Codes et pratiques élégants - page 2
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Bonjour à tous,
Voici ma méthode pour débuguer mes codes tout en les gardant propres et bien structurés.
Au niveau global, je me crée des variables clairement identifiables comme étant des valeurs de test :
À quoi servent ces variables ?
Elles permettent d’éviter que des valeurs de test oubliées traînent dans le code une fois le débug terminé.
Comme elles sont toutes regroupées au même endroit, il suffit de commenter leur déclaration pour que le compilateur signale rapidement leur utilisation dans le code.
Cela facilite la maintenance : je garde toutes mes variables de test pour pouvoir reprendre rapidement mes anciens projets si une mise à jour est nécessaire.
Il me suffit alors de les réactiver globalement lorsque j’en ai besoin. Et en prime, je trouve cette méthode assez élégante — c’est justement l’idée que je voulais partager dans ce fil.
Si cela peut vous aider, tant mieux !
Elle peut survenir à n’importe quel moment de la vie d’un Expert Advisor :
au tick 1, au tick 42, ou en plein rallye de marché.
ET PAS UNIQUEMENT POUR DES HISTOIRES DE SERVEUR SYNCHRONISER
À ceux qui se plaisent à répéter:
STOP. C’est faux, simpliste et carrément dangereux pour ceux qui codent sérieusement.
La vérité que certains refusent d’entendre :
L’erreur peut surgir même lorsque les séries sont prêtes, synchronisées, et validées.
Elle frappe en pleine session live, entre deux ticks, à la reprise du terminal, ou après un simple changement de symbole — peu importe que tout soit “disponible”.
Elle se produit dans des environnements chargés, en multi-symboles, ou quand l’EA fait des appels rapides. 💬 Et parfois... juste parce que le terminal a ses humeurs.
Quand on manipule des structures 2D ou 3D, typiquement des tableaux de struct ou des array imbriqués, le debug devient vite laborieux.
Le problème ? Le débogueur vous affiche toute l’arborescence, ce qui rend la lecture impossible dès que les dimensions dépassent quelques entrées.
Prenons cette structure simple :
Dans le debug, vous verrez toutes les valeurs de grid[0][0..99] , puis celles de grid[1][0..99] , etc.
Mais si vous cherchez à inspecter rapidement grid[1] , vous devrez scroller comme un damné, ou plier et déplier sans fin sans jamais avoir les deux en même temps.
Pas facile de debuger dans ces conditions
L’astuce : créer des buffers temporaires
Pour rendre le debug lisible, créez des structures temporaires ciblées :
ce qui dans le debug, sera nettement plus accessible comme vous pouvez le voir
Bien entendu Test0x_grid sont à assigner avec les bonnes valeurs
et comme pour la pratique des g_test* vu plus haut, le fait de commenter les lignes de code
après vos tests vous permettrons de nettoyer très rapidement votre code
Pratique et élégant
Avec la dernière mise à jour de MetaTrader vers la version 5200, j'ai remarqué un avertissement lié à la classe native CCanvas , et plus spécifiquement à la méthode PolygonNormalize .
L'avertissement est le suivant : 'CPoint' using assignment operator, this behavior is deprecated and will be removed in future Canvas.mqh 2898 17
Il indique que l'opérateur d'assignation pour la structure CPoint sera déprécié à l'avenir. J'ai donc cherché une solution pour corriger cette méthode.
Je vous propose une version améliorée de cette fonction qui non seulement corrige l'avertissement, mais adhère également à de meilleures pratiques de codage.
Le code original avec la correction
Voici à quoi ressemble la méthode originale après la correction de l'avertissement.
J'ai également revu l'ensemble du code pour le rendre plus clair et plus facile à comprendre. Un code lisible est crucial, car il réduit la charge cognitive et simplifie la maintenance. J'aimerais insister sur l'importance de quelques points :
Des commentaires clairs qui expliquent la logique, ce qui est la base pour un bon code.
Une signature de méthode et des noms de variables explicites, qui aident à comprendre le code au premier coup d'œil, sans avoir à deviner à quoi servent imin , xmin , ou p .
Un cartouche d'information complet qui décrit précisément ce que fait la fonction, ses paramètres et son retour.
Voici une version révisée qui illustre ces bonnes pratiques :
Bonjour
Je voulais partager un tout petit bout de code qui parle de macro
qu'importe à quoi elle peut servir.
Dans certaines limites, c'est très pratique.
Déjà quand vous faite du debug en pas à pas, vous ne voyez pas le code.
Et c'est ce que je préfère le plus mais ne tombez pas dans le piège vous n'avez aucun contrôle de type par exemple
il faut qu'une macro reste simple,
surtout pas des instructions complexes qui s'enchaine, préféré alors le MQL5
Bonjour à tous,
Si, comme moi,
vous avez des fonctions ou méthodes susceptibles de retourner des erreurs, avec une distinction entre erreurs mineures et critiques,
voici un extrait de logique qui permet de gérer cet aspect de manière structurée et efficace :
Explication rapide :
Si le retour est inférieur à un seuil défini (ZERO_ERROR_THRESHOLD), la méthode est considérée comme en erreur.
La méthode Handle_Error_Code() sert uniquement à générer un message informatif selon la catégorie de l’erreur.
La responsabilité de la gestion de l’erreur reste dans CheckIfRequestExists().
Les macros comme IS_WARN_ERROR() ou IS_CRIT_ERROR() permettent de sélectionner le bon code de retour selon la gravité.
Avantages :
Code plus lisible et modulaire, mais proche du code générique
Gestion centralisée des messages
Facilité d’extension pour d’autres types d’erreurs
Si vous avez des approches similaires ou des idées pour rendre ce genre de logique encore plus élégante,
n’hésitez pas à les partager !
Bonjour à tous,
J’adore les enum en MQL5. Elles sont incroyablement pratiques et permettent de structurer le code de manière claire et robuste.
Voici un exemple d’énumération que j’utilise :
enum Position_Signal { POSITION_LONG_LIMIT = 11, POSITION_LONG_STOP = 12, POSITION_LONG_EXIT = 2, POSITION_LONG = 1, POSITION_NONE = 0, POSITION_SHORT = -1, POSITION_SHORT_EXIT = -2, POSITION_SHORT_LIMIT = -11, POSITION_SHORT_STOP = -12, POSITION_INITIALIZATION = -1000 };On peut facilement créer un tableau de cette énumération
Jusqu’ici, rien de surprenant. Mais ce qui est intéressant, c’est la sécurité offerte par le compilateur.
Si vous essayez d’affecter une valeur qui n’est pas définie dans l’énumération :
Le compilateur vous arrêtera immédiatement avec un message clair : cannot convert -400 to enum 'Position_Signal'
C’est une sécurité passive, qui fonctionne uniquement à la compilation. En revanche, à l’exécution, si vous assignez une valeur dynamique, rien ne garantit qu’elle soit valide :
Cela peut introduire des comportements imprévus si la valeur ne correspond à aucun des éléments de l’énumération.
Pour pallier cela, je recommande d’ajouter une vérification comme celle-ci :
A vos codes et partages
Je voulais partager un petit bout de code qui, bien que simple, peut vraiment vous faciliter la vie lorsque vous gérez des niveaux dans vos indicateurs MQL5.
L'idée est de combiner un enum pour les valeurs des niveaux et une simple variable i_Index pour les parcourir.
enum Enum_value_Grid :
Elle nous permet de définir et de nommer clairement tous les niveaux que l'on veut afficher (100, 75, 50, etc.).
C'est beaucoup plus lisible que d'utiliser des nombres en dur dans le code.
Surtout, si vous avez besoin d'ajouter, de supprimer ou de modifier un niveau, vous n'avez qu'à toucher à l'énumération, et le reste du code reste intact.
i_Index :
On utilise cette variable comme un compteur pour attribuer les niveaux un par un.
À chaque fois qu'on configure un niveau, on incrémente l'index (i_Index ++).
Cela garantit que chaque niveau est correctement positionné, sans se soucier de l'ordre.
Si vous ajoutez un niveau entre deux existants, il vous suffit d'insérer le code, et l'index s'occupe du reste.
Le code ci-dessous montre comment cette méthode est appliquée.
On voit clairement la configuration de chaque niveau, de la valeur à la couleur, le tout en exploitant les valeurs de l'enum et en utilisant l'index.
ca donne ceci
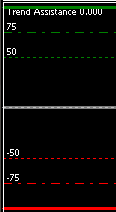
J'espère que cette astuce vous sera utile. N'hésitez pas à partager vos propres méthodes pour gérer ce genre de choses
Ps
je me demande si les francophones développent vu le peu de réponse à mon sujet.
comme vous pouvez le voir