
Teoría de categorías en MQL5 (Parte 20): Autoatención y transformador
Introducción
Creo que sería negligente por mi parte continuar con esta serie de artículos sobre teoría de categorías y transformaciones naturales sin tocar ChatGPT. A estas alturas, todo el mundo está familiarizado de una forma u otra con ChatGPT y una amplia variedad de plataformas de inteligencia artificial similares y, con suerte, el lector ya habrá apreciado cómo las redes neuronales basadas en transformadores simplifican nuestra investigación y ahorran tiempo que antes se dedicaba a tareas rutinarias. Por lo tanto, en este artículo me desviaré de mis temas habituales y trataré de responder a la pregunta sobre si las transformaciones naturales de la teoría de categorías son de alguna manera clave para los algoritmos de los transformadores generativos preentrenados (Generative Pretrained Transformer, GPT) utilizados por OpenAI.
Además de buscar sinónimos para el concepto de “transformación”, creo que también sería interesante observar los elementos del código del algoritmo GPT en MQL5 y probarlos en la clasificación preliminar de una serie de precios para los mercados con instrumentos financieros.
El transformador presentado en el artículo "Todo lo que necesita es atención" (versión en ruso) supuso una innovación en las redes neuronales utilizadas para traducir el lenguaje hablado (por ejemplo, del italiano al francés). Proporcionó una manera de deshacerse de la recurrencia (recurrence) y las convoluciones (convolutions) ¿Cómo? Usando autoatención (Self-Attention). Muchas plataformas de inteligencia artificial actuales suponen desarrollos de las ideas contenidas en el artículo.
El algoritmo real utilizado por OpenAI es, por supuesto, un secreto, pero aun así se cree que utiliza representación vectorial de palabras, codificación posicional (positional encoding), autoatención y redes neuronales de conexión directa como parte de la pila del transformador de descodificación (decode-only transformer). Nada de esto ha sido confirmado, así que no confíen en mi palabra. Para ser claros, todo esto se refiere a la parte de la traducción de palabra/idioma del algoritmo. De hecho, como la mayoría de los datos de entrada a ChatGPT son texto, juega un papel clave en el algoritmo, pero ChatGPT puede hacer bastante más que solo trabajar con textos. Por ejemplo, si descargamos un archivo Excel, no solo podrá abrirlo para leer su contenido, sino también dibujar gráficos e incluso sacar conclusiones de las estadísticas presentadas. Aquí no presentaremos el algoritmo ChatGPT en su totalidad, solo veremos fragmentos de cómo podría ser su aspecto.
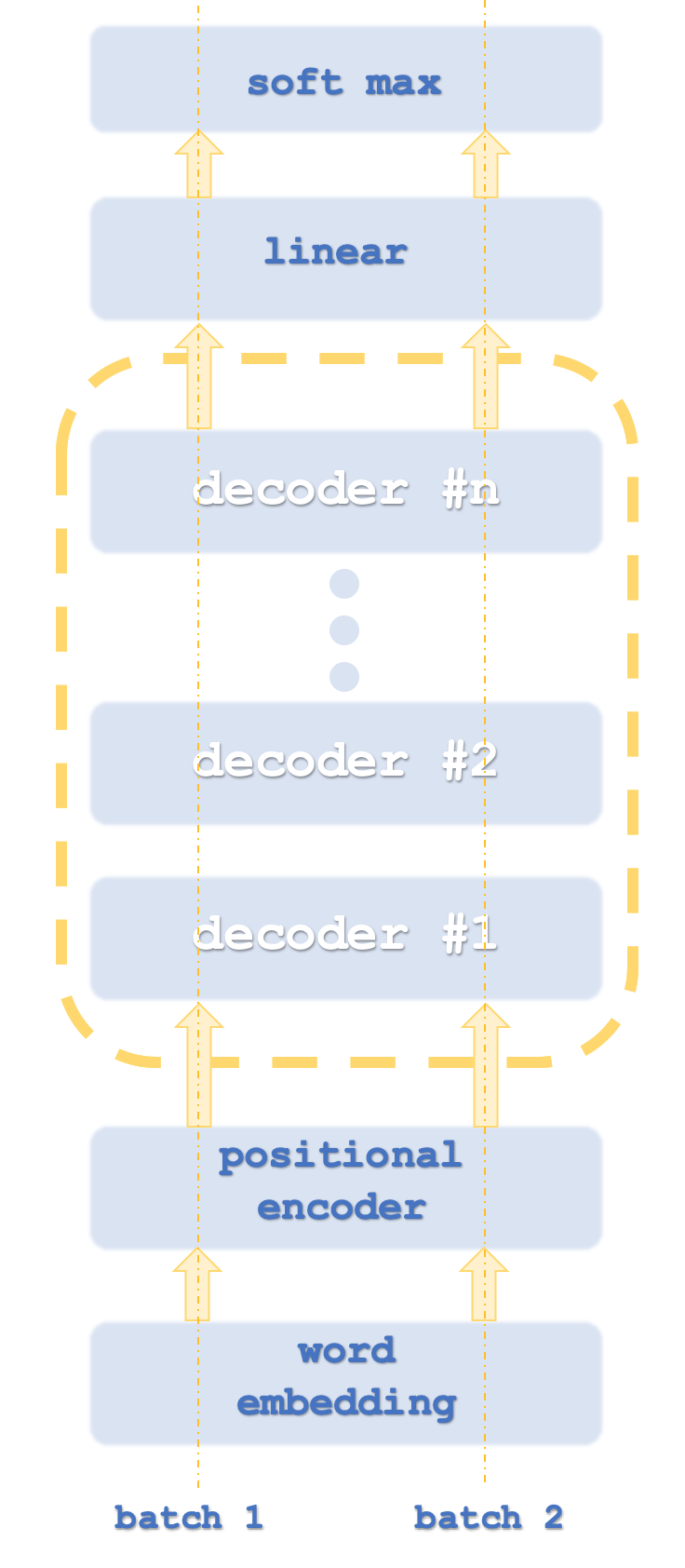
Los paquetes (batch) 1 y 2 son similares a los flujos de computadora porque los transformadores generalmente ejecutan ejemplares de red en paralelo.
Como estamos clasificando números, no se requerirá una representación vectorial de las palabras. La codificación posicional está diseñada para captar la importancia absoluta de cada palabra en una oración gracias a su posición. El algoritmo es simple: a cada palabra (es decir, token) se le asigna un valor de onda sinusoidal de una serie de ondas sinusoidales en distintas frecuencias. Los valores de cada onda se sumarán para obtener la codificación de la posición de ese token. Este valor podría ser un vector, lo cual significa que estará sumando valores de más de un array de frecuencias.
Y esto nos lleva a la autoatención. En este caso, se calculará la importancia relativa de cada palabra en una oración en relación con las palabras que la preceden en esa oración. Este esfuerzo aparentemente trivial resulta importante en oraciones que contienen, entre otras cosas, la palabra it (eso/ello). Por ejemplo, en la siguiente oración:
“The dish washer partly cleaned the glass and it cracked it” (el lavavajillas limpió parcialmente el cristal y lo partió)
¿A qué se refieren los pronombres it en este caso? Para una persona está claro lo que se dice (en la traducción al español no hay ningún problema gracias a la distinción entre el pronombre, en este caso omitido, y el objeto directo), pero para una máquina en proceso de aprendizaje no lo está. Por más trivial que parezca este problema a primera vista, fue precisamente la capacidad de cuantificar la importancia relativa de esta palabra lo que pudo resultar crucial en el lanzamiento de redes neuronales transformadoras, que resultaron ser más paralelizables y requirieron significativamente menos tiempo de entrenamiento que las redes recurrentes y las convolucionales, sus predecesoras.
Por tanto, en este artículo, la autoatención será un elemento clave en nuestra clase de señales de prueba. Curiosamente, el algoritmo de autoatención en realidad tiene similitudes con la manera en que las palabras se relacionan entre sí. Las relaciones entre las palabras que se usan para cuantificar la importancia relativa (similitud) pueden considerarse morfismos en los que las palabras mismas forman objetos. Esta relación resulta intrigante porque cada palabra necesita calcular la similitud o importancia para sí misma. ¡Y esto es muy similar al morfismo de identidad! Además, aparte de inferir morfismos y objetos, también podríamos asociar funtores y categorías respectivamente, como hemos visto en artículos recientes.
Decodificador del transformador
Normalmente, una red de transformadores contiene pilas de codificación y decodificación, y cada pila supone una repetición en las redes de autoatención y retroalimentación. Esto es algo similar a lo que mostramos a continuación:
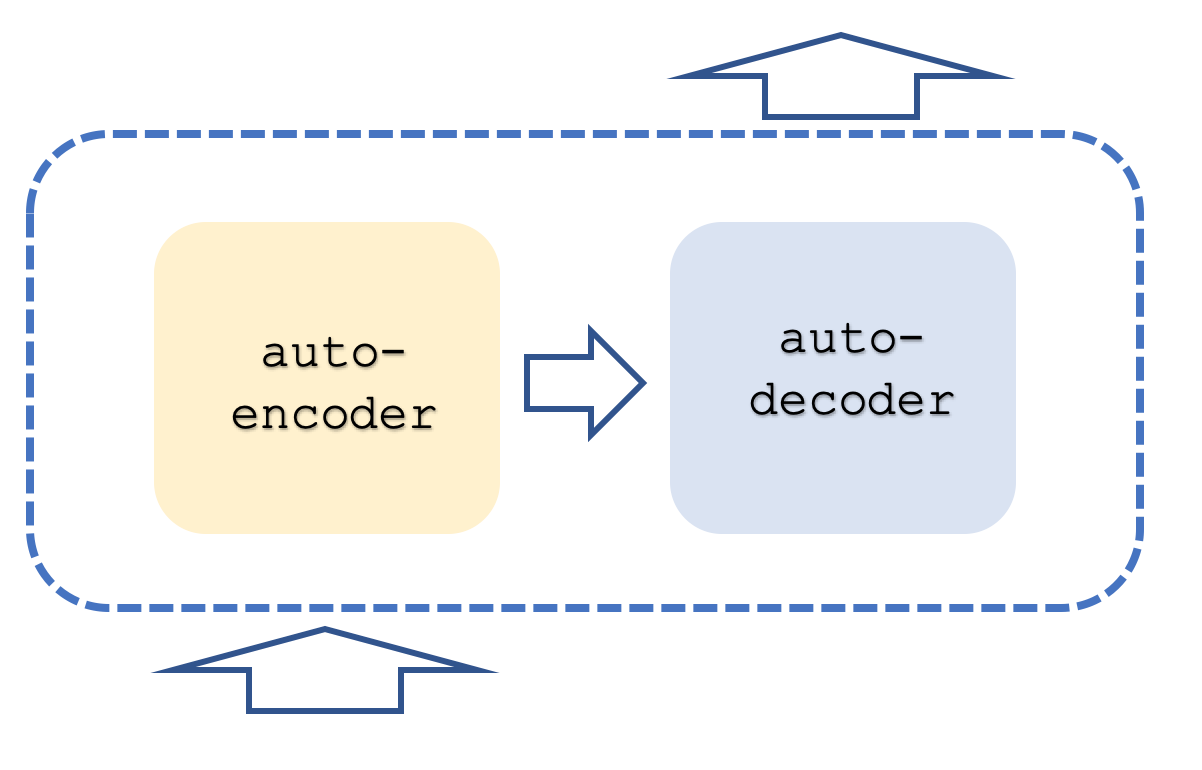
Además de esto, cada paso se ejecuta con "flujos" paralelos, lo cual significa que si, por ejemplo, el paso de autoatención y conexión directa pudiera representarse mediante un perceptrón multicapa, entonces si el transformador tuviera 8 flujos, tendríamos 8 flujos multicapa de los perceptrones. Obviamente, esto consumiría muchos recursos, pero esto es lo que le proporciona a este enfoque su ventaja porque incluso con este uso de recursos sigue siendo más eficiente que las redes convolucionales.
El enfoque usado por OpenAI se considera una variación de este enfoque y está destinado únicamente a la decodificación. Sus etapas se muestran aproximadamente en el primer esquema. Obviamente, usar solo la decodificación no afectará a la precisión del modelo, aunque ciertamente proporcionará un mejor rendimiento ya que solo se procesará "la mitad" de la transformación. La representación de la autoatención en la codificación difiere de la representación en la decodificación en que en la codificación, la importancia relativa de todas las palabras se calcula independientemente de la posición relativa en la oración. Obviamente, esto requiere aún más recursos, ya que, como hemos mencionado, en el lado del decodificador, la autoatención (llamada cálculo de similitud) se realizará solo para cada palabra en sí misma y solo para aquellas palabras que le precedan en la oración. Algunos podrían argumentar que esto incluso elimina la necesidad de codificación posicional, pero para nuestros objetivos la incluiremos en el código fuente. Nos centraremos en el enfoque solo de la decodificación.
El papel de las redes de autoatención, así como de las redes de conexión directa y de conexión directa en la etapa de transformación, será tomar los datos de salida de la codificación posicional o pila anterior y crear los datos de entrada para un paso lineal de SoftMax de los datos de entrada para el siguiente paso del decodificador dependiendo de la pila.
La codificación de la posición, que algunos pueden considerar innecesaria para nuestra clase de señal y el presente artículo, se incluye aquí con fines informativos. El orden absoluto de la información de entrada de la columna de precios puede resultar tan importante como la secuencia de palabras en una oración. Usaremos un algoritmo simple que retornará un vector de 4 cardinales de valores dobles que actuarán como las "coordenadas" de cada punto de precio de entrada.
Algunos podrían preguntar por qué no utilizamos una indexación simple para cada entrada. Resulta que esto hace que los gradientes desaparezcan al entrenar las redes y, por lo tanto, se requiere un formato menos variable y normalizado. Se podría hacer una analogía con una clave de cifrado de longitud estándar, digamos 128, independientemente de lo que estemos cifrando. Esto hace que resulte más difícil descifrar la clave privada, pero también ofrece una forma más eficiente de crear y almacenar claves.
Entonces usaremos 4 ondas sinusoidales en diferentes frecuencias. A veces, a pesar de estas 4 frecuencias, dos palabras pueden tener las mismas "coordenadas", pero esto no debería causar problemas, ya que, de suceder así, utilizaremos muchas palabras (o en nuestro caso, categorías de precios) para anular esta pequeña anomalía. Estos valores de coordenadas se añadirán a los cuatro puntos de precio de nuestro vector de entrada, que es lo que podríamos haber obtenido mediante la incorporación de palabras, pero no lo hemos hecho porque ya estamos tratando con números en forma de precios de instrumentos financieros. Nuestra clase de señal usará los cambios de precio. Para "normalizar" nuestra codificación de la posición, los valores de codificación de posición, que pueden oscilar entre +5,0 y -5,0, y a veces más, se multiplicarán por el tamaño del pip del instrumento financiero en cuestión antes de añadirse al cambio de precio.
Como podemos ver en los hipervínculos generales anteriores, el mecanismo de autoatención es responsable de determinar tres vectores, a saber, el vector de consulta, el vector clave y el vector de valor. Estos vectores se obtienen multiplicando el vector de codificación de la posición de salida por la matriz de pesos. ¿Cómo se obtienen dichos pesos? Usando la propagación inversa. No obstante, para nuestros propósitos, usaremos ejemplares de la clase de perceptrón multicapa para inicializar y entrenar estos pesos. Solo una capa. Una representación esquemática de este proceso en esta etapa crítica podría ser la que vemos:
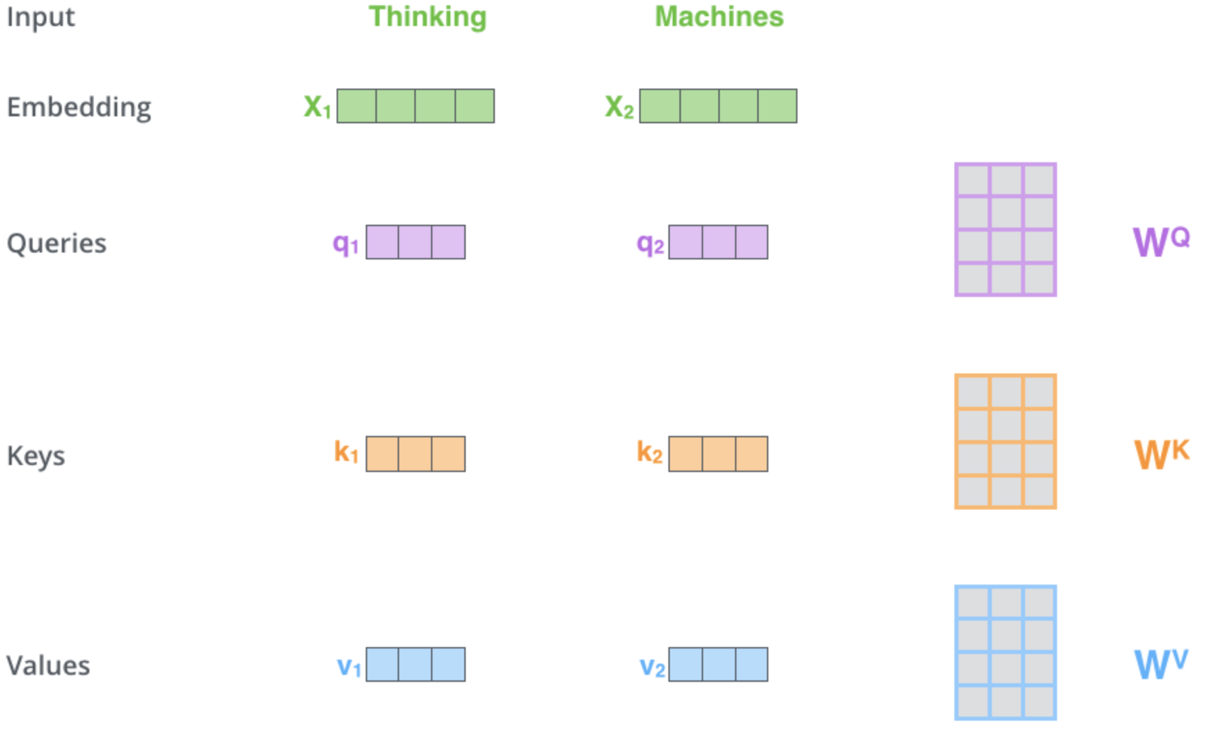
Esta ilustración y algunos de los puntos analizados en este artículo están tomados de aquí. En la imagen de arriba, se presentan dos palabras como datos de entrada: Thinking (pensamiento) y Machines (máquinas). Cuando están incorporados (convertidos en vectores numéricos), se convierten en vectores verdes. Las matrices de la derecha representan los pesos que vamos a obtener utilizando perceptrones multicapa, como hemos mencionado anteriormente.
Entonces, una vez que nuestras redes hacen una pasada directa, obteniendo los vectores de consulta, clave y valor, haremos el producto escalar de la consulta y la clave, dividiremos ese resultado por la raíz cuadrada del número cardinal del vector clave y obtendremos la similitud entre el precio con el vector de consulta y el precio con el vector clave. Estas multiplicaciones se realizarán en todos los puntos de precio según el mapa de autoatención, donde compararemos solo los puntos de precio con el precio en sí y con los precios que lo preceden. Los resultados han ofrecido valores muy dispersos, por lo que los normalizamos en una distribución de probabilidad utilizando la función SoftMax. La suma de todas estas ponderaciones de probabilidades, como se esperaba, es igual a uno. Tiene lugar una ponderación efectiva. En la última etapa, cada peso se multiplicará por su valor vectorial correspondiente y todos estos productos se sumarán en un vector que formará la salida de la capa de autoatención.
La red de conexión directa tomará el vector de autoatención de salida, lo procesará a través de un perceptrón multicapa y generará otro vector de tamaño similar al vector de autoatención de entrada.
La base teórica para implementar un decodificador transformador en MQL5 se basará en una clase simple de señales y no en un asesor. Este tema resulta bastante complejo en estos momentos, ya que algunas de las ideas expuestas existen desde hace menos de una década, por lo que parece que las pruebas y la presentación de los conceptos resultan más importantes que la propia ejecución y los resultados. El lector es libre de adoptar y aplicar estas ideas según le resulten necesarias.
Clase de señal MQL5: Una mirada a las redes de autoatención y conexión directa
¡La clase de señal adjunta a este artículo está diseñada para predecir cambios de precios utilizando un decodificador de transformador que tiene solo una pila y un flujo! El código adjunto se puede configurar para aumentar el número de pilas ajustando el parámetro de definición '__DECODERS'. Como ya hemos mencionado antes, generalmente hay varias pilas y, en la mayoría de los casos, son de flujos múltiples. Normalmente, un decodificador utiliza varias pilas, lo que hace que necesite una conexión residual (residual connection) para evitar el problema de los gradientes de desaparición y explosión. Entonces, vamos a trabajar con un transformador simple y ver qué puede hacer. El lector podrá continuar con el ajuste posterior para satisfacer sus propias necesidades de implementación.
La codificación posicional resulta probablemente la más simple de todas las funciones enumeradas, ya que simplemente retorna un vector de coordenadas dado el tamaño de los datos de entrada. El código se encuentra a continuación:
//+------------------------------------------------------------------+ //| Positional Encoding vector given length. | //+------------------------------------------------------------------+ vector CSignalCT::PositionalEncoding(int Positions) { vector _positions; _positions.Init(Positions);_positions.Fill(0.0); for(int i=0;i<Positions;i++) { for(int ii=0;ii<Positions;ii++) { _positions[i]+=MathSin((((ii+1)/Positions)*(i+1))*__PI); } } return(_positions); }
Entonces, nuestra clase de señal hará referencia a varias funciones, pero la principal será la función Decode, cuya fuente se detalla a continuación:
//+------------------------------------------------------------------+ //| Decode Function. | //+------------------------------------------------------------------+ void CSignalCT::Decode(int &DecoderIndex,matrix &Input,matrix &Sum,matrix &Output) { Input.ReplaceNan(0.0); // //output matrices Sum.Init(1,int(Input.Cols()));Sum.Fill(0.0); Ssimilarity _s[]; ArrayResize(_s,int(Input.Cols())); for(int i=int(Input.Rows())-1;i>=0;i--) { matrix _i;_i.Init(1,int(Input.Cols())); for(int ii=0;ii<int(Input.Cols());ii++) { _i[0][ii]=Input[i][ii]; } // SelfAttention(DecoderIndex,_i,_s[i].queries,_s[i].keys,_s[i].values); } for(int i=int(Input.Cols())-1;i>=0;i--) { for(int ii=i;ii>=0;ii--) { matrix _similarity=DotProduct(_s[i].queries,_s[ii].keys); Sum+=DotProduct(_similarity,_s[i].values); } } // Sum.ReplaceNan(0.0); // FeedForward(DecoderIndex,Sum,Output); }
Como podemos ver, llamará a las funciones de automantenimiento y de conexión directa y preparará los datos de entrada necesarios para ambas funciones de la capa.
La función de autoatención realizará los cálculos reales del peso de la matriz para obtener vectores de consultas, claves y valores. Hemos representado estos "vectores" como matrices, aunque para los objetivos de nuestra clase de señales usaremos matrices de una sola fila, ya que en la práctica a menudo se transmiten múltiples vectores a través de la red o se multiplican por un sistema matricial de pesos para producir la matriz de consultas, claves y valores. Fuente:
//+------------------------------------------------------------------+ //| Self Attention Function. | //+------------------------------------------------------------------+ void CSignalCT::SelfAttention(int &DecoderIndex,matrix &Input,matrix &Queries,matrix &Keys,matrix &Values) { Input.ReplaceNan(0.0); // Queries.Init(int(Input.Rows()),int(Input.Cols()));Queries.Fill(0.0); Keys.Init(int(Input.Rows()),int(Input.Cols()));Keys.Fill(0.0); Values.Init(int(Input.Rows()),int(Input.Cols()));Values.Fill(0.0); for(int i=0;i<int(Input.Rows());i++) { double _x_inputs[],_q_outputs[],_k_outputs[],_v_outputs[]; vector _i=Input.Row(i);ArrayResize(_x_inputs,int(_i.Size())); for(int ii=0;ii<int(_i.Size());ii++){ _x_inputs[ii]=_i[ii]; } m_base_q[DecoderIndex].MLPProcess(m_mlp_q[DecoderIndex],_x_inputs,_q_outputs); m_base_k[DecoderIndex].MLPProcess(m_mlp_k[DecoderIndex],_x_inputs,_k_outputs); m_base_v[DecoderIndex].MLPProcess(m_mlp_v[DecoderIndex],_x_inputs,_v_outputs); for(int ii=0;ii<int(_q_outputs.Size());ii++){ if(!MathIsValidNumber(_q_outputs[ii])){ _q_outputs[ii]=0.0; }} for(int ii=0;ii<int(_k_outputs.Size());ii++){ if(!MathIsValidNumber(_k_outputs[ii])){ _k_outputs[ii]=0.0; }} for(int ii=0;ii<int(_v_outputs.Size());ii++){ if(!MathIsValidNumber(_v_outputs[ii])){ _v_outputs[ii]=0.0; }} for(int ii=0;ii<int(Queries.Cols());ii++){ Queries[i][ii]=_q_outputs[ii]; } Queries.ReplaceNan(0.0); for(int ii=0;ii<int(Keys.Cols());ii++){ Keys[i][ii]=_k_outputs[ii]; } Keys.ReplaceNan(0.0); for(int ii=0;ii<int(Values.Cols());ii++){ Values[i][ii]=_v_outputs[ii]; } Values.ReplaceNan(0.0); } }
La función de conexión directa supondrá el procesamiento directo de un perceptrón multicapa y, desde nuestro punto de vista, el transformador de decodificación no tiene nada de especial. Obviamente, otras implementaciones podrán tener sus propias configuraciones, como múltiples capas ocultas o incluso otros tipos de redes como una máquina Boltzmann, pero para nuestros propósitos esta será una red simple con una capa oculta.
La función del producto escalar es interesante porque supondrá una implementación especial de la multiplicación de dos matrices. La usaremos principalmente para multiplicar matrices de una sola fila (llamadas vectores), pero se escalará y podrá resultar útil, ya que las pruebas preliminares de la función de multiplicación de matrices incorporada tienen errores en este momento.
La implementación de SoftMax se muestra en la Wikipedia. Todo lo que haremos es retornar un vector de probabilidades dado el array de valores de entrada. Los valores del vector de salida serán positivos y sumarán uno.
Entonces, nuestra clase de señal cargará datos de precios desde el 01.01.2020 hasta el 01.08.2023 para USDJPY. En el marco temporal diario, transmitiremos a la función de codificación de la posición un vector de 4 puntos de precio, que serán simplemente los últimos 4 cambios en el precio de cierre. Esta función, como hemos mencionado, toma las coordenadas de cada cambio de precio, las normaliza multiplicándolas por el tamaño del pip de USDJPY y las suma a los cambios de precio de entrada.
El vector de salida se transmitirá a la función Decode para calcular la consulta, la clave y el vector de valor para cada uno de los 4 valores de entrada del vector. Durante el automapeo (self-mapping), dado que para cada punto de precio la similitud solo se verificará consigo mismo, y el precio cambiará antes de eso, de 4 valores vectoriales terminaremos con 10 que necesitarán la normalización de SoftMax.
Pasando por SoftMax, obtendremos un array de diez pesos, de los cuales solo uno pertenecerá al primer punto de precio, 2 al segundo, 3 al tercero y 4 al cuarto. Entonces, como para cada punto de precio también tendremos un vector de valores que hemos obtenido al ejecutar la función de automantenimiento, multiplicaremos este vector por el peso correspondiente obtenido de SoftMax y luego sumaremos todos estos vectores en un vector de salida. Según su diseño, su valor deberá corresponderse con el valor del vector de entrada, ya que las pilas de transformadores estarán ubicadas en serie. Además, como hemos utilizado perceptrones multicapa, deberemos considerar que los pesos inicializados para cada una de las redes serán aleatorios y aprenderán (mejorarán) con cada barra posterior.
Nuestra clase de señal, compilada en un asesor y optimizada para los primeros 5 meses de 2023, y también ha pasado las pruebas paso a paso desde el 2023.06.01 hasta el 2023.08.01, y nos proporciona los siguientes informes:


Estos informes han sido generados por el asesor con la función de leer y escribir los pesos de red que no se utilizarán en el código adjunto ya que la implementación dependerá del usuario. Como los pesos no se leen de una fuente específica durante la inicialización, los resultados seguramente serán diferentes con cada ejecución.
Uso práctico
Las aplicaciones potenciales de esta clase particular de señales, en lugar de un decodificador de transformador, consistiría en encontrar valores potenciales para negociar con un decodificador transformador. Si probamos múltiples valores durante décadas, podremos entender qué vale la pena explorar más a fondo mediante pruebas adicionales y mejoras del sistema, y qué se debe evitar.
En la pila de transformador de decodificación, el nivel de autocontrol será crítico y definitivamente nos ofrecerá una ventaja ya que la red de conexión directa utilizada aquí será bastante simple. De esta manera, la importancia relativa de cada cambio de precio anterior se captará de tal manera que las funciones de correlación se oculten fácilmente porque estarán orientadas a la media. El uso de perceptrones multicapa para recopilar matrices de peso para los vectores de consulta, clave y valor es un enfoque que se puede utilizar, ya que existen muchas otras formas intermedias de lograr el objetivo usando el aprendizaje automático. En general, resultará clave comprender la sensibilidad de la autoatención respecto a la previsibilidad de la red.
Limitaciones y desventajas
El entrenamiento de la red para nuestra clase de señales se realizará de forma incremental en cada barra nueva y no utilizaremos la capacidad de cargar pesos previamente entrenados, lo cual significará que seguramente obtendremos muchos resultados aleatorios. Debido a esto, el lector deberá esperar un conjunto diferente de resultados cada vez que se ejecute la clase de señal.
Además, no utilizaremos la capacidad de almacenar los pesos entrenados al final de la clase de señal, lo que significa que no podremos usar lo que hemos aprendido aquí.
Estas limitaciones son de importancia crítica y, en mi opinión, deberán abordarse antes de continuar con el desarrollo de un decodificador transformador en un sistema comercial. No solo deberemos usar los pesos entrenados, sino que también deberemos poder almacenarlos, pero antes de implementar el sistema, se deberán realizar pruebas de datos fuera de muestra con los pesos entrenados.
Conclusión
¿El algoritmo ChatGPT está relacionado con las transformaciones naturales? Tal vez. Esto se debe a que si consideramos las pilas de decodificador-transformador como categorías, entonces los flujos (operaciones paralelas realizadas a través del transformador) serán funtores. Según esta analogía, la diferencia entre los resultados finales de cada operación será equivalente a una transformación natural.
Incluso sin un registro y lectura de pesos adecuados, nuestro decodificador transformador ha mostrado cierto potencial. Sin duda, se trata de un sistema interesante que podría desarrollarse más e incluso agregarse a nuestra caja de herramientas a medida que obtenga más beneficios.
En conclusión, podemos observar que el algoritmo de autoatención es capaz de cuantificar la similitud relativa entre tokens (datos de entrada del transformador). En nuestro caso, dichos tokens han representado los cambios de precio en momentos diferentes pero secuenciales en el tiempo. En otros modelos, estos podrían ser numerosos indicadores económicos, noticias o valores del sentimiento de los inversores, etc., pero el proceso sería el mismo; sin embargo, el resultado con estos diversos datos de entrada necesariamente revelará y, por lo tanto, modelará la interrelación compleja y dinámica de estos valores de entrada, ayudando al desarrollador a comprenderlos mejor. A largo plazo, esto permitirá que el transformador extraiga de forma adaptativa las características relevantes de los tokens de entrada con cada nueva sesión de entrenamiento. Así, incluso en situaciones inestables y con muchas novedades, el modelo debería filtrar el ruido y resultar más sólido.
Además, un algoritmo de automantenimiento cuando se enfrenta a datos tardíos o de entrada en diferentes momentos (como en el ejemplar de clase de señal que adjuntamos) ayuda a cuantificar la importancia relativa de estos diferentes periodos y, por lo tanto, captura dependencias de largo alcance. Esto conllevará la capacidad de pronosticar en diferentes horizontes temporales, lo cual es otra ventaja para los tráders. Entonces, para resumir, la ponderación relativa de los datos de entrada de los tokens debería proporcionar a los tráders información no solo sobre los diferentes indicadores económicos que pueden suponer datos de entrada, sino también sobre los diferentes marcos temporales si se utilizan indicadores (o precios) desfasados.
Recursos adicionales
Principalmente enlaces a artículos en la Wikipedia, y también publicaciones de la universidad de Cornell, Stack Exchange y este sitio web.
Nota del autor
El código fuente presentado en este artículo NO es el código usado por ChatGPT. Esto simplemente supone la implementación de un transformador-decodificador. Tiene un formato de clase de señal, lo cual significa que el usuario deberá compilarlo utilizando el wizard MQL5 para generar un asesor comprobable. Encontrará una guía aquí. Además, el usuario necesitará implementar mecanismos de lectura y escritura para leer y almacenar los pesos de red resultantes.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13348
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Teoría de categorías en MQL5 (Parte 20): Autoatención y transformador:
Autor: Stephen Njuki