | 18 сек | 11 мин 3 сек | 403.6 мс |
Период H1, 9 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 165 | 165 | 165 |
| Stop Loss | 380 | 245 | 245 |
| Чистая прибыль | 1303.8 | 1441.6 | 1503.33 |
| Количество трейдов | 74 | 74 | 75 |
| Длительность оптимизации | 24 сек | 19 мин 23 сек | 428.5 мс |
Период M5, 1 месяц:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 335 | 45 | 45 |
| Stop Loss | 450 | 485 | 485 |
| Чистая прибыль | 50 | 484.6 | 538.15 |
| Количество трейдов | 1 | 104 | 105 |
| Длительность оптимизации | 12 сек | 9 мин 42 сек | 412.8 мс |
Период M5, 3 месяца:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 450 | 105 | 105 |
| Stop Loss | 440 | 240 | 240 |
| Чистая прибыль | 0 | 220 | 219.88 |
| Количество трейдов | 0 | 16 | 16 |
| Длительность оптимизации | 15 сек | 8 мин 17 сек | 552.6 мс |
Период M5, 6 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 510 | 105 | 105 |
| Stop Loss | 420 | 260 | 260 |
| Чистая прибыль | 0 | 220 | 219.82 |
| Количество трейдов | 0 | 23 | 23 |
| Длительность оптимизации | 24 сек | 14 мин 58 сек | 796.5 мс |
Период M5, 9 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 185 | 195 | 185 |
| Stop Loss | 205 | 160 | 160 |
| Чистая прибыль | 195 | 240 | 239.92 |
| Количество трейдов | 9 | 9 | 9 |
| Длительность оптимизации | 25 сек | 20 мин 58 сек | 4.4 мс |
3.3. Оптимизация на паре USDJPY
Период H1, 1 месяц:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 60 | 50 | 50 |
| Stop Loss | 425 | 510 | 315 |
| Чистая прибыль | 658.19 | 700.14 | 833.81 |
| Количество трейдов | 18 | 24 | 24 |
| Длительность оптимизации | 6 сек | 4 мин 33 сек | 387.2 мс |
Период H1, 3 месяца:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 75 | 55 | 55 |
| Stop Loss | 510 | 510 | 460 |
| Чистая прибыль | 970.99 | 1433.95 | 1642.38 |
| Количество трейдов | 50 | 82 | 82 |
| Длительность оптимизации | 10 сек | 6 мин 32 сек | 369 мс |
Период H1, 6 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 150 | 150 | 150 |
| Stop Loss | 345 | 330 | 330 |
| Чистая прибыль | 273.35 | 287.14 | 319.88 |
| Количество трейдов | 14 | 14 | 14 |
| Длительность оптимизации | 17 сек | 11 мин 25 сек | 409.2 мс |
Период H1, 9 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 190 | 190 | 190 |
| Stop Loss | 425 | 510 | 485 |
| Чистая прибыль | 244.51 | 693.86 | 755.84 |
| Количество трейдов | 16 | 16 | 16 |
| Длительность оптимизации | 24 сек | 17 мин 47 сек | 445.3 мс |
Период M5, 1 месяц:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 30 | 35 | 35 |
| Stop Loss | 225 | 100 | 100 |
| Чистая прибыль | 373.60 | 623.73 | 699.79 |
| Количество трейдов | 53 | 35 | 35 |
| Длительность оптимизации | 7 сек | 4 мин 34 сек | 415.4 мс |
Период M5, 3 месяца:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 45 | 40 | 40 |
| Stop Loss | 335 | 250 | 250 |
| Чистая прибыль | 1199.34 | 1960.96 | 2181.21 |
| Количество трейдов | 71 | 99 | 99 |
| Длительность оптимизации | 12 сек | 8 мин | 607.2 мс |
Период M5, 6 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 130 | 40 | 40 |
| Stop Loss | 400 | 130 | 130 |
| Чистая прибыль | 181.12 | 1733.9 | 1908.77 |
| Количество трейдов | 4 | 229 | 229 |
| Длительность оптимизации | 19 сек | 12 мин 31 сек | 844 мс |
Период M5, 9 месяцев:
| Результат | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 35 | 30 | 30 |
| Stop Loss | 460 | 500 | 500 |
| Чистая прибыль | 3701.30 | 5612.16 | 6094.31 |
| Количество трейдов | 681 | 1091 | 1091 |
| Длительность оптимизации | 34 сек | 18 мин 56 сек | 1 сек |
3.4. Сводная таблица соотношения производительности
Исходя из полученных результатов видно, что штатный тестер в режиме быстрой оптимизации (генетический алгоритм) часто пропускает лучшие результаты. Поэтому, производительность относительно тестера OpenCL справедливее будет сравнивать в режиме полного перебора параметров. Для наглядности составим сводную таблицу затрат времени на оптимизацию.
| Условия оптимизации | Tester Slow | Tester OpenCL | Ratio |
|---|---|---|---|
| EURUSD, H1, 1 месяц | 6 мин 2 сек | 405.8 мс | 891 |
| EURUSD, H1, 3 месяца | 8 мин 8 сек | 457.9 мс | 1065 |
| EURUSD, H1, 6 месяцев | 11 мин 13 сек | 405.5 мс | 1657 |
| EURUSD, H1, 9 месяцев | 16 мин 44 сек | 438.4 мс | 2292 |
| EURUSD, M5, 1 месяц | 9 мин 27 сек | 418 мс | 1356 |
| EURUSD, M5, 3 месяца | 8 мин 25 сек | 585.9 мс | 861 |
| EURUSD, M5, 6 месяцев | 12 мин 3 сек | 796.3 мс | 908 |
| EURUSD, M5, 9 месяцев | 17 мин 39 сек | 1 сек | 1059 |
| GBPUSD, H1, 1 месяц | 4 мин 33 сек | 385.1 мс | 708 |
| GBPUSD, H1, 3 месяца | 7 мин 37 сек | 364.5 мс | 1253 |
| GBPUSD, H1, 6 месяцев | 11 мин 3 сек | 403.6 мс | 1642 |
| GBPUSD, H1, 9 месяцев | 19 мин 23 сек | 428.5 мс | 2714 |
| GBPUSD, M5, 1 месяц | 9 мин 42 сек | 412.8 мс | 1409 |
| GBPUSD, M5, 3 месяца | 8 мин 17 сек | 552.6 мс | 899 |
| GBPUSD, M5, 6 месяцев | 14 мин 58 сек | 796.4 мс | 1127 |
| GBPUSD, M5, 9 месяцев | 20 мин 58 сек | 970.4 мс | 1296 |
| USDJPY, H1, 1 месяц | 4 мин 33 сек | 387.2 мс | 705 |
| USDJPY, H1, 3 месяца | 6 мин 32 сек | 369 мс | 1062 |
| USDJPY, H1, 6 месяцев | 11 мин 25 сек | 409.2 мс | 1673 |
| USDJPY, H1, 9 месяцев | 17 мин 47 сек | 455.3 мс | 2396 |
| USDJPY, M5, 1 месяц | 4 мин 34 сек | 415.4 мс | 659 |
| USDJPY, M5, 3 месяца | 8 мин | 607.2 мс | 790 |
| USDJPY, M5, 6 месяцев | 12 мин 31 сек | 844 мс | 889 |
| USDJPY, M5, 9 месяцев | 18 мин 56 сек | 1 сек | 1136 |
Заключение
В данной статье мы реализовали алгоритм построения тестера простейшей торговой стратегии с применением OpenCL. Безусловно, данная реализация является всего лишь одним из возможных решений, и имеет множество недостатков. Среди них:
- Работа в режиме OHLC на M1, что годится только для грубой оценки
- Нет учёта свопов и комиссий
- Некорректная работа с кросс-курсами
- Нет трейлинг-стопа
- Нет учёта числа одновременно открытых позиций
- Среди возвращаемых параметров нет значения просадки
Тем не менее, данный алгоритм может серьёзно помочь в тех случаях, когда нужно быстро и грубо оценить работоспособность простейших паттернов, потому что позволяет делать это в тысячи раз быстрее встроенного тестера, запущенного в режиме полного перебора параметров, и в десятки раз быстрее тестера, использующего генетический алгоритм.