Discussion of article "Neural networks made easy (Part 28): Policy gradient algorithm"
 Good afternoon.
Good afternoon.
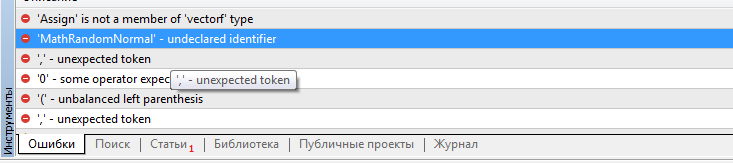
Dmitry, where to get the functions values.Assign and MathRandomNormal ? Your scripts are not built and refer to the absence of these functions. The file VAE.mqh is rejected.
Good afternoon.
Dmitry, where to get the functions values.Assign and MathRandomNormal ? Your scripts are not built and refer to the absence of these functions. The file VAE.mqh is rejected.
Good day, Victor.
Regarding values.Assign, try to update the terminal. This is a built-in function recently added to MQL5. MathRandomNormal is included in the standard library of the terminal and is added in the file "\MQL5\Include\Math\Stat\Normal.mqh" .
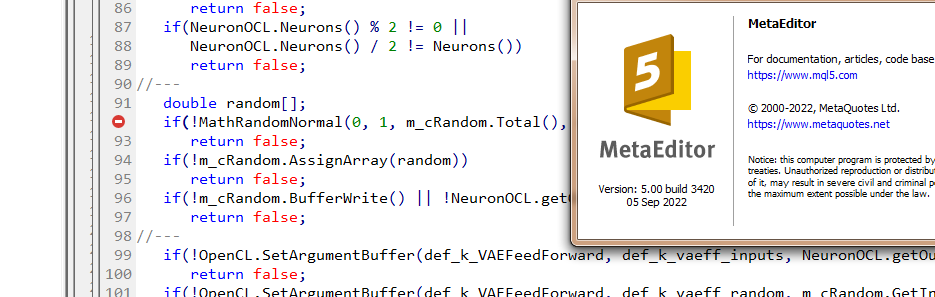
Dmitry I have terminal version 3391 dated 5 August 2022 (last stable version). Now I tried to upgrade to beta version 3420 from 5 September 2022. The error with values.Assign is gone. But the error with MathRandomNormal does not go away. I have a library with this function on the path as you wrote. But in the VAE.mqh file you don't have a reference to this library, but in the NeuroNet.mqh file you specify this library as follows:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
But that's not how I have it assembled. :(
PS: If I specify the path to the library directly in the VAE.mqh file. Is it possible to do that? I don't really understand how you set the library in the NeuroNet.mqh file , won't there be a conflict?
I tried adding the #include <Math\Stat\Normal . mqh> line directly in the VAE .mqh file , but it didn't work. The compiler still writes 'MathRandomNormal' - undeclared identifier VAE.mqh 92 8. If you erase this function and start typing again, a tooltip with this function appears, which, as I understand, indicates that it can be seen from the VAE.mqh file.
In general, I tried on another computer with a different even version of the vinda, and the result is the same - does not see the function and does not compile. mt5 latest version betta 3420 from 5 September 2022.
Dmitry, do you have any settings enabled in the editor?
In general, I tried it on another computer with a different version of Windows, and the result is the same - it does not see the function and does not compile. mt5 latest version betta 3420 from 5 September 2022.
Dmitry, do you have any settings enabled in the editor?
Try commenting out the"namespace Math" line
Dmitry I have terminal version 3391 dated 5 August 2022 (last stable version). Now I tried to upgrade to beta version 3420 from 5 September 2022. The error with values.Assign is gone. But the error with MathRandomNormal does not go away. I have a library with this function on the path as you wrote. But in the VAE.mqh file you don't have a reference to this library, but in the NeuroNet.mqh file you specify this library as follows:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
But that's not how I'm getting it together. :(
PS: If directly in the file VAE.mqh specify the path to the library. Is it possible to do that? I don't really understand how you set the library in the NeuroNet.mqh file , won't there be a conflict?
3445 dated 23 September - same thing.
 Hello.
Hello.
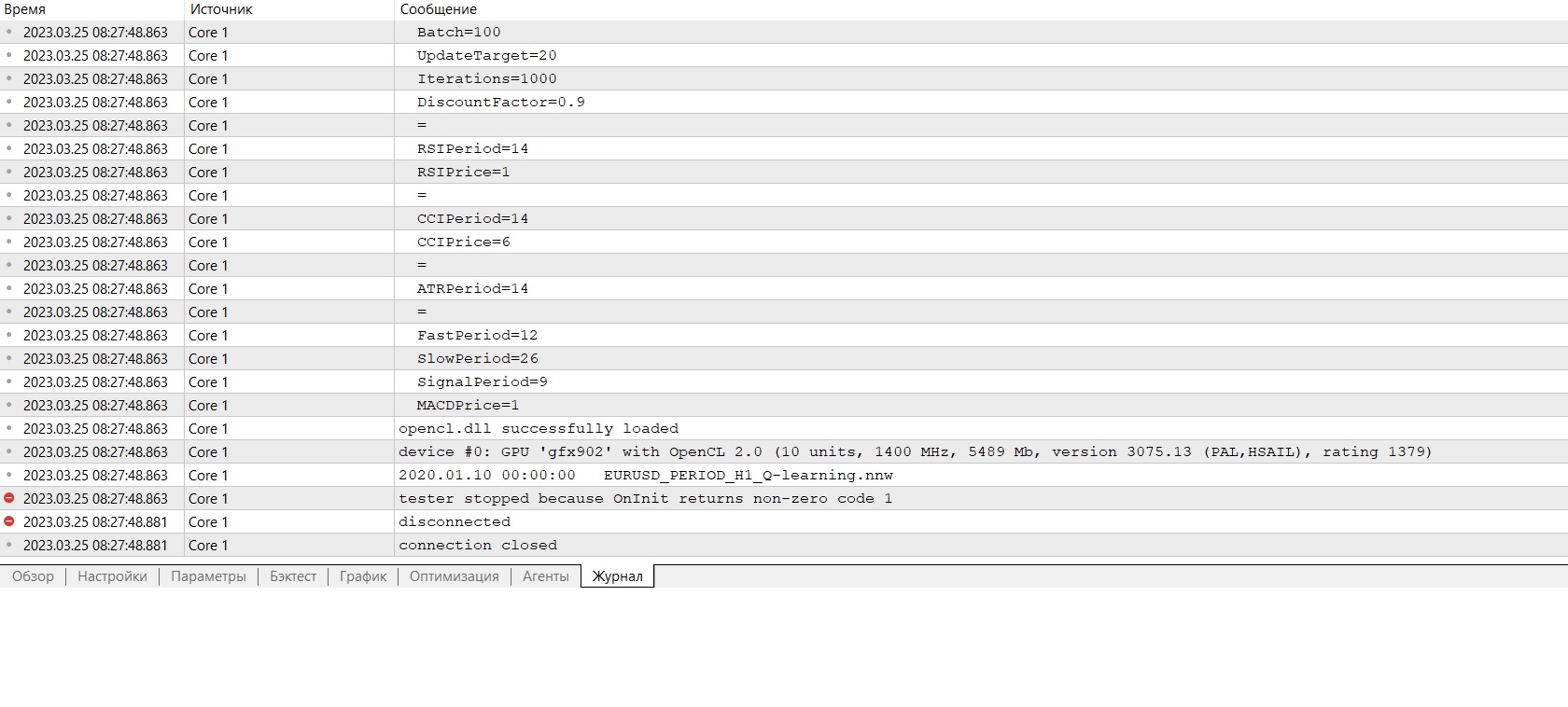
Need advice :) Just joined the terminal after reinstallation, I want to do training and it gives an error
{kind=link}
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Neural networks made easy (Part 28): Policy gradient algorithm has been published:
We continue to study reinforcement learning methods. In the previous article, we got acquainted with the Deep Q-Learning method. In this method, the model is trained to predict the upcoming reward depending on the action taken in a particular situation. Then, an action is performed in accordance with the policy and the expected reward. But it is not always possible to approximate the Q-function. Sometimes its approximation does not generate the desired result. In such cases, approximation methods are applied not to utility functions, but to a direct policy (strategy) of actions. One of such methods is Policy Gradient.
The first tested model was DQN. And it shows an unexpected surprise. The model generated a profit. But it executed only one trading operation, which was open throughout the test. The symbol chart with the executed deal is shown below.
By evaluating the deal on the symbol chart, you can see that the model clearly identified the global trend and opened a deal in its direction. The deal is profitable, but the question is whether the model will be able to close such a deal in time? In fact, we trained the model using historical data for the last 2 years. For all the 2 years, the market has been dominated by a bearish trend for the analyzed instrument. That is why we wonder if the model can close the deal in time.
When using the greedy strategy, the policy gradient model gives similar results. Remember, when we started studying reinforcement learning methods, I repeatedly emphasized the importance of the right choice of reward policy. So, I decided to experiment with the reward policy. In particular, in order to exclude too long holding of losing position, I decided to increase the penalties for unprofitable positions. For this, I additionally trained the policy gradient model using the new reward policy. After some experiments with the model hyperparameters, I managed to achieve 60% profitable operations. The testing graph is shown below.
The average position holding time is 1 hour 40 minutes.
Author: Dmitriy Gizlyk