计量经济学:书目
以下是关于 "回归分析的基本原理 "的参考资料。
Davidson,Russell and James G.MacKinnon(1993)。计量经济学 中的估计和推理,牛津: 牛津大学出版社。
Greene, William H.(2008). 计量经济学分析,第六版,新泽西州上萨德河:Prentice-Hall。
Johnston, Jack和John Enrico DiNardo (1997)。 计量经济学方法》,第四版,纽约:麦格劳-希尔。
Pindyck, Robert S. and Daniel L. Rubinfeld (1998). 计量经济学模型和经济预测,第四版, 纽约:麦格劳-希尔。
Wooldridge, Jeffrey M.(2000). 计量经济学入门:一种现代方法。 辛辛那提,俄亥俄州:西南大学出版社。
让我给你举一个回归的例子,它不过是一个取决于其参数(自变量,回归者)的函数(因变量)。在计算回归时,有几个步骤需要遵循。
1.需要写下一个方程式。
我采取了被热捧的MA,但是加权,所以对我来说很宽容,用前5个柱子(滞后值)来计算。我把公式写成了这样的形式。
eurusd = c(1)*eurusd(-1) + c(2)*eurusd(-2) + c(3)*eurusd(-3) + c(4)*eurusd(-4) + c(5) *eurusd(-5)
2.估计
有必要估计这个方程的系数c(i),以便我们的MA的曲线尽可能好地对应于最初的EURUSD_H1年系列。我们得到未知系数的评估结果。
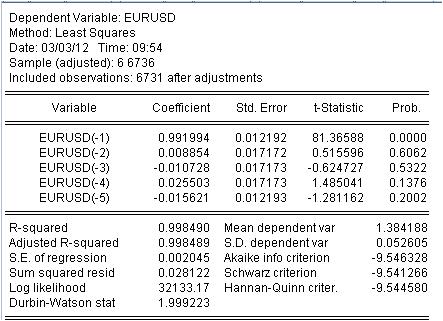
我们已经得到了我们的加权MA的值。我们有了这个等式。
eurusd = 0.991993934254*eurusd(-1) + 0.00885362355538*eurusd(-2) - 0.0107282369642*eurusd(-3) + 0.0255027160774*eurusd(-4) - 0.0156205779585*eurusd(-5)
3.结果。
我们看到了什么结果?
3.1 首先是马赫方程本身。我想注意一点细微的差别。当我们计算一个简单的掩码计算平均值时,由于某种原因,我们没有在区间的中间记录,而是在区间的末端记录。回归是用来根据以前的值来计算最新的值。
3.2 事实证明,比率不是常数,而是有其自身偏差的随机变量。
3.3.最后一栏说,给定的系数有一个非零的概率,根本就是零。
4.与方程一起工作
让我们来看看我们的加权混合物。

马什卡已经把小木箱盖得严严实实,看不出来了,但小木箱和马什卡之间仍有差异。以下是这些差异的统计数据

我们看到从-137点到215点的巨大散点。虽然标准偏差=20分。
结论。
我们收到了一个质量异常高的面具,具有已知的统计特征,使用回归。
最后一个。优素福!不要在电车下,不要再让观众在一条线上笑。
准备讨论回归主题的文献和应用。
3.结果。
我们看到了什么结果?
3.1 首先是马赫方程本身。我想在这里指出一个微妙的问题。当我们通过获取平均值来计算一个简单的掩码时,由于某些原因,我们没有把这个平均值放在区间的中间,而是放在区间的末端。回归是用来根据以前的值来计算最新的值。
3.2 事实证明,比率不是常数,而是随机变量
3.3 最后一栏说,给定的系数有一个非零的概率是零。
1.对不起,在伤口上多撒了点盐--反正原始系列是不稳定的。
2)这个概率几乎总是不为零。
3.你是否检查过多重共线性?IMHO如果你消除了多重共线性,就只剩下一个变量了。你确定了重要的因素吗?
4.对于5个变量,你有多少个观察值?
你怎么这么有文化?
1.对不起,在伤口上多撒了点盐--反正原始系列是不稳定的。
当然,我们对其他的人不感兴趣。
2.该概率几乎总是不为零。
并非如此。如果非零,则是一个函数形式错误。
3.你是否检查过多重共线性?IMHO如果你消除了多重共线性,就只剩下一个变量了。你确定了重要的因素吗?
什么是 "重要因素 "我不明白,但请看一下相关系数。
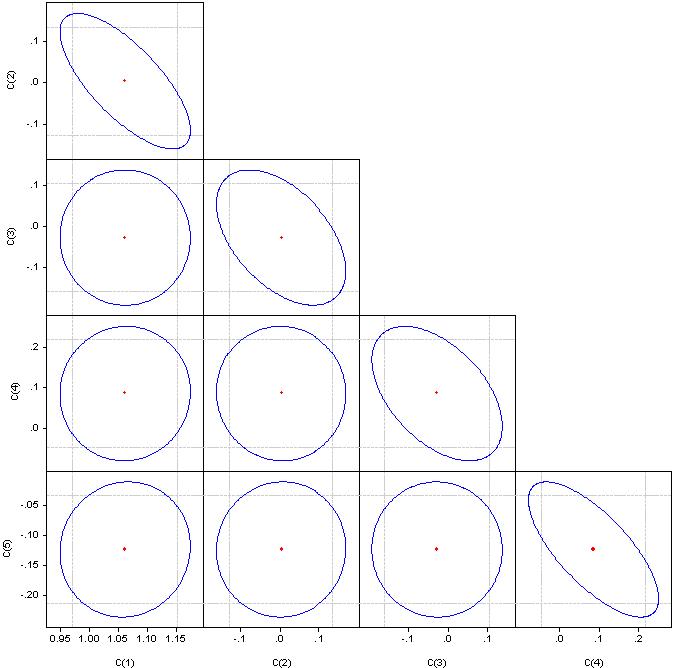
如果它是一个圆圈,相关度为零。如果合并成一条直线,相应的一对系数之间的相关性是100%。
4.对于5个变量,你有多少个观察值?
6736次观察
任何回归模型 的第一步都是因素选择。如果你不应用逐步回归(有夹杂或例外),那么你必须手动选择它们。
多重共线性--模型中包含的 因素变量之间存在密切的依赖性。不是系数的关联性,而是因素的关联性。
多重共线性的存在导致了。
- 歪曲了 , 模型的参数值, , 倾向于高估 。
- 正常方程系统的弱调理。
- 复杂的 ,确定 最重要的 因素 特征 的过程 。
多重共线性的一个指标是成对的相关系数超过0.8的值。 这里的因素显然有很强的相关性。为了消除它,我们需要去除多余的因素。无论是手动还是逐步回归。
在软件包中查找--阶跃回归或岭回归。
而6736/4是太多的观察。我们需要谷歌--我不记得如何根据因素的数量来确定最佳的观察数量。
请参加我的计量经济学主题。
这里有一个实际的例子。
让我们构建一个周期为5的音阶的类似物,但条形系数应该在3阶的多项式上。
在EViews中,对于欧元兑美元,其写法如下
eurusd pdl(eurusd(-1), 5,3)
以一种更熟悉的形式。
eurusd = + c(5)*eurusd(-1) + c(6)*eurusd(-2) + c(7)*eurusd(-3) + c(8)*eurusd(-4) + c(9)*eurusd(-5) + c(10)*eurusd(-6)
我们通过OLS估计系数,得到系数估计的结果。
eurusd = + 0.934972661616*eurusd(-1) + 0.139869148138*eurusd(-2) - 0.093599954464*eurusd(-3) - 0.0264992987207*eurusd(-4) + 0.0801064628352*eurusd(-5) - 0.0348473223286*eurusd(-6)
关于方程估计的统计数据如下。
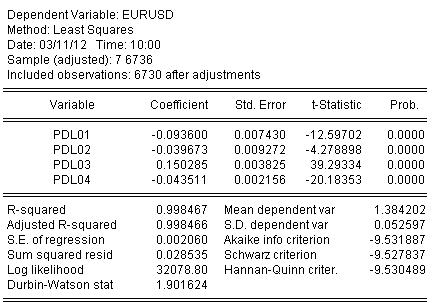
从统计数据中我们可以看到,我们从阿尔蒙的挥舞中看到了一个非常好的原始科蒂尔的映射水平 R-square = 0.998467
从图形上看,它看起来像。

退步(阿尔蒙的挥手)已经完全覆盖了原来的商数。
还有最后一勺蜂蜜。
让我们看看残留物是什么,即我们的阿尔蒙的麦芽汁和原来的科蒂尔之间的差异。这个残差的静止性/非静止性是非常重要的。

单位根检验表明,残差是静止的。
如果你在谷歌上搜索"计量经济学"一词,你会得到一个巨大的文献清单,即使是专家也很难理解。一本书说一套,另一套--另一套,第三套--只是前两套的汇编,有一些不准确之处。但 "从书本中来 "的方法结合了这些书本在实践中的应用并不明确。我对知识分子沦为书呆子的胡闹不感兴趣。
与本论坛的其他书单类似,例如关于统计学的书单,我建议我们集体编制一份参与者认为与经济数据的测量--计量经济学有关的教科书、专著、论文、文章、互联网资源和软件包的清单。然而,我们不要忘记,数理统计是计量经济学的姊妹篇。我建议不要把 与技术分析有关的东西列入这个名单。
为了排除滑向植物学的情况,我提出了一个具体的书单方法。只有当我知道有软件可以实现这些书中的算法时,我们才会发布链接(书籍本身)。我已将范围缩小到EViews。这个程序与其他程序相比没有任何优势,它有优点也有缺点,但我把它作为计量经济学的一个标尺。我附上了用户手册第二卷的目录,以便一下子概括出尽可能广泛的问题。由于建议的方法,计量经济学中使用的几个领域,但不包括在EVIEWS中,如NS,小波等,被排除在外。当然,我们也欢迎对此类项目和书籍的参考。
如果我们不仅能提供算法来源的链接,还能进行具体的计算,那么这个话题就没有任何价值了。
我建议使用附件中的章节编号进行图书分组。
因此,请支持。