
Características del Wizard MQL5 que debe conocer (Parte 07): Dendrogramas
Introducción
Este artículo, que forma parte de la serie sobre el uso del Wizard MQL5, hablaremos de los dendogramas. Ya hemos analizado varias ideas relacionadas con el Wizard MQL5 que pueden resultar útiles a los tráders, por ejemplo: El análisis discriminante lineal, las cadenas de Markov, la transformada de Fourier y otros. En este artículo veremos cómo utilizar el extenso código ALGLIB traducido por MetaQuotes junto con el uso del Wizard MQL5 incorporado para probar y desarrollar nuevas ideas de manera eficiente.
La clasificación jerárquica parece muy complicada, pero en realidad es bastante sencilla. En resumen, se trata de una forma de vincular diferentes partes de un conjunto de datos observando primero los principales clústeres individuales y, a continuación, agrupándolos sistemáticamente paso a paso hasta que todo el conjunto de datos se vea como una única unidad ordenada. El resultado de este proceso será un diagrama jerárquico, más comúnmente denominado dendrograma.
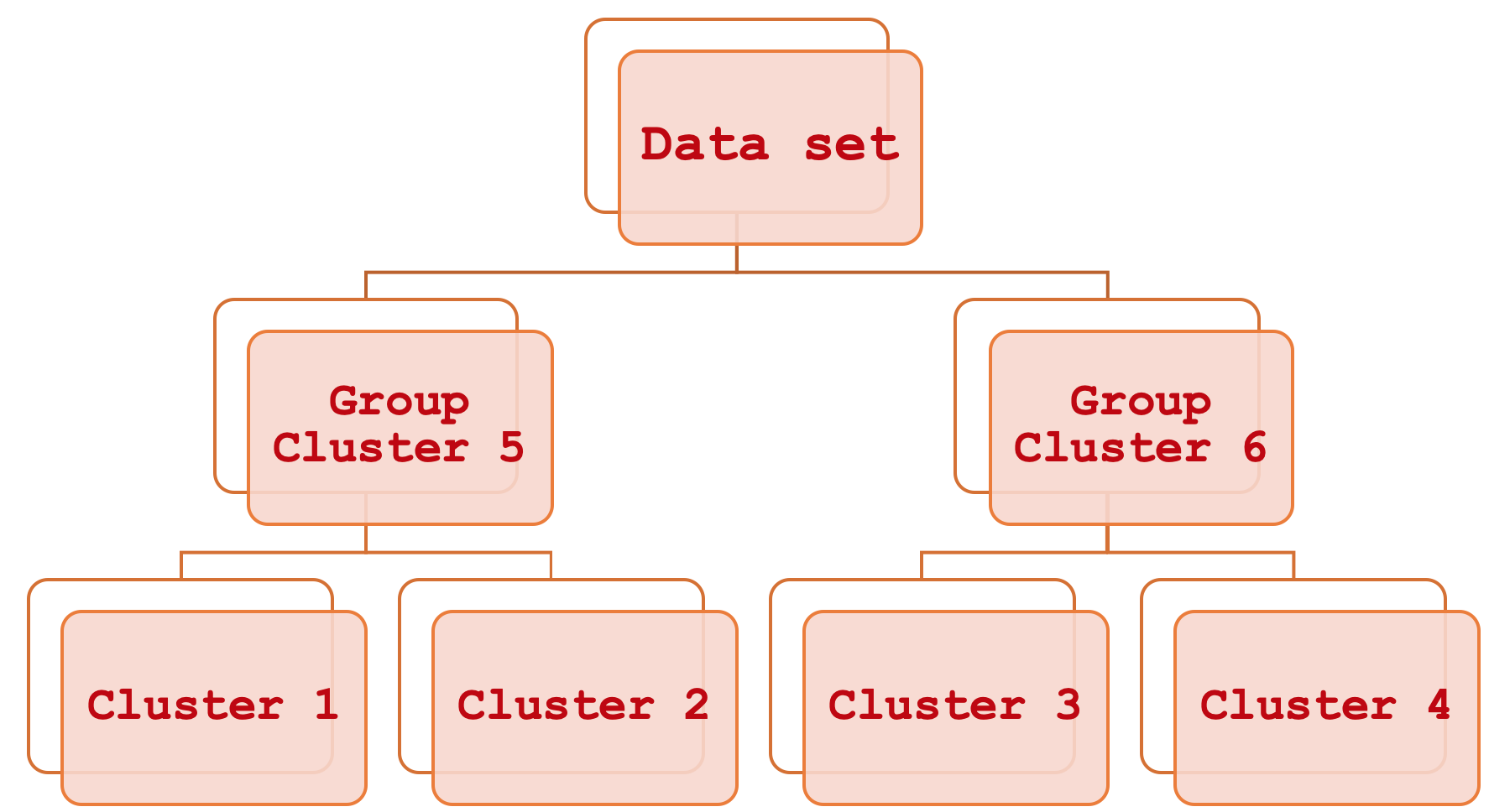
Este artículo se centrará en cómo estos clústeres constituyentes se pueden utilizar para estimar y así predecir el rango de las barras de precios, pero a diferencia de las partes anteriores donde hicimos esto para ayudar a establecer un trailing stop, aquí usaremos los conocimientos adquiridos para gestionar el dinero y el tamaño de la posición. Este artículo está dirigido a aquellos que están empezando a familiarizarse con la plataforma MetaTrader y el lenguaje de programación MQL5, por lo que algunos temas podrían parecer poco interesantes para los usuarios experimentados.
La importancia de predecir con exactitud el rango de precios es, en gran medida, subjetiva. Su importancia dependerá en gran medida de la estrategia del tráder y de su enfoque general del comercio. ¿Cuándo dejará de importar la exactitud de las predicciones? Por ejemplo, si en su configuración comercia usa un apalancamiento mínimo o nulo al principio, tiene un stop loss definido y tiende a mantener posiciones durante periodos largos que pueden durar, digamos, meses, y tiene un tamaño de posición de margen fijo (o incluso un tamaño de lote fijo). En este caso, la volatilidad de la barra de precios puede dejarse de lado mientras usted se concentra en comprobar las señales de entrada y salida. Sin embargo, si usted es un tráder intradía, utilizará mucho apalancamiento o no dejará posiciones abiertas durante el fin de semana, o tendrá un tiempo de permanencia en el mercado medio/corto, entonces el rango de la barra de precios será definitivamente algo que debe tener en cuenta. Vamos a explorar el uso del rango en la gestión de capital creando nuestro propio ejemplar de la clase ExpertMoney, pero su uso puede ir más allá de la gestión de capital e incluso incluir riesgos, dado que la capacidad de entender y predecir razonablemente el rango de una barra de precios puede ayudarnos a decidir cuándo aumentar las posiciones abiertas y, a la inversa, cuándo reducirlas.
Volatilidad
Los rangos de barras de precios (que es como definimos la volatilidad en este artículo) en el contexto del trading suponen la diferencia entre el máximo y el mínimo del precio del símbolo comerciado durante un periodo de tiempo determinado. Si tomamos, por ejemplo, el periodo de tiempo diario, y durante el día el precio del símbolo comerciado sube hasta el nivel H pero no por encima de H, y baja hasta el nivel L y de nuevo no por debajo de L, entonces nuestro rango (en el marco del presente artículo) se calculará de la siguiente manera:
H – L;
La volatilidad es importante debido a un fenómeno denominado clusterización o agrupamiento de volatilidad (volatility clustering). Se trata de un fenómeno en el que los periodos de alta volatilidad suelen ir seguidos de una mayor volatilidad y, a la inversa, los periodos de baja volatilidad también van seguidos de una menor volatilidad. La importancia de esto es subjetiva, como ya se ha dicho, pero para la mayoría de los tráders (incluidos, en mi opinión, todos los principiantes) saber cómo comerciar con apalancamiento puede suponer una ventaja a largo plazo, ya que la alta volatilidad puede llevar a un stop out no porque la señal de entrada fuera errónea, sino porque había demasiada volatilidad. Incluso si tenemos un stop loss decente, hay momentos en los que su precio podría no estar disponible. Aquí podemos recordar la historia del franco suizo en enero de 2015. En este caso, su posición será cerrada por el bróker al siguiente mejor precio disponible, que a menudo es peor que su stop loss. Solo las órdenes límite garantizan el precio, las órdenes stop y stop loss no ofrecen tal garantía.
Por ello, los rangos de barras de precios no solo ofrecen una visión general del entorno del mercado, sino que también pueden ayudar a determinar los niveles de precios de entrada e incluso de salida. Una vez más, dependiendo de la estrategia, si, por ejemplo, usted mantiene una posición larga en un símbolo, la amplitud del rango de la barra de precios prevista (lo que está pronosticando) puede determinar fácilmente o al menos indicar dónde colocar el nivel de entrada e incluso el take profit.
Me arriesgo a parecer aburrido, pero podría resultar útil destacar los principales tipos de velas de precios y mostrar sus respectivos rangos. Los patrones de velas más conocidos son descendente, ascendente, martillo, lápida, Doji de patas largas y libélula. Obviamente, hay más patrones, pero los mencionados cubren la mayoría de las situaciones que se pueden encontrar en un gráfico de precios. En todos estos casos, como se verá más adelante, el rango de la barra de precios es simplemente el precio máximo menos el precio mínimo.
Clasificación jerárquica aglomerativa
La Clasificación Jerárquica Aglomerativa (Agglomerative Hierarchical Classification, AHC) es un método consistente en clasificar los datos en un número determinado de clústeres y, a continuación, vincular estos clústeres de una manera jerárquica y sistemática a través de lo que se denomina dendograma. Las ventajas del método se relacionan principalmente con el hecho de que los datos que hay que clasificar suelen ser multivariantes, y por ello la necesidad de considerar muchas variables en un único punto de datos es algo que puede resultar difícil de tratar a la hora de hacer comparaciones. Por ejemplo, una empresa que desee evaluar a sus clientes basándose en la información obtenida de ellos puede usar este método porque la información cubrirá necesariamente varios aspectos de la vida de los clientes, como las compras anteriores, la edad, el sexo, la dirección, etc. La AHC, al cuantificar todas estas variables para cada cliente, crea clústeres a partir de los centroides aparentes de cada punto de datos. Además, estos clústeres se agrupan en una jerarquía para las relaciones sistemáticas, de modo que si una clasificación requiere, por ejemplo, 5 clústeres, la AHC proporcionará en un formato ordenado esos 5 clústeres, lo cual significa que se podrá inferir qué clústeres son más similares y cuáles son más diferentes. Esta comparación de clústeres, aunque secundaria, puede resultar útil si necesitamos comparar más de un punto de datos y resulta que están en clústeres distintos. La clasificación por clústeres determinará la distancia entre dos puntos según la separación entre sus respectivos clústeres.
Podemos decir que la clasificación AHC es aprendizaje no supervisado. Esto significa que puede utilizarse en previsiones con distintos clasificadores. En nuestro caso, pronosticaremos rangos de barras de precios. Otro usuario con los mismos clústeres entrenados podrá utilizarlos para predecir cambios en los precios de cierre u otro aspecto relevante para su comercio. Esto proporciona más flexibilidad que el aprendizaje supervisado sobre un clasificador concreto, porque en este caso el modelo solo se utilizará para predecir el aspecto sobre el que se ha sido clasificado. Esto significa que, para prever un objetivo diferente, habrá que reentrenar el modelo con un nuevo conjunto de datos.
Herramientas y bibliotecas
La plataforma MQL5 con su IDE nos permite desarrollar nuestros propios asesores desde cero. Hipotéticamente, podríamos seguir este camino. No obstante, esta opción requerirá muchas decisiones relativas al sistema comercial, que pueden variar de un tráder a otro a la hora de aplicar el mismo concepto. Además, el código de una implementación de este tipo puede resultar demasiado reajustado y propenso a errores y muy difícil de modificar para diferentes situaciones. Por ello, la forma más óptima será integrar nuestra idea en otras clases de asesor "estándar" ofrecidas por el Wizard MQL5. No solo tendremos que hacer menos depuración (incluso las clases incorporadas en MQL5 a veces tienen errores, pero son pocos), sino que, habiéndola guardado como un ejemplar de una de las clases estándar, la clase podrá utilizarse y combinarse con una amplia gama de otras clases en el Wizard MQL5 para crear diferentes asesores, lo cual asegurará la completitud del experimento.
El código de la biblioteca MQL5 contiene clases AlgLib, que se mencionaron en los artículos anteriores de esta serie y se volverán a usar en este artículo. Específicamente, en el archivo DATAANALYSIS.MQH, usaremos la clase CClustering y un par de otras clases relacionadas al crear la clasificación AHC para nuestros datos de series de precios. Como nos interesa principalmente el rango de las barras de precios, podemos deducir que nuestros datos de entrenamiento consistirán en dichos rangos de periodos anteriores. Al utilizar las clases de entrenamiento de datos de un archivo de inclusión de análisis de datos, los datos se suelen poner en una matriz XY, donde X denota las variables independientes, mientras que Y representa los clasificadores o "etiquetas" con los que se entrena el modelo. Ambos suelen estar representados en la misma matriz.
Preparando los datos para el entrenamiento
No obstante, en este artículo, como estamos realizando entrenamiento no supervisado, nuestros datos de entrada constarán solo de las variables independientes X, que serán los rangos históricos de las barras de precios. Al mismo tiempo, nos gustaría realizar predicciones observando un flujo diferente de datos relacionados, a saber, el rango final de barras de precios. Esto equivale a Y. Para combinar estos dos conjuntos de datos manteniendo la flexibilidad del aprendizaje no supervisado, podemos utilizar la siguiente estructura de datos:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CMoneyAHC : public CExpertMoney { protected: double m_decrease_factor; int m_clusters; // clusters int m_training_points; // training points int m_point_featues; // point featues ... public: CMoneyAHC(void); ~CMoneyAHC(void); virtual bool ValidationSettings(void); //--- virtual double CheckOpenLong(double price,double sl); virtual double CheckOpenShort(double price,double sl); //--- void DecreaseFactor(double decrease_factor) { m_decrease_factor=decrease_factor; } void Clusters(int value) { m_clusters=value; } void TrainingPoints(int value) { m_training_points=value; } void PointFeatures(int value) { m_point_featues=value; } protected: double Optimize(double lots); double GetOutput(); CClusterizerState m_state; CAHCReport m_report; struct Sdata { CMatrixDouble x; CRowDouble y; Sdata(){}; ~Sdata(){}; }; Sdata m_data; CClustering m_clustering; CRowInt m_clustering_index; CRowInt m_clustering_z; };
De esta forma, los rangos históricos de las barras de precios se recopilarán como un nuevo lote en cada nueva barra. Los asesores creados por el Wizard MQL5 tienden a tomar decisiones comerciales en cada nueva barra, y para los propósitos de nuestra prueba, esto será suficiente. De hecho, existen enfoques alternativos, como obtener un gran lote que abarque muchos meses o incluso años y luego analizar, a modo de prueba, lo bien que los grupos de modelos pueden separar las posibles barras de precios de baja volatilidad de las de alta volatilidad. También hay que considerar que solo usamos 3 clústeres, de los cuales el más externo es para las barras muy volátiles, otro es para la volatilidad muy baja, y otro para la volatilidad media. Nuevamente, podemos investigar, por ejemplo, 5 clústeres, pero el principio para nuestros fines será el mismo. Ahora clasificaremos los clústeres de mayor a menor volatilidad posible y determinaremos en qué clúster se encuentra nuestro punto de datos actual.
Rellenado con datos
El código para obtener los últimos rangos de barras en cada nueva barra y rellenar la estructura personalizada será como sigue:
m_data.x.Resize(m_training_points,m_point_featues); m_data.y.Resize(m_training_points-1); m_high.Refresh(-1); m_low.Refresh(-1); for(int i=0;i<m_training_points;i++) { for(int ii=0;ii<m_point_featues;ii++) { m_data.x.Set(i,ii,m_high.GetData(StartIndex()+ii+i)-m_low.GetData(StartIndex()+ii+i)); } }
El número de puntos de entrenamiento determinará el tamaño de nuestro conjunto de datos de entrenamiento. Se trata de un parámetro de entrada de puntos de datos personalizable. No obstante, este parámetro determinará el número de "dimensiones" que tiene cada punto de datos. Así que en nuestro caso por defecto, tendremos 4 dimensiones, pero eso solo significa que utilizaremos los últimos 4 rangos de barras de precios para definir cualquier punto de datos dado. Se parece a un vector.
Creación de clústeres
Así pues, una vez que tengamos los datos en nuestra estructura personalizada, el siguiente paso consistirá en modelarlos utilizando el generador de modelos AHC Alglib. En el listado de código, este modelo se llamará "estado", por lo que nuestro modelo se llamará m_state. Es un proceso de dos pasos. Primero generaremos los puntos del modelo a partir de los datos de entrenamiento proporcionados y luego ejecutaremos el generador AHC. El establecimiento de puntos puede considerarse como la inicialización del modelo y la garantía de que todos los parámetros clave están claramente definidos. En nuestro código, la llamada se dará de la forma siguiente:
m_clustering.ClusterizerSetPoints(m_state, m_data.x, m_training_points, m_point_featues, 20);
El segundo paso importante será ejecutar el modelo para identificar los clústeres de cada uno de los puntos de datos ofrecidos en el conjunto de datos de entrenamiento. Esto se logrará llamando a la función ClusterizerRunAHC como se describe a continuación:
m_clustering.ClusterizerRunAHC(m_state, m_report);
Desde la perspectiva de Alglib, esta será la base para crear los clústeres que necesitamos. Esta función realizará un breve preprocesamiento y luego llamará a la función protegida (privada) ClusterizerRunAHCInternal, que hace todo el trabajo duro. Todo lo que necesitamos se puede encontrar en el archivo include\math\AlgLib\dataanalysis.mqh, a partir de la línea 22463. Merece especial atención la generación de dendrogramas en el array de salida cidx. Este array combina hábilmente una gran cantidad de información de clústeres en un solo array. Poco antes, deberemos crear una matriz de distancias para todos los puntos de datos de entrenamiento utilizando sus centroides. Esta matriz captura los valores de la matriz de distancias que coinciden con los índices de los clústeres; además, los primeros valores hasta el número total de puntos de entrenamiento representan el clúster de cada punto, mientras que los índices subsiguientes representan la fusión de estos clústeres para formar un dendrograma.
Igualmente digno de mención es el tipo de distancia usado para crear la matriz de distancias. Hay nueve opciones disponibles, que van desde la distancia Chebyshev y la distancia euclidiana hasta la correlación de rangos de Spearman. A cada una de estas alternativas se le asigna un índice que fijamos al llamar a la función de establecimiento de valores mencionada anteriormente. La selección del tipo de distancia debe ser muy sensible a la naturaleza y el tipo de clústeres que vamos a crear, por lo que deberemos prestar atención a este aspecto. El uso de la distancia euclídea (cuyo índice es 2) ofrece una mayor flexibilidad de implementación a la hora de configurar el algoritmo AHC, ya que a diferencia de otros tipos de distancias, aquí se puede utilizar el método de Ward.
Obtención de clústeres
La extracción de clústeres es tan sencilla como su creación. Simplemente llamaremos a una única función ClusterizerGetKClusters, y esta extraerá dos arrays del informe de salida de la función de generación de clústeres que llamamos anteriormente (ejecutamos AHC). Los arrays suponen un array de índices de clústeres, así como matrices de z-clústeres, y establecen no solo cómo se definen los clústeres, sino también cómo se puede generar un dendrograma a partir de ellos. Llamar a esta función es simple, como describimos a continuación:
m_clustering.ClusterizerGetKClusters(m_report, m_clusters, m_clustering_index, m_clustering_z);
La estructura de los clústeres obtenidos es muy sencilla, ya que en nuestro caso estamos clasificando nuestro conjunto de datos de entrenamiento en solo 3 clústeres. Esto significa que no tendremos más de tres niveles de fusión dentro de un dendrograma. Si utilizáramos más clústeres, nuestro dendrograma sería sin duda más complejo y tendría potencialmente n-1 niveles de fusión, donde n sería el número de clústeres utilizados por el modelo.
Marcado de los puntos de datos
A continuación, marcaremos los puntos de datos de entrenamiento para facilitar la predicción. No nos interesa simplemente clasificar los conjuntos de datos, pero sí queremos usarlos, por lo que nuestras "etiquetas" serán el rango de precios final después de cada punto de datos de entrenamiento. Así, extraeremos un nuevo conjunto de datos para cada nueva barra, que incluirá el punto de datos actual cuya volatilidad final se desconoce. Por eso omitiremos el punto de datos con el índice 0 al marcarlo, como se muestra en nuestro código a continuación:
for(int i=0;i<m_training_points;i++) { if(i>0)//assign classifier only for data points for which eventual bar range is known { m_data.y.Set(i-1,m_high.GetData(StartIndex()+i-1)-m_low.GetData(StartIndex()+i-1)); } }
Por supuesto, también pueden usarse otras opciones de marcado. Por ejemplo, en lugar de centrarnos solo en el rango de precios de la siguiente barra, podríamos considerar el rango de, digamos, las siguientes cinco o diez barras, utilizando el rango total de esas barras como valor y. Este enfoque podría provocar valores más "precisos" y menos erróneos, y de hecho la misma predicción se puede utilizar si nuestras etiquetas se dan para la dirección del precio (cambio en el precio de cierre), lo cual redundará en la predicción no de una, sino de muchas más barras. En cualquier caso, como nos hemos saltado el primer índice, al no tener su valor final, nos habríamos saltado n barras (donde n será la barra más cercana que queremos proyectar). Este planteamiento a largo plazo provocará un retraso considerable debido al incremento de n. Por otro lado, los grandes retrasos nos permitirán realizar una comparación segura con el valor previsto, ya que el retraso será solo de una barra respecto al valor objetivo y.
Previsión de la volatilidad
Una vez finalizado el "marcado" del conjunto de datos entrenado, podemos proceder a determinar a qué clúster pertenece nuestro punto de datos actual entre los clústeres definidos en el modelo. Para ello, bastará con recorrer los arrays de salida del informe de simulación y comparar el índice de clúster del punto de datos actual con los índices de los demás puntos de datos de entrenamiento. Si coinciden, pertenecerán al mismo clúster. A continuación le mostramos un código relativamente sencillo:
if(m_report.m_terminationtype==1) { int _clusters_by_index[]; if(m_clustering_index.ToArray(_clusters_by_index)) { int _output_count=0; for(int i=1;i<m_training_points;i++) { //get mean target bar range of matching cluster if(_clusters_by_index[0]==_clusters_by_index[i]) { _output+=(m_data.y[i-1]); _output_count++; } } // if(_output_count>0){ _output/=_output_count; } } }
Una vez encontrada una coincidencia, procederemos simultáneamente a calcular el valor Y medio de todos los puntos de datos de entrenamiento en ese clúster. Obtener un valor medio podría considerarse un método bastante rudimentario, pero puede utilizarse. Otros métodos posibles serían hallar la mediana o el módulo. Independientemente de la opción elegida, se aplicará el mismo principio de obtención del valor Y de nuestro punto actual solo a partir de otros puntos de datos de su clúster.
Uso de dendrogramas
El código fuente anterior muestra cómo pueden utilizarse los clústeres individuales creados para la clasificación y la previsión. ¿Cuál es entonces el papel del dendrograma? ¿Por qué resulta importante cuantificar lo diferente que es cada clúster de los demás? Para responder a esta pregunta, podríamos analizar la comparación de dos puntos de datos de entrenamiento en lugar de clasificar solo uno, como hemos hecho. En términos de volatilidad en este escenario, podríamos obtener datos de la historia en un punto de inflexión clave (esto podría ser un fractal clave en las fluctuaciones de precios si estamos pronosticando la dirección de los precios, pero en este artículo estamos mirando la volatilidad). Como tendremos clústeres de ambos puntos, la distancia entre ellos nos dirá lo cerca que se encuentra nuestro punto de datos actual del punto de inflexión pasado.
Ejemplos
Hemos realizado varias pruebas utilizando un asesor construido por el Wizard con un ejemplar de la clase de gestión de capital configurada. La clase de señales se basa en el oscilador Awesome. El asesor se ha ejecutado en EURUSD H4 del 2022.10.01 al 2023.10.01. A continuación le presentamos el informe:

Como control, también realizamos pruebas con las mismas condiciones que las anteriores, excepto que hemos utilizado la opción de margen fijo proporcionada por la biblioteca como gestión de capital, y esto nos ha dado el siguiente informe:

La consecuencia de nuestra prueba resumida basada en estos dos informes es que existe la posibilidad de ajustar nuestro volumen en función de la volatilidad predominante del símbolo. Los ajustes utilizados para nuestro asesor y control se muestran a continuación.

Y

Como podemos ver, en su mayoría hemos usado ajustes similares con la excepción de nuestro asesor, donde hemos tenido que cambiarlos para la gestión de capital.
Conclusión
Hoy hemos analizado cómo la clasificación jerárquica aglomerativa y el dendrograma pueden ayudar a identificar y evaluar diferentes conjuntos de datos y cómo esta clasificación puede utilizarse para hacer predicciones. Como siempre, las ideas generales y el código fuente sirven para poner a prueba las ideas, especialmente en contextos en los que se combinan con distintos enfoques, por eso utilizamos el formato de código de las clases del Wizard MQL5.
Notas a las aplicaciones
El código adjunto está destinado a ser ensamblado con el Wizard MQL5 como parte de un conjunto que incluye un archivo de clase de señal y un archivo de clase de trailing. En este artículo, el archivo de señal es el oscilador Awesome (SignalAO.mqh). Aquí encontrará más información sobre el uso del Wizard.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13630
 Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso