Teoría de categorías en MQL5 (Parte 4): Intervalos, experimentos y composiciones
Introducción
En el artículo anterior vimos cómo la teoría de categorías puede resultar eficaz en sistemas complejos gracias a los conceptos de producto, coproducto y propiedad universal. También ofrecimos ejemplos de su aplicación en las finanzas y el trading algorítmico. En este artículo veremos los conceptos de intervalo (span), experimento (experiment) y composición (composition). Veremos cómo dichos conceptos ofrecen una forma más sutil y flexible de razonar sobre los sistemas y cómo pueden utilizarse para desarrollar estrategias comerciales más sofisticadas. Comprendiendo la estructura básica de los mercados financieros desde el punto de vista de la teoría de categorías, los tráders pueden observar con nuevos ojos el comportamiento de los instrumentos financieros, construir portafolios más sofisticados y desarrollar estrategias de gestión de riesgos más eficaces. En general, la aplicación de la teoría de categorías a las finanzas puede mejorar nuestra comprensión de los mercados financieros y permitir a los tráders tomar decisiones más fundamentadas.
Intervalos, experimentos y composiciones
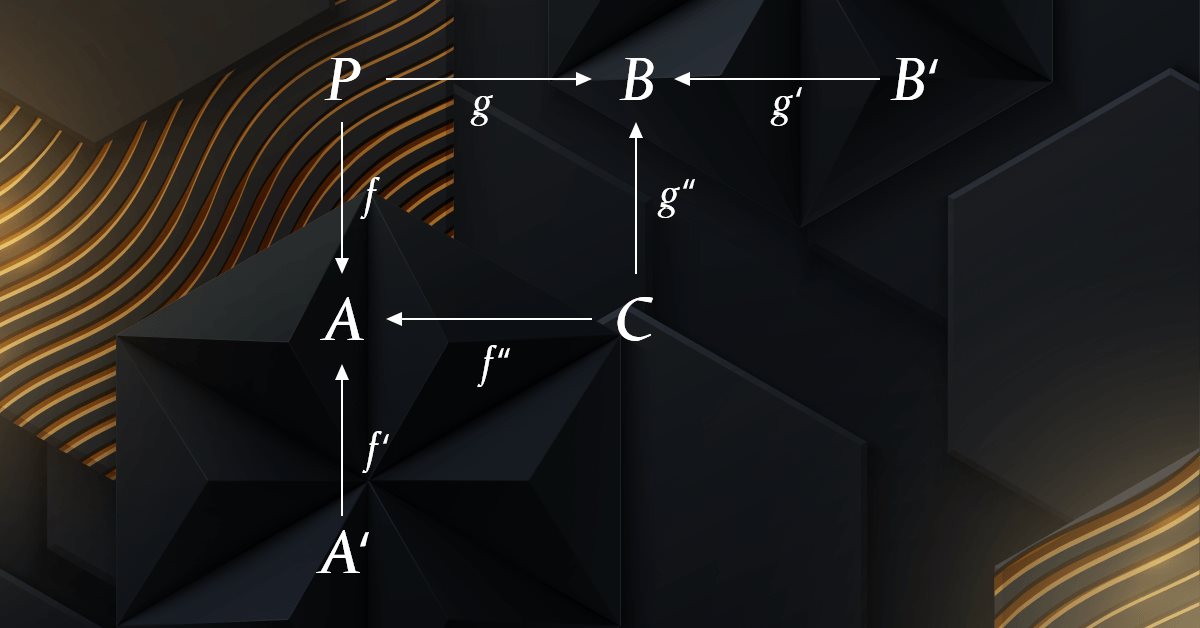
En teoría de categorías, un intervalo (span) es una construcción que une tres objetos y dos morfismos entre ellos. En particular, el intervalo es un diagrama del tipo:
Es un diagrama muy sencillo que también puede presentarse en una línea:
A<--- f --- P --- g --->B
donde A, B y P son los dominios de la categoría y f: P en A y g: P en B son morfismos en la categoría. Morfismos f: P en A y g: P en B se denominan tramos del intervalo.
El intervalo, P, puede verse como una forma de enlazar dos rutas o perspectivas diferentes entre A y B, una a través de f y la otra a través de g. Los lados f y g unen estas rutas en los puntos A y B respectivamente y permiten comparar y combinar las dos rutas.
Antes de profundizar en una posible aplicación en MQL5, echemos un vistazo a la teoría.
Los intervalos son importantes en la teoría de categorías porque permiten comparar dos morfismos de una categoría. Para dos morfismos f: A → B y g: A → C, el intervalo entre B y C es un diagrama del tipo B ← A → C, donde las dos flechas representan los morfismos f y g. Los intervalos se usan a menudo para definir los límites y colímites en la teoría de categorías. Por ejemplo, el límite de un diagrama en una categoría puede definirse como un cono universal sobre ese diagrama, donde el cono es el intervalo entre el objeto límite y cada objeto del diagrama que cumple ciertas condiciones.
Los intervalos también resultan útiles para definir los retrocesos (pullbacks), que son un tipo de límite en el que los objetos implicados están unidos por un par de morfismos. Para dos morfismos f: A → B y g: A → C en una categoría, un retroceso de f y g es un objeto P junto con dos morfismos p1: P → B y p2: P → C tal que f ∘ p1 = g ∘ p2 y P es universal según esta propiedad. Los retrocesos son importantes en muchas áreas de las matemáticas y la ciencia, tales como la geometría algebraica, la topología y la informática.
Otro concepto importante en la teoría de categorías es el experimento, que supone un diagrama formado por dos morfismos paralelos y un tercer morfismo que conecta sus codominios. Podemos ver el experimento como una forma de comparar dos maneras distintas de transformar un objeto en una categoría. Por ejemplo, para dos morfismos f: A → B y g: A → C, un experimento de B a C es un diagrama del tipo A → B⟶ D ← C, donde las flechas denotan los morfismos f, g y h, respectivamente. Los experimentos pueden usarse para definir límites y colímites de forma similar a los intervalos, y también son útiles para definir coecualizadores, que son un tipo de colímite que puede utilizarse para identificar dos morfismos diferentes que compartan el mismo codominio.
Los compuestos (composites) son un concepto fundamental en la teoría de categorías, resultante de la composición de dos o más morfismos. Para dos morfismos f: A → B y g: B → C su composición es un morfismo g∘ f: A → C, que obtenemos aplicando f seguido de g. Los compuestos son asociativos, lo que significa que (h ∘ g) ∘ f = h ∘ (g ∘ f) para tres morfismos cualesquiera f, g y h. Esta propiedad admite la composición de muchos morfismos simultáneamente y se usa para definir la noción de categoría, que es un conjunto de objetos y morfismos que cumplen ciertos axiomas.
A continuación le presentamos diez aplicaciones improvisadas de intervalos, experimentos y compuestos de la teoría de categorías en finanzas y trading:
- Los intervalos puede simular los activos básicos de un instrumento financiero derivado y los instrumentos de cobertura utilizados para reproducir su pago. La propiedad universal del intervalo puede ayudar a determinar el precio del derivado.
- La construcción eficaz de un portafolio de activos compuestos se logra combinando diferentes clases de activos de forma que se minimice el riesgo y se maximice la rentabilidad. En este caso, además, podemos guiarnos por la propiedad universal de composición.
- Los intervalos permiten modelar la dependencia de una institución financiera respecto a diversos factores del mercado. Esto puede lograrse construyendo un intervalo que relacione los activos de la institución con los índices de mercado pertinentes.
- Los experimentos permiten comprobar la eficacia de distintos algoritmos comerciales en diferentes condiciones de mercado. Podemos crear un experimento que imite el comportamiento del mercado y mida el rendimiento del algoritmo con datos simulados.
- Modelar el comportamiento de los sistemas financieros a escala reducida es algo a lo que pueden ayudar las composiciones de dominio. Por ejemplo, podemos observar cómo se correlacionan los diferentes sectores del índice SP500 en distintos ciclos más largos.
- Los intervalos nos permiten simular una réplica de un determinado instrumento financiero usando una combinación de instrumentos más sencillos. Esto resulta útil a la hora de desarrollar nuevos instrumentos financieros con las características que necesitemos, como una menor correlación con los ya existentes.
- Los experimentos nos permiten probar estrategias comerciales comparando la eficacia de una estrategia concreta con un grupo de control. Esto puede lograrse usando repetidamente la propiedad universal de la experimentación.
- Los experimentos también pueden poner a prueba la eficacia de distintos modelos de microestructura del mercado. Esto puede lograrse creando un experimento que simule el comportamiento de distintos tipos de participantes en el mercado y midiendo los resultados finales del mercado.
- Los compuestos pueden modelar la exposición global al riesgo de una entidad financiera. Podemos hacer esto agrupando las diversas actividades de la institución y analizando su interdependencia.
- Los intervalos permiten modelar la relación entre distintas fuentes de datos financieros. Esto nos ayudaría a desarrollar algoritmos de aprendizaje automático capaces de extraer características útiles de fuentes de datos dispares.
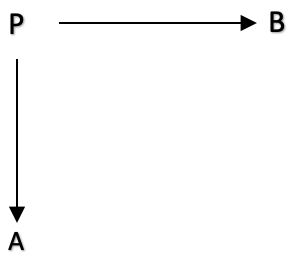
Para ilustrar la aplicación de este concepto, podemos describir el alcance de un "experimento" para ver si existe una relación entre los beneficios generados por una posición comercial larga y un par de variables más, a saber, la media móvil del activo negociado y el rango medio verdadero del activo. Podemos representar este "experimento" como un diagrama que incluya un vértice, dos zonas y los morfismos entre ellas.
Supongamos que tenemos una categoría C que contiene dos dominios, A y B, que representan los dominios de la media móvil y la media del rango verdadero respectivamente. En esta categoría, también tenemos el dominio P, que representa el beneficio de la posición larga y ejerce como nuestro tope.
A continuación podemos definir los dos morfismos de f: P -> A y g: P -> B, que muestran los movimientos de la posición larga de P hacia sus valores observables en los dominios A y B, respectivamente. Estos morfismos suponen el registro de los valores observados.
Dicha representación esquemática nos permite analizar el experimento de una manera más abstracta y formal, y también aplicar los conceptos y herramientas de la teoría de categorías para razonar sobre él.
Para realizar el "experimento", abriremos una orden de 0,1 lotes para comprar el símbolo actual en el gráfico, digamos EURUSD, y luego en cada nueva barra registraremos los actuales valores flotantes, MA y ATR. Partiendo de los datos observados, podemos ver si existen correlaciones entre los mismos. Esto puede usarse para crear el sistema de trailing stop perfecto para posiciones largas. Podrá sustituir fácilmente los indicadores MA y ATR utilizados aquí por otros más adecuados en su propia opinión. Hemos elegido estos indicadores solo como ejemplo.
Si ejecutamos este experimento en EURUSD H1 1 marzo, obtendremos los siguientes datos.
| P: (Valor flotante/Beneficio) | A: ATR | B: MA |
| -6,60000 | 0,00203 | 1,12138 |
| -14,90000 | 0,00181 | 1,12136 |
| -18,80000 | 0,00175 | 1,12140 |
| -24,20000 | 0,00157 | 1,12125 |
| -29,00000 | 0,00146 | 1,12100 |
| -24,30000 | 0,00127 | 1,12078 |
|
|
|
|
Si introducimos correlaciones retardadas entre cada uno de nuestros dos conjuntos de datos del dominio A y B con el beneficio de la posición, esto nos ayudará a establecer si cada uno de estos dominios puede predecir reducciones de la posición. Esta información nos ayudará a fijar o mover un stop loss existente en una posición larga.
Otra forma en la que estos intervalos pueden ayudar a determinar un stop loss podría ser si asumimos que cada uno de los dominios terminales A y B a través de sus respectivos morfismos f y g forman en realidad un coproducto (suma) de lo lejos que debería el llegar el stop loss ideal para posiciones largas. Estos morfismos suponen esencialmente funciones que aceptan datos de entrada y producen datos de salida. En este caso, cada uno de los dominios finales proporcionará su valor indicador como entrada, y cada una de las funciones f y g ofrecerá un valor double de salida.
Sumando estos valores dobles, equivalentes a los coproductos, obtendremos el precio de stop loss ideal. Si suponemos que los resultados del morfismo (precio de stop loss) tienen una dependencia lineal de los parámetros de entrada del indicador de morfismo, entonces se presupondrán las siguientes ecuaciones.
![]()
donde xa ⊆ A, mientras que ma y ca son los coeficientes de inclinación y los puntos de intersección con el eje «y» de la relación lineal. De igual forma, para el dominio B
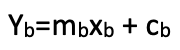
Esta hipótesis se relaciona con la relación lineal entre el delta del stop loss ideal y los valores del indicador. Si esta relación constituyera una curva, las ecuaciones anteriores serían cuadráticas y con más coeficientes y exponentes. Sin embargo, nuestra versión, más simple, puede codificarse como mostramos a continuación.
double _sl=((m_ma.Main(_index)*m_slope_ma)+(m_intercept_ma*m_symbol.Point()))+((m_atr.Main(_index)*m_slope_atr)+(m_intercept_atr*m_symbol.Point()));
Si, utilizando la clase de trailing de asesor incorporada en MQL5, creamos nuestra propia clase de trailing que use nuestro delta de stop loss ideal, a continuación, los coeficientes m y c tanto para el dominio A como para el dominio B podrían ser los de entrada para esta clase de trailing. Las pruebas realizadas durante el último año para EURUSD H1 con nuestra señal en forma de clase signalRSI.mqh incorporada nos han ofrecido el informe y la curva que se muestran a continuación.
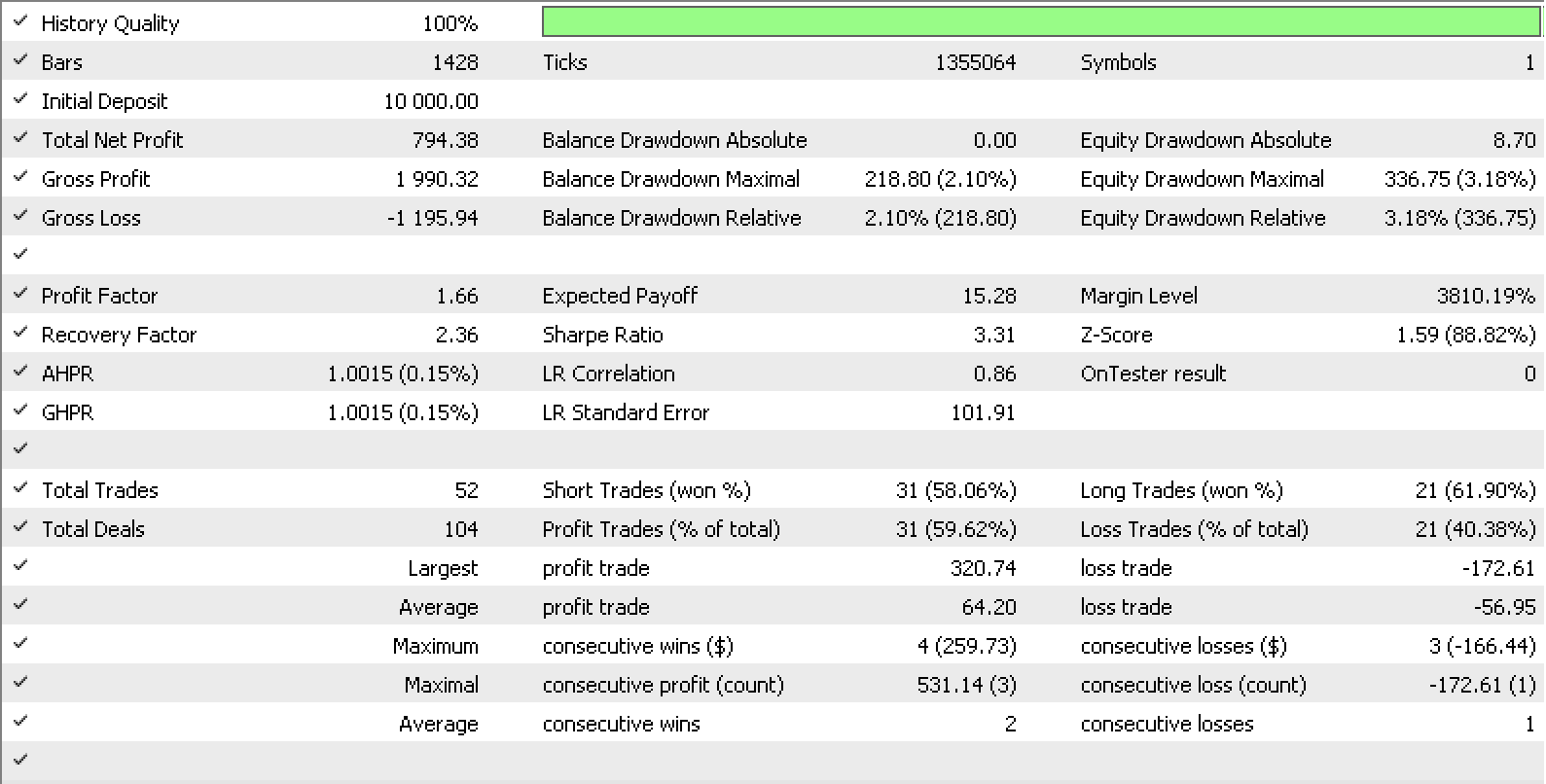

Las ideas presentadas aquí pueden desarrollarse aún más si consideramos intervalos compuestos.
Un intervalo compuesto supone un intervalo de intervalos. En nuestro caso, podríamos argumentar que los valores de nuestros indicadores están ligeramente atrasados. Este ligero retraso podría dar lugar a precios menos precisos para nuestro trailing stop. Para resolver dicho problema, podríamos convertir los dominios A y B en intervalos. A sería el producto de A' y C, y B sería el producto de C y B'.

Los intervalos compuestos asignados a los subdominios A', C y B' pueden ayudarnos a optimizar los morfismos de f: P en A, g: P en B, f': A' en A, f'': C en A, g'' : C a B y g': B' en B para afinar nuestro sistema de trailing stop, ofreciendo una visión más detallada de los datos y de las relaciones entre los valores observados en los dominios A y B.
Al reconstruir A y B, ahora los consideraremos como productos de A' y C para A y de C y B' para B. No olvidemos que P es la suma de A y B, pero serán productos. Ya sabemos que el ATR es el rango medio de precios reales en un periodo determinado, por lo que resulta matemáticamente equivalente al producto entre el valor inverso de la longitud del periodo y la suma de los rangos de precio en esa longitud, lo cual significa que tenemos A' para la longitud inversa del periodo y C para nuestra suma de precios. Y a la inversa, MA equivale al producto del valor inverso del periodo y la suma de los precios recientes. Así que en este caso tendremos la misma ubicación de los productos que en el intervalo A.

El dominio C está etiquetado como precio, y si somos un poco pedantes, esto parece contradictorio en el sentido de que el precio utilizado para ATR (A) es la suma de los valores del rango real durante el periodo, mientras que el valor dado para MA es simplemente la SUMA de los precios de cierre actuales.
Aquí es donde resulta útil la regla no escrita de la teoría de categorías de centrarse en los morfismos entre dominios en lugar de desentrañar lo que se encuentra en el dominio. Porque con él no solo podemos montar fácilmente nuestro diagrama, como se muestra arriba, sino también identificar fácilmente las posibles propiedades universales. Las propiedades universales son las que diferencian nuestro enfoque de otros muchos métodos matemáticos usados habitualmente para la optimización o la búsqueda de valores omitidos.
Por lo que sabemos, el dominio C supone un precio. La forma en que este dominio gestiona los rangos de precios frente a los precios de cierre queda fuera de los límites del presente artículo y, de hecho, no afecta al resultado final en nuestro caso.
No obstante, antes de considerar las propiedades universales aplicables, es útil señalar que, al dividir los datos en estos subdominios, resulta más fácil identificar patrones y correlaciones entre los distintos valores observados, lo cual puede ayudar a optimizar no solo los morfismos f y g, sino también f', f'', g' y g''.
Una vez más, y para abreviar, podemos aceptar que las relaciones entre los dominios terminales añadidos A', C y B' son lineales, lo que significa que los formatos de ecuación anteriores seguirán siendo válidos.
Si ahora realizamos pruebas con más datos de entrada (dado que el número de morfismos se ha triplicado) obtendremos el informe y la curva de prueba que vemos.
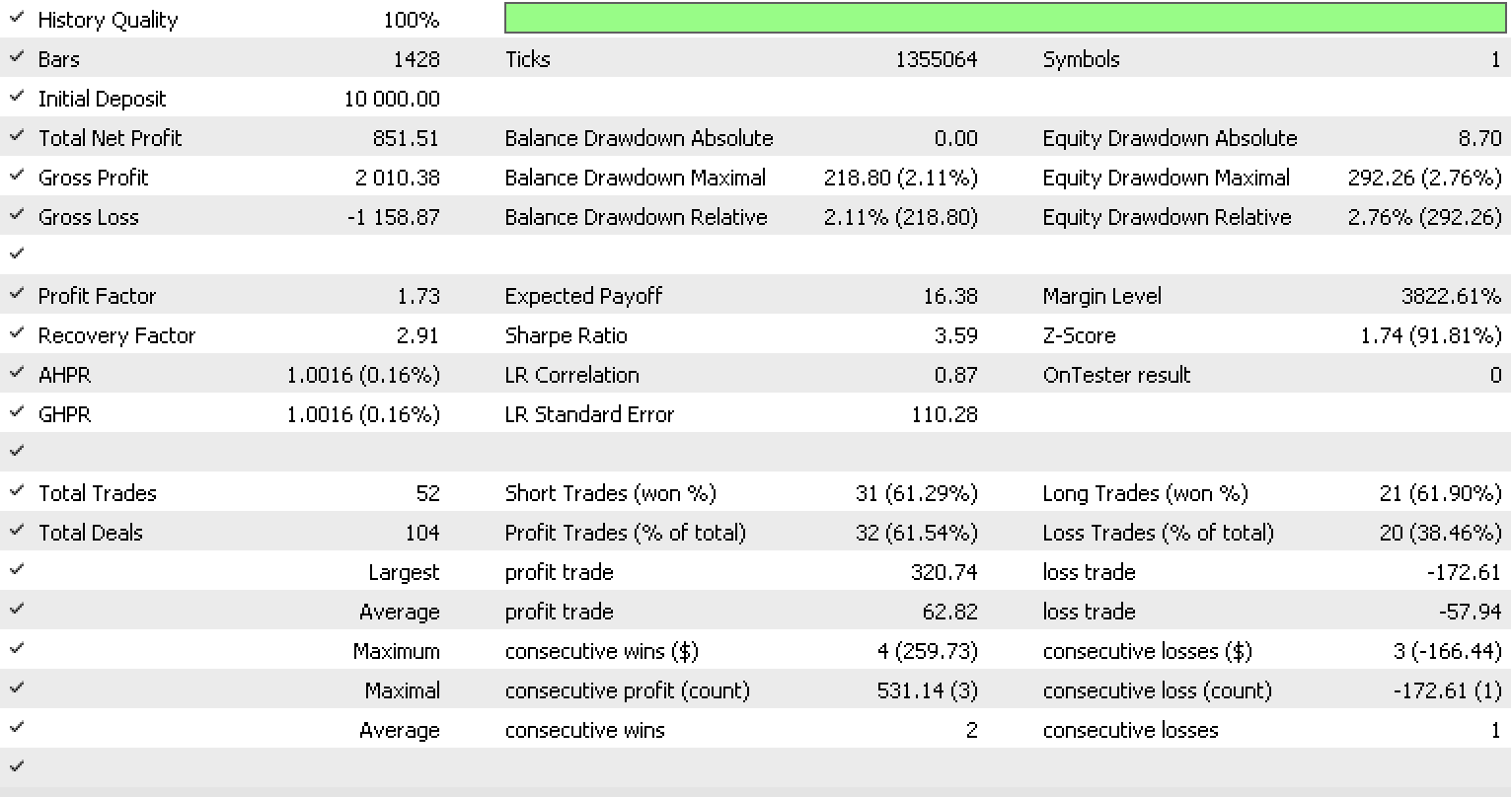

Percibimos una mejora evidente del rendimiento general del sistema de trailing. Sin embargo, esto puede deberse a un exceso de ajuste, ya que el número de parámetros de entrada se ha triplicado en comparación con la prueba de antes.
Volviendo a la noción de propiedad universal, nuestro intervalo compuesto nos ofrece dos candidatos para este concepto. En primer lugar, el morfismo universal entre A' y C está implícito en el intervalo de dominios A, puesto que los dominios A' C son terminales.
Si etiquetamos estos morfismos f''' y g''' para C en A’ y C en B’, respectivamente, presupondremos que existe una relación entre el precio y el periodo elegido para el ATR. De la misma forma, existirá una relación entre el precio y el periodo del indicador MA.
Al igual que sucede con los morfismos anteriores, la relación entre el precio y los periodos del indicador puede ser lineal, lo cual significa que estamos siguiendo el formato de ecuación simple anterior, o puede ser una curva, lo que significa que estamos eligiendo nuestro indicador más alto y adoptaremos una ecuación cuadrática.
Sin embargo, si nos ceñimos a las relaciones lineales y, basándonos en nuestra última versión de la clase final, almacenamos como permanentes las constantes de todos los morfismos (excepto f''' y g''') (sin cambios y utilizando siempre los valores por defecto), podríamos realizar pruebas comparativas durante el mismo periodo y ver cómo se comporta en comparación con nuestras anteriores clases finales.
A continuación le mostramos el resultado de la prueba.


Los resultados no son los mejores de los tres informes, pero el nivel de rendimiento con menos datos de entrada y el uso de los principios de propiedad universal indica que la idea puede probarse durante periodos de tiempo más largos. Como de costumbre, el código publicado aquí no supone ninguna panacea ni un sistema comercial completo, por lo que recomendamos encarecidamente a los lectores investigar por su propia cuenta antes de utilizar cualquier parte del mismo.
Conclusión
En este artículo analizamos cómo pueden usarse los intervalos, los experimentos y las composiciones de la teoría de categorías al desarrollar estrategias comerciales de salida. Los intervalos constituyen las celdas de un par de ideas/preceptos o sistemas, representados aquí como dominios. Este par proporciona experimentos, los cuales suponen una propiedad universal del intervalo. La composición complementa el intervalo con otros intervalos para crear sistemas y métodos más informativos, que en nuestro caso han resultado útiles para establecer una estrategia de salida de un sistema comercial.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12394
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso