Discussion of article "Backpropagation Neural Networks using MQL5 Matrices"
More thanks to Stanislav! Finally an article about neural networks using native matrices has been written....
By the way. Just today I found out that there is a new block in the Documentation concerning ML.

- www.mql5.com
Thanks to the author for the detailed article and for the honest conclusions.
"Those things I forgot, you don't even know yet" - that's how the author could respond to such criticism.
"Those things I've forgotten you don't even know yet" is how an author might respond to such criticism.
There are two aspects and it is important:
1. Execution, technical part, universality, praised even by maturing programmers. And here indeed, I can't and won't and haven't tried to criticise the code. I'm talking about something else:
2. Testing. The author pointed out that all his models work. In fact, when you press the "Start" button in the tester, a random picture for the forward 2 weeks appears, out of 10 presses 5 - plum, 5 - profit. Naturally, if you put such a thing on the real - 50/50 viability of your depot. This is not the case. On my questions about what it is and how to fix it, the author said that it should be like this, it is the principle of the model. Well here I fell out simply, no words.
Two months I tried to start these networks, they did not want to work on NVIDIA, thanks Aleksey Vyazmikin, rewrote the author's code and everything worked on 3080. And in the end - inoperable models. It is doubly offensive.
But if I offended/offended you, I apologise, I had no such purpose.
matrix temp; if(!outputs[n].Derivative(temp, of))
In the backpropagation ,the derivative functions expect to receive x and not activation of x (unless they changed it recently for the activation functions it applies to)
Here is an example :
#property version "1.00" int OnInit() { //--- double values[]; matrix vValues; int total=20; double start=-1.0; double step=0.1; ArrayResize(values,total,0); vValues.Init(20,1); for(int i=0;i<total;i++){ values[i]=sigmoid(start); vValues[i][0]=start; start+=step; } matrix activations; vValues.Activation(activations,AF_SIGMOID); //print sigmoid for(int i=0;i<total;i++){ Print("sigmoidDV("+values[i]+")sigmoidVV("+activations[i][0]+")"); } //derivatives matrix derivatives; activations.Derivative(derivatives,AF_SIGMOID); for(int i=0;i<total;i++){ values[i]=sigmoid_derivative(values[i]); Print("dDV("+values[i]+")dVV("+derivatives[i][0]+")"); } //--- return(INIT_SUCCEEDED); } double sigmoid(double of){ return((1.0/(1.0+MathExp((-1.0*of))))); } double sigmoid_derivative(double output){ return(output*(1-output)); }
Also theres Activation functions for which you can send in more inputs both in the activation and the derivation , like the elu for instance
Derivative(output,AF_ELU,alpha); Activation(output,AF_ELU,alpha);
In the backpropagation ,the derivative functions expect to receive x and not activation of x (unless they changed it recently for the activation functions it applies to)
I'm not sure what you mean. There are formulae in the article, which are converted into the lines of source code exactly. The outputs are obtained with Activation call during feedforward stage, and then we take their derivatives on backpropagation. Probably you missed that indexing of output arrays in the classes are with +1 bias to the indexing of layer weights.
I'm not sure what you mean. There are formulae in the article, which are converted into the lines of source code exactly. The outputs are obtained with Activation call during feedforward stage, and then we take their derivatives on backpropagation. Probably you missed that indexing of output arrays in the classes are with +1 bias to the indexing of layer weights.
Yes the temp matrix is multiplied by the weights and then output[] contains the activation values .
In the back prop you are taking the derivations of these activation values while the MatrixVector derivative function expects you to send the temp values

heres the difference in derivatives
Allow me to simplify it :
#property version "1.00" int OnInit() { //--- //lets assume x is the output of the previous layer (*) weights of a node //the value that goes in activation . double x=3; //we get the sigmoid by the formula below double activation_of_x=sigmoid(x); //and for the derivative we do double derivative_of_activation_of_x=sigmoid_derivative(activation_of_x); //we do this with matrixvector vector vX; vX.Init(1); vX[0]=3; //we create a vector for activations vector vActivation_of_x; vX.Activation(vActivation_of_x,AF_SIGMOID); //we create a vector for derivations vector vDerivative_of_activation_of_x,vDerivative_of_x; vActivation_of_x.Derivative(vDerivative_of_activation_of_x,AF_SIGMOID); vX.Derivative(vDerivative_of_x,AF_SIGMOID); Print("NormalActivation("+activation_of_x+")"); Print("vector Activation("+vActivation_of_x[0]+")"); Print("NormalDerivative("+derivative_of_activation_of_x+")"); Print("vector Derivative Of Activation Of X ("+vDerivative_of_activation_of_x[0]+")"); Print("vector Derivative Of X ("+vDerivative_of_x[0]+")"); //you are doing vector derivative of activation of x which returns the wrong value //vectorMatrix expects you to send x not the activation(x) //--- return(INIT_SUCCEEDED); } double sigmoid(double of){ return((1.0/(1.0+MathExp((-1.0*of))))); } double sigmoid_derivative(double output){ return(output*(1-output)); }
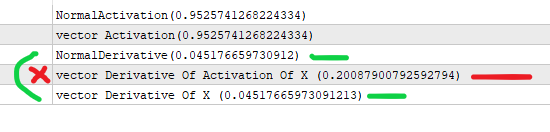
I see your point. Indeed, sigmoid derivative is formulated via 'y', that is through sigmoid value at point x, that is y(x): y'(x) = y(x)*(1-y(x)). This is exactly how the codes in the article implemented.
Your test script calculates "derivative" taking x as input, not y, hence the values are different.
I see your point. Indeed, sigmoid derivative is formulated via 'y', that is through sigmoid value at point x, that is y(x): y'(x) = y(x)*(1-y(x)). This is exactly how the codes in the article implemented.
Your test script calculates "derivative" taking x as input, not y, hence the values are different.
Yes but the activation values are passed to the derivation function while it expects the pre-activation values. That's what i'm saying .
And you missed the point there , the correct value is with the x as input . (the correct value according to mq's function itself)
You are not storing the output_of_previous * weights somewhere (i think) , which is what should be sent in the derivation functions (according to mq's function itself again , i'll stress that)
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Backpropagation Neural Networks using MQL5 Matrices has been published:
The article describes the theory and practice of applying the backpropagation algorithm in MQL5 using matrices. It provides ready-made classes along with script, indicator and Expert Advisor examples.
As we will see below, MQL5 provides a large set of built-in activation functions. The choice of a function should be made based on the specific problem (regression, classification). Usually, it is possible to select several functions and then experimentally find the optimal one.
Popular activation functions
Activation functions can have different value ranges, limited or unlimited. In particular, the sigmoid (3) maps the data into the range [0,+1], which is better for classification problems, while the hyperbolic tangent maps data into the range [-1,+1], which is assumed better for regression and forecasting problems.
Author: Stanislav Korotky