L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 3009
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Ma soprattutto, deve essere dimostrato teoricamente che il potere predittivo delle caratteristiche disponibili non cambia, o cambia debolmente, in futuro. In tutto il rullo compressore, questa è la cosa più importante.
Purtroppo nessuno l'ha trovata, altrimenti non sarebbe qui ma sulle isole tropicali))))
Sì. Anche 1 albero o una regressione possono trovare un modello se c'è e non cambia.
1. Qualcun altro ha una coppia insegnante-tratto con un errore di classificazione inferiore al 20%?
Facile. Posso decongestionare decine di set di dati. Sto esaminando ora TP=50 e SL=500. C'è un errore medio del 10% nel punteggio dell'insegnante. Se è del 20%, sarà un modello di prugna.
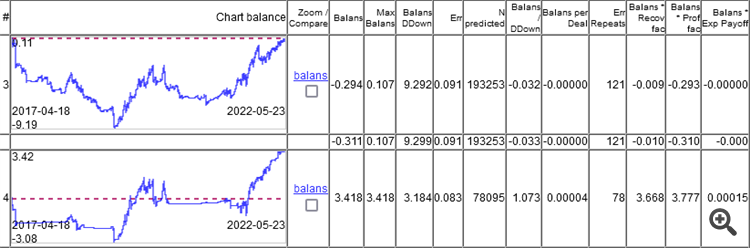
Quindi il punto non è nell'errore di classificazione, ma nel risultato della somma di tutti i profitti e le perdite.
Come si può vedere, il modello top ha un errore del 9,1%, e si può guadagnare qualcosa con un errore dell'8,3%.
I grafici mostrano solo gli OOS, ottenuti da Walking Forward con riqualificazione una volta alla settimana, per un totale di 264 riqualificazioni in 5 anni.
È interessante che il modello abbia funzionato a 0 con un errore di classificazione del 9,1%, e 50/500 = 0,1, cioè il 10% dovrebbe essere. Si scopre che l'1% ha mangiato lo spread (minimo per barra, quello reale sarà più grande).
Per prima cosa bisogna rendersi conto che il modello è pieno di spazzatura al suo interno...
Se si scompone un modello di legno addestrato nelle regole interne e nelle statistiche relative a tali regole.
come :
e si analizza la dipendenza dell'errore della regola errata dalla frequenza della sua presenza nel campione.
otteniamo
Allora siamo interessati a quest'area
Dove le regole funzionano molto bene, ma sono così rare che ha senso dubitare dell'autenticità delle statistiche su di esse, perché 10-30 osservazioni non sono statistiche.
Per prima cosa bisogna rendersi conto che il modello è pieno di rifiuti all'interno...
Se si scompone un modello di legno addestrato nelle regole interne e nelle statistiche relative a tali regole.
come:
e analizzare la dipendenza dell'errore della regola err dalla frequenza di occorrenza nel campione.
otteniamo
Solo un raggio di sole nell'oscurità dei post recenti
ci sarà un articolo a riguardo, se ci sarà.
ci sarà un articolo al riguardo, se ci sarà.
Norm, il mio ultimo articolo parlava della stessa cosa. Ma se il tuo metodo è più veloce, è un vantaggio.
Cosa intendi per "più veloce"?
Cosa intendi per "più veloce"?
In termini di velocità.
circa 5-15 secondi su un campione di 5 km
circa 5-15 secondi su un campione di 5k.
Intendo l'intero processo, dall'inizio all'ottenimento del TC.
Ho due modelli che vengono riqualificati più volte, quindi non è molto veloce, ma è accettabile.
E alla fine non so che cosa abbiano esattamente eliminato.
Voglio dire, l'intero processo, dall'inizio fino all'ottenimento della TC.
Ho 2 modelli che vengono riqualificati più volte, quindi non sono molto veloci, ma accettabili.
e alla fine non so cosa abbiano selezionato esattamente.
Addestramento 5k.
Valido 60k.
formazione del modello - 1-3 secondi
estrazione delle regole - 5-10 secondi
verifica della validità di ogni regola (20-30k regole) 60k 1-2 minuti
Naturalmente tutto è approssimativo e dipende dal numero di caratteristiche e di dati.