Artículos sobre programación y uso de robots comerciales en el lenguaje MQL5
Los Asesores Expertos creados para la plataforma MetaTrader ejecutan una gran variedad de funciones ideadas por sus desarrolladores. Los robots comerciales son capaces de realizar el seguimiento de los instrumentos financieros 24 horas al día, copiar las operaciones, confeccionar y enviar los informes, analizar las noticias, e incluso facilitar al operador una interfaz gráfica personalizada desarrollada por encargo.
Los artículos contienen las técnicas de programación, ideas matemáticas para el procesamiento de datos, consejos para la creación y el encargo de robots comerciales.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Redes neuronales: así de sencillo (Parte 41): Modelos jerárquicos
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.

Aprendiendo a diseñar un sistema de trading con el oscilador Chaikin
Aquí tenemos un nuevo artículo de nuestra serie destinada al estudio de indicadores técnicos populares y la creación de sistemas comerciales basados en ellos. En este artículo, trabajaremos con el indicador Chaikin Oscillator, el oscilador de Chaikin.

Desarrollo de un sistema de repetición (Parte 31): Proyecto Expert Advisor — Clase C_Mouse (V)
Desarrollar una manera de poner un cronómetro, de modo que durante una repetición/simulación, éste pueda decirnos cuánto tiempo falta, puede parecer a primera vista una tarea simple y de rápida solución. Muchos simplemente intentarían adaptar y usar el mismo sistema que se utiliza cuando tenemos el servidor comercial a nuestro lado. Pero aquí reside un punto que muchos quizás no consideran al pensar en tal solución. Cuando estás haciendo una repetición, y esto para no hablar del hecho de la simulación, el reloj no funciona de la misma manera. Este tipo de cosa hace complejo construir tal sistema.

Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer-DT)
Continuamos nuestro análisis de los métodos de aprendizaje por refuerzo. Y en el presente artículo, presentaremos un algoritmo ligeramente distinto que considera la política del Agente en un paradigma de construcción de secuencias de acciones.

Experimentos con redes neuronales (Parte 5): Normalización de parámetros de entrada para su transmisión a una red neuronal
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.
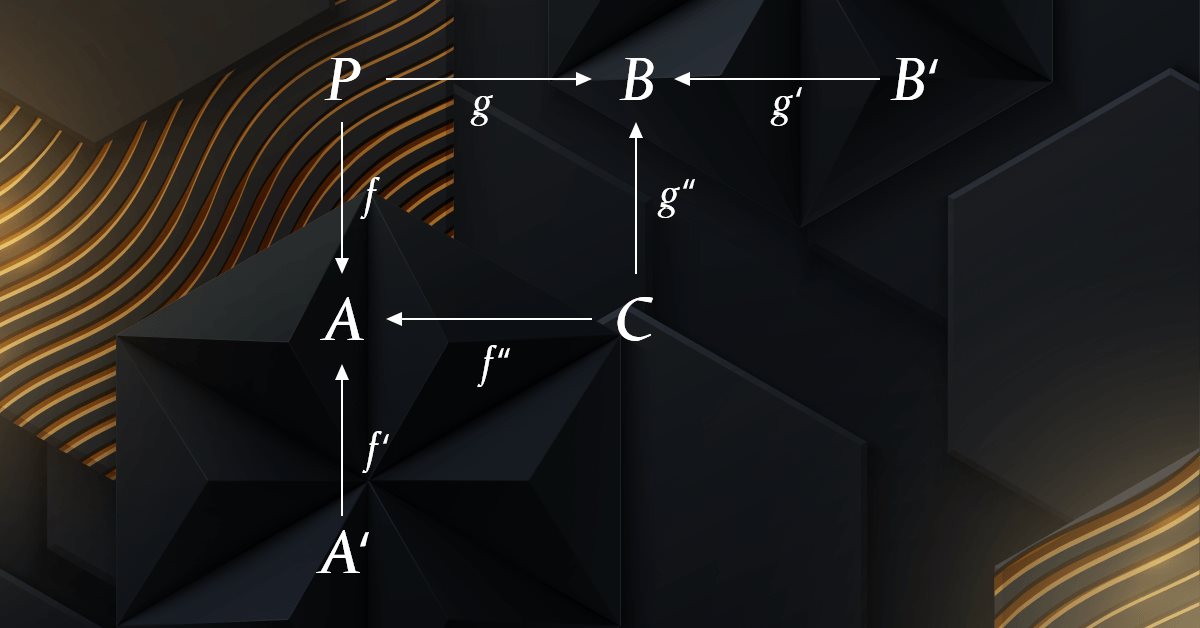
Teoría de categorías en MQL5 (Parte 4): Intervalos, experimentos y composiciones
La teoría de categorías es una rama de las matemáticas diversa y en expansión, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo describir algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.

Redes neuronales: así de sencillo (Parte 52): Exploración con optimismo y corrección de la distribución
A medida que el modelo se entrena con el búfer de reproducción de experiencias, la política actual del Actor se aleja cada vez más de los ejemplos almacenados, lo cual reduce la eficacia del entrenamiento del modelo en general. En este artículo, analizaremos un algoritmo para mejorar la eficiencia del uso de las muestras en los algoritmos de aprendizaje por refuerzo.

Redes neuronales: así de sencillo (Parte 61): El problema del optimismo en el aprendizaje por refuerzo offline
Durante el aprendizaje offline, optimizamos la política del Agente usando los datos de la muestra de entrenamiento. La estrategia resultante proporciona al Agente confianza en sus acciones. No obstante, dicho optimismo no siempre está justificado y puede acarrear mayores riesgos durante el funcionamiento del modelo. Hoy veremos un método para reducir estos riesgos.

Desarrollando un EA comercial desde cero (Parte 14): Volume at Price (II)
Hoy añadiremos varios recursos a nuestro EA. Este artículo les resultará bastante interesante y puede orientarlos hacia nuevas ideas y métodos para presentar la información y, al mismo tiempo, corregir pequeños fallos en sus proyectos.

Redes neuronales: así de sencillo (Parte 37): Atención dispersa (Sparse Attention)
En el artículo anterior, analizamos los modelos relacionales que utilizan mecanismos de atención en su arquitectura. Una de las características de dichos modelos es su mayor uso de recursos informáticos. Este artículo propondrá uno de los posibles mecanismos para reducir el número de operaciones computacionales dentro del bloque Self-Attention o de auto-atención, lo cual aumentará el rendimiento del modelo en su conjunto.

Redes neuronales: así de sencillo (Parte 51): Actor-crítico conductual (BAC)
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.

Redes neuronales: así de sencillo (Parte 42): Procrastinación del modelo, causas y métodos de solución
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.

Marcado de datos en el análisis de series temporales (Parte 3): Ejemplo de uso del marcado de datos
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.

Validación cruzada y fundamentos de la inferencia causal en modelos CatBoost, exportación a formato ONNX
En este artículo veremos un método de autor para crear bots utilizando el aprendizaje automático.

Características del Wizard MQL5 que debe conocer (Parte 6): Transformada de Fourier
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.
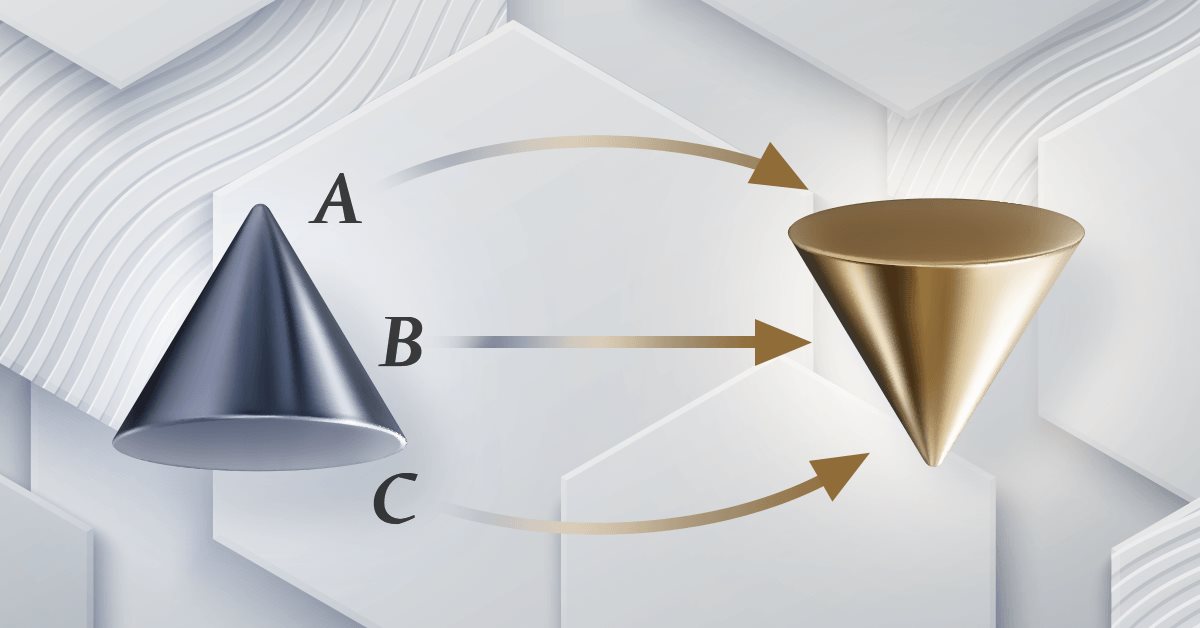
Teoría de categorías en MQL5 (Parte 22): Una mirada distinta a las medias móviles
En el presente artículo intentaremos simplificar los conceptos tratados en esta serie centrándonos en solo un indicador, el más común y probablemente el más fácil de entender: la media móvil. También veremos el significado y las posibles aplicaciones de las transformaciones naturales verticales.
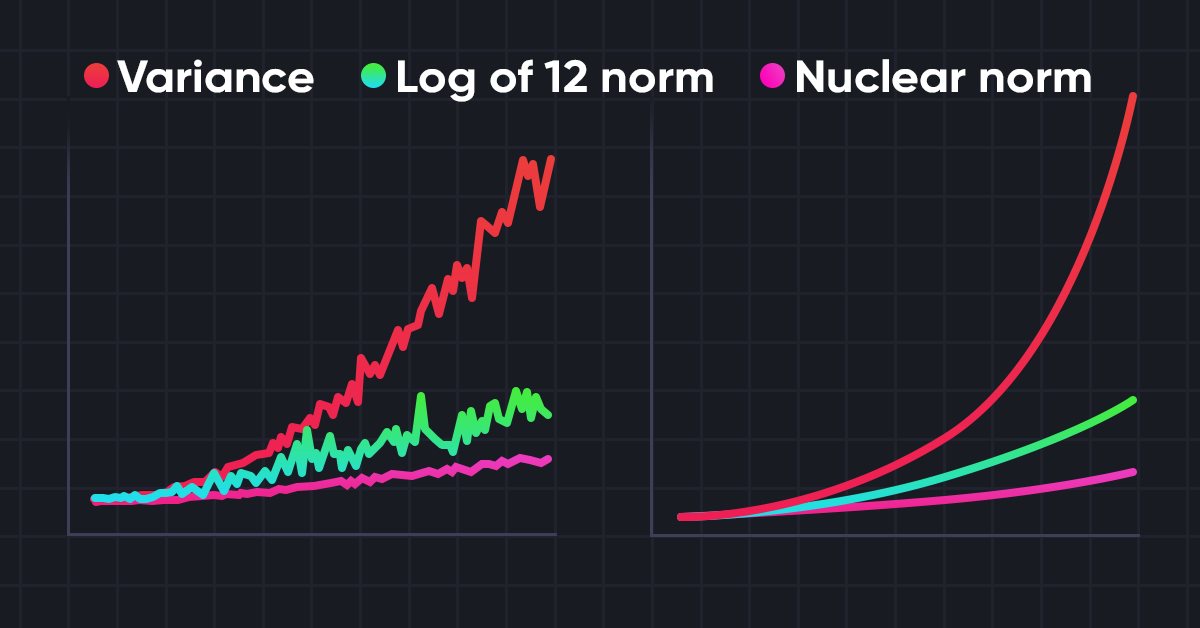
Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.

Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer (ODT)
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. En el artículo de hoy, analizaremos otro algoritmo para optimizar este método.

Teoría de Categorías en MQL5 (Parte 17): Funtores y monoides
Este es el último artículo de la serie sobre funtores. En él, revisaremos los monoides como categoría. Los monoides, que ya hemos introducido en esta serie, se utilizan aquí para ayudar a dimensionar la posición junto con los perceptrones multicapa.

Redes neuronales: así de sencillo (Parte 64): Método de clonación conductual ponderada conservadora (CWBC)
Como resultado de las pruebas realizadas en artículos anteriores, hemos concluido que la optimalidad de la estrategia entrenada depende en gran medida de la muestra de entrenamiento utilizada. En este artículo, nos familiarizaremos con un método bastante sencillo y eficaz para seleccionar trayectorias para el entrenamiento de modelos.

Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.

Características del Wizard MQL5 que debe conocer (Parte 02): Mapas de Kohonen
Gracias al Wizard, el tráder podrá ahorrar tiempo a la hora de poner en práctica sus ideas. Asimismo, podrá reducir la probabilidad de que surjan errores por duplicación de código. En lugar de perder el tiempo con el código, los tráders tendrán la posibilidad de poner en práctica su filosofía comercial.

Python, ONNX y MetaTrader 5: Creamos un modelo RandomForest con preprocesamiento de datos RobustScaler y PolynomialFeatures
En este artículo, crearemos un modelo de bosque aleatorio en Python, entrenaremos el modelo y lo guardaremos como un pipeline ONNX con preprocesamiento de datos. Además, usaremos el modelo en el terminal MetaTrader 5.

Desarrollo de un sistema de repetición (Parte 30): Proyecto Expert Advisor — Clase C_Mouse (IV)
Aquí te mostraré una técnica que puede ayudarte mucho en varios momentos de tu vida como programador. En contra de lo que muchos dicen, lo limitado no es la plataforma, sino los conocimientos del individuo que lo dice. Lo que se explicará aquí es que con un poco de sentido común y creatividad, se puede hacer que la plataforma MetaTrader 5 sea mucho más interesante y versátil, sin tener que crear programas locos ni nada por el estilo puedes crear un código sencillo, pero seguro y fiable. Utiliza tu ingenio para domar el código con el fin de modificar algo que ya existe, sin eliminar ni añadir una sola línea al código original.

Redes neuronales: así de sencillo (Parte 40): Enfoques para utilizar Go-Explore con una gran cantidad de datos
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.

Marcado de datos en el análisis de series temporales (Parte 2): Creando conjuntos de datos con marcadores de tendencias utilizando Python
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.
Paradigmas de programación (Parte 1): Enfoque procedimental para el desarrollo de un asesor basado en la dinámica de precios
Conozca los paradigmas de programación y su aplicación en el código MQL5. En este artículo, analizaremos las características de la programación procedimental y ofreceremos ejemplos prácticos. Asimismo, aprenderemos a desarrollar un asesor basado en la acción del precio (Action Price) utilizando el indicador EMA y datos de velas. Además, el artículo introduce el paradigma de la programación funcional.

Características del Wizard MQL5 que debe conocer (Parte 07): Dendrogramas
La clasificación de datos para el análisis y la predicción es un área muy diversa del aprendizaje automático con un gran número de enfoques y métodos. En este artículo analizaremos uno de estos enfoques, a saber, la Clasificación Jerárquica Aglomerativa (Agglomerative Hierarchical Classification).

Añadimos un LLM personalizado a un robot comercial (Parte 2): Ejemplo de despliegue del entorno
Los modelos lingüísticos (LLM) son una parte importante de la inteligencia artificial que evoluciona rápidamente, por lo que debemos plantearnos cómo integrar unos LLM potentes en nuestro comercio algorítmico. A la mayoría de la gente le resulta difícil adaptar estos modelos a sus necesidades, implantarlos de forma local y luego aplicarlos al trading algorítmico. En esta serie de artículos abordaremos un enfoque paso a paso para lograr este objetivo.

Redes neuronales: así de sencillo (Parte 66): Problemática de la exploración en el entrenamiento offline
El entrenamiento offline del modelo se realiza sobre los datos de una muestra de entrenamiento previamente preparada. Esto nos ofrecerá una serie de ventajas, pero la información sobre el entorno estará muy comprimida con respecto al tamaño de la muestra de entrenamiento, lo que, a su vez, limitará el alcance del estudio. En este artículo, querríamos familiarizarnos con un método que permite llenar la muestra de entrenamiento con los datos más diversos posibles.

Desarrollo de un sistema de repetición (Parte 29): Proyecto Expert Advisor — Clase C_Mouse (III)
Ahora que hemos mejorado la clase C_Mouse, podemos concentrarnos en crear una clase destinada a establecer una base totalmente nueva de estudios. Como mencioné al inicio del artículo, no utilizaremos herencia o polimorfismo para crear esta nueva clase. En cambio, vamos a modificar, o mejor, agregar nuevos objetos a la línea de precio. Esto es lo que haremos en este primer momento, y en el próximo artículo, mostraré cómo cambiar los estudios. Pero, realizaremos esto sin cambiar el código de la clase C_Mouse. Reconozco que, en la práctica, esto sería más fácilmente logrado mediante herencia o polimorfismo. No obstante, existen otras técnicas para alcanzar el mismo resultado.
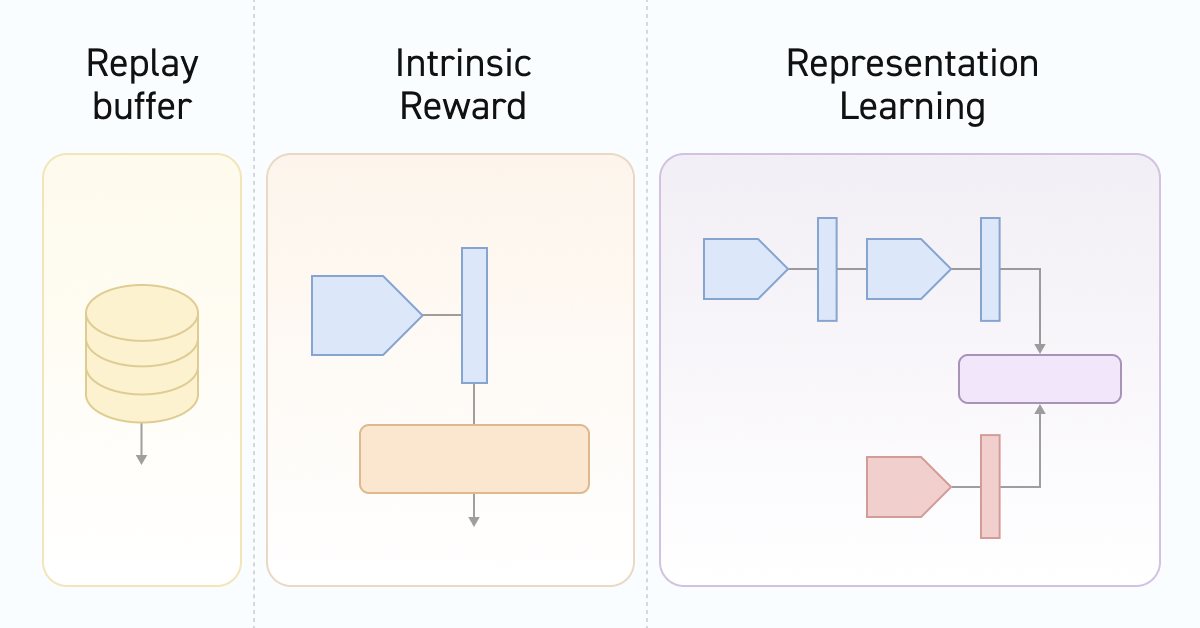
Redes neuronales: así de sencillo (Parte 55): Control interno contrastado (CIC)
El aprendizaje contrastivo (Contrastive learning) supone un método de aprendizaje de representación no supervisado. Su objetivo consiste en entrenar un modelo para que destaque las similitudes y diferencias entre los conjuntos de datos. En este artículo, hablaremos del uso de enfoques de aprendizaje contrastivo para investigar las distintas habilidades del Actor.

Teoría de categorías en MQL5 (Parte 20): Autoatención y transformador
Hoy nos apartaremos un poco de nuestros temas habituales y veremos parte del algoritmo de ChatGPT. ¿Tiene alguna similitud o concepto tomado de las transformaciones naturales? Intentaremos responder estas y otras preguntas usando nuestro código en formato de clase de señal.
Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 5): Bandas de Bollinger en el Canal de Keltner - Señales de Indicador
En este artículo, entenderemos por asesor multidivisa un asesor o robot comercial que puede comerciar (abrir/cerrar órdenes, gestionar órdenes, por ejemplo, trailing-stop y trailing-profit, etc.) con más de un par de símbolos de un gráfico. En este artículo, usaremos las señales de dos indicadores, las Bandas de Bollinger® y el Canal de Keltner.

Marcado de datos en el análisis de series temporales (Parte 1):Creamos un conjunto de datos con marcadores de tendencia utilizando el gráfico de un asesor
En esta serie de artículos, presentaremos varias técnicas de etiquetado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El etiquetado específico de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorar la precisión del modelo e incluso ayudarle a dar un salto cualitativo.

Redes neuronales: así de sencillo (Parte 63): Entrenamiento previo del Transformador de decisiones no supervisado (PDT)
Continuamos nuestra análisis de la familia de métodos del Transformador de decisiones. En artículos anteriores ya hemos observado que entrenar el transformador subyacente en la arquitectura de estos métodos supone todo un reto y requiere una gran cantidad de datos de entrenamiento marcados. En este artículo, analizaremos un algoritmo para utilizar trayectorias no marcadas para el entrenamiento previo de modelos.
Indicadores alternativos de riesgo y rentabilidad en MQL5
En este artículo, presentaremos una aplicación de varias medidas de rentabilidad y riesgo consideradas alternativas al ratio de Sharpe e investigaremos diferentes curvas de capital hipotéticas para analizar sus características.

Escribimos el primer modelo de caja de cristal (Glass Box) en Python y MQL5
Los modelos de aprendizaje automático son difíciles de interpretar, y entender por qué los modelos no se ajustan a nuestras expectativas puede ayudarnos mucho a conseguir, en última instancia, el resultado deseado al utilizar técnicas tan avanzadas. Sin un conocimiento exhaustivo del funcionamiento interno del modelo, podría resultar difícil encontrar fallos que degraden el rendimiento. De este modo, podremos dedicar tiempo a crear funciones que no afecten a la calidad de la previsión. La conclusión es que, por muy bueno que sea un modelo, nos perderemos todas sus grandes ventajas por culpa de nuestros propios errores. Afortunadamente, existe una solución sofisticada y bien diseñada que permite ver con claridad lo que sucede bajo el capó del modelo.
Preparación de indicadores de símbolo/periodo múltiple
En este artículo analizaremos los principios de la creación de los indicadores de símbolo/periodo múltiple y la obtención de datos de ellos en asesores e indicadores. Asimismo, veremos los principales matices de uso de los indicadores múltiples en asesores e indicadores, y su representación a través de los búferes del indicador personalizado.

Añadimos un LLM personalizado a un robot comercial (Parte 1): Desplegando el equipo y el entorno
Los modelos lingüísticos (LLM) son una parte importante de la inteligencia artificial que evoluciona rápidamente, por lo que debemos plantearnos cómo integrar unos LLM potentes en nuestro comercio algorítmico. A la mayoría de la gente le resulta difícil personalizar estos potentes modelos para adaptarlos a sus necesidades, implantarlos de forma local y luego aplicarlos al trading algorítmico. En esta serie de artículos abordaremos un enfoque paso a paso para lograr este objetivo.