
Validación cruzada y fundamentos de la inferencia causal en modelos CatBoost, exportación a formato ONNX

Introducción
En artículos anteriores hemos descrito distintas formas originales de utilizar algoritmos de aprendizaje automático para crear sistemas comerciales. Algunos han tenido bastante éxito, otros (sobre todo los de las primeras publicaciones) se han sobreentrenado. Así, la secuencia de mis artículos refleja la evolución de una comprensión: de qué es capaz realmente el aprendizaje automático y de qué no. Obviamente, se trata de la clasificación de series temporales.
Por ejemplo, en el artículo anterior "Metamodelos en el aprendizaje automático", mostramos un algoritmo para encontrar patrones mediante la interacción de dos clasificadores. Elegimos esta forma no trivial porque los algoritmos de MO son buenos en la generalización y la predicción, pero son "perezosos" con respecto a la búsqueda de relaciones causales. Es decir, generalizan a partir de ejemplos de entrenamiento que ya pueden tener una relación causal inherente que persiste en los nuevos datos, pero esta relación también puede ser asociativa, es decir, momentánea y poco fiable.
El modelo no entiende las conexiones con las que está tratando, para él todos los datos de entrenamiento son solo datos de entrenamiento. Y eso supone un gran problema para los principiantes que intentan enseñarle a comerciar de forma rentable con datos nuevos. Por ello, en el último artículo intentamos enseñar al algoritmo a analizar sus propios errores para separar las predicciones estadísticamente significativas de las aleatorias basadas en ellos.
El presente trabajo supondrá una ampliación del tema anterior y el siguiente paso hacia la creación de un algoritmo de autoaprendizaje capaz de buscar patrones en los datos, minimizando el ajuste a los datos de entrenamiento. Al fin y al cabo, queremos obtener un efecto real de la aplicación del aprendizaje automático, de forma que no solo generalice los ejemplos de entrenamiento, sino que también determine la presencia de relaciones causa-efecto en ellos.
Yin (teoría).
En esta sección, habrá algunos razonamientos subjetivos basados en un mínimo de experiencia adquirida al intentar crear "Inteligencia Artificial" en Fórex. Porque aún no es amor, pero sigue siendo una experiencia.
Del mismo modo que nuestras conclusiones suelen ser erróneas y necesitan ser verificadas, los resultados de las predicciones de los modelos de aprendizaje automático necesitarán una doble comprobación. Si volvemos el proceso de doble comprobación hacia nosotros mismos, lograremos el autocontrol. El autocontrol de un modelo de aprendizaje automático se reduce a comprobar sus predicciones en busca de errores muchas veces en situaciones diferentes pero similares. Si el modelo comete pocos errores de media, entonces no estará sobreentrenado, pero si comete errores frecuentes, entonces hay algo que no funciona.
Si entrenamos el modelo una vez con los datos seleccionados, no podrá realizar el autocontrol. Si entrenamos el modelo muchas veces con submuestras aleatorias y luego probamos la calidad de la predicción en cada una de ellas y sumamos todos los errores, obtendremos una imagen relativamente fiable de los casos en los que se equivoca mucho y los casos en los que acierta con frecuencia. Podemos dividir estos casos en dos grupos, separándolos entre sí. Supone el análogo de realizar una validación walk-forward o una validación cruzada, pero con elementos adicionales. Esta es la única forma de implementar el autocontrol y obtener un modelo más sólido.
Por ello, es necesario realizar una validación cruzada en el conjunto de datos de entrenamiento, comparar las predicciones del modelo con las etiquetas de entrenamiento y promediar los resultados en todos los pliegues. Los ejemplos que se han pronosticado incorrectamente por término medio deben eliminarse de la muestra de entrenamiento final como erróneos. Sigue siendo necesario entrenar un segundo modelo ya en todos los datos, que distinga los casos bien predecibles de los mal predecibles, lo cual permite la cobertura más completa de todos los resultados posibles.
Cuando se eliminan los malos ejemplos de entrenamiento, el modelo básico tendrá un pequeño error de clasificación, pero pronosticará mal en los casos que se han eliminado como difíciles de predecir. Tendrá gran precisión pero poca exhaustividad. Si ahora añadimos un segundo clasificador y lo entrenamos para que permita al primer modelo comerciar solo en los casos que el primero ha aprendido a clasificar bien, debería mejorar los resultados de toda la TC, ya que tiene menor precisión pero mayor exhaustividad.
Resulta que los errores del primer modelo se transfieren como si nada al segundo clasificador, pero no desaparecen, por lo que ahora pronosticará incorrectamente con más frecuencia. Sin embargo, debido a que no predice directamente la dirección del comercio y la cobertura de datos resulta mayor, estas predicciones seguirán teniendo valor.
Supondremos que los dos modelos resultan suficientes para compensar los errores de formación con sus resultados positivos.
Así, usando un método de exclusión de malos ejemplos de entrenamiento, buscaremos situaciones que sean rentables por término medio. Además, intentaremos no comerciar en lugares que, por término medio, provoquen pérdidas.
Núcleo del algoritmo
La función "meta lerner" es el núcleo del algoritmo e implementa todo lo mencionado, por lo que conviene analizarla con más detalle. Las demás funciones serán auxiliares.
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=folds_number) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 return data[data.columns[1:]]
En la entrada admite:
- el número de pliegues para la validación cruzada
- el número de iteraciones de entrenamiento para el lerner básico
- la profundidad del árbol básico de lerner
- el paso de gradiente
Estos parámetros afectarán al resultado final y deberán elegirse empíricamente, o en una cuadrícula.
La función cross_val_predict del paquete scikit learn retorna las puntuaciones de validación cruzada para cada ejemplo de entrenamiento, después de lo cual, estas puntuaciones se comparan con las etiquetas originales. Si las predicciones son erróneas, se introducirán en un libro de malos ejemplos, que luego se usará para generar "metaetiquetas" para el segundo clasificador.
La función retornará el marco de datos que se le ha transmitido, con las "metaetiquetas" añadidas. Este marco de datos se utilizará después para entrenar los modelos finales, como se muestra en el listado.
# features for model\meta models. We learn main model only on filtered labels X, X_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[:-2]] X = X[X.columns[:-2]] # labels for model\meta models y, y_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[-1]] y = y[y.columns[-2]]
En el código podemos observar que el primer modelo se entrena solo con las filas cuyas metaetiquetas coinciden con la unidad, es decir, etiquetadas como buenos ejemplos de entrenamiento, mientras que el segundo clasificador se entrena en el conjunto de datos completo.
Y a partir de ahí se entrenan los dos clasificadores. Uno pronosticará las probabilidades de compra y venta, mientras que el otro pronosticará si merece la pena comerciar o no.
Aquí también cada modelo tendrá sus propios parámetros de entrenamiento, que no se representarán en hiperparámetros. Estos pueden configurarse por separado, pero hemos elegido deliberadamente un número pequeño de iteraciones, igual a 100, para que los modelos no se sobreentrenen también en este último paso. Podremos cambiar los tamaños relativos de train y test, lo que también tendrá un ligero efecto en los resultados finales. En general, el primer modelo resulta bastante fácil de entrenar, ya que solo se entrena con ejemplos bien clasificados, por lo que no se requerirá una gran complejidad del modelo. El segundo modelo tiene un problema más complicado, así que podremos aumentar la complejidad del modelo.
# train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False)
Hiperparámetros del algoritmo
Antes de comenzar el entrenamiento, deberemos configurar correctamente todos los parámetros de entrada que también afectarán al resultado final.
export_path = '/Users/dmitrievsky/Library/Application Support/MetaTrader 5/\ Bottles/metatrader5/drive_c/Program Files/MetaTrader 5/MQL5/Include/'
# GLOBALS SYMBOL = 'EURUSD' MARKUP = 0.00015 PERIODS = [i for i in range(10, 50, 10)] BACKWARD = datetime(2015, 1, 1) FORWARD = datetime(2022, 1, 1)
- Ruta a la carpeta "Include" del terminal para guardar los modelos entrenados.
- Ticker del símbolo
- Margen medio en puntos, incluidos el spread, las comisiones y los deslizamientos
- Los periodos de las medias móviles sobre los que se calcularán los incrementos de precio. Estas son las características para entrenar el modelo.
- El intervalo de fechas para el entrenamiento. A la izquierda y a la derecha de este intervalo quedará la historia fuera de entrenamiento (OOT), para las pruebas con datos nuevos.
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame:
Esta función tiene argumentos min y max, para muestrear operaciones de forma aleatoria. Cada nueva operación tendrá una duración aleatoria en barras. Si establecemos los mismos valores, todas las operaciones tendrán una duración fija.
Funciones y bibliotecas auxiliares
Antes de empezar, asegúrese de que todos los paquetes necesarios han sido instalados e importados
import numpy as np import pandas as pd import random import math from datetime import datetime import matplotlib.pyplot as put from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_predict
A continuación, exporte las cotizaciones desde el terminal MetaTrader 5. Luego elija el símbolo, el marco temporal y la profundidad de la historia deseados, y guárdelos en el subdirectorio /files de su proyecto Python.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/EURUSD_H1.csv', delim_whitespace=True) pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<CLOSE>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') pFixed = pFixed.dropna() pFixedC = pFixed.copy() count = 0 for i in PERIODS: pFixed[str(count)] = pFixedC.rolling(i).mean() - pFixedC count += 1 return pFixed.dropna()
Las partes resaltadas muestran de dónde obtiene el bot las cotizaciones y cómo crea las características: restando los precios de cierre de la media móvil especificada en la lista PERIODS como hiperparámetro.
El conjunto de datos generado se pasará a la siguiente función para marcar etiquetas (u objetivos).
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame: labels = [] meta_labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr < curr_pr: labels.append(1.0) if future_pr + MARKUP < curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) elif future_pr > curr_pr: labels.append(0.0) if future_pr - MARKUP > curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) else: labels.append(2.0) meta_labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset['meta_labels'] = meta_labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Esta función retornará el mismo marco de datos, pero con las columnas adicionales "labels" y "meta labels".
La función del simulador se ha acelerado enormemente, ahora podrá cargar grandes conjuntos de datos y no preocuparse de que el simulador vaya demasiado lento:
def tester(dataset: pd.DataFrame, plot= False): last_deal = int(2) last_price = 0.0 report = [0.0] chart = [0.0] line = 0 line2 = 0 indexes = pd.DatetimeIndex(dataset.index) labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() close = dataset['close'].to_numpy() for i in range(dataset.shape[0]): if indexes[i] <= FORWARD: line = len(report) if indexes[i] <= BACKWARD: line2 = len(report) pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta==1: last_price = pr last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 report.append(report[-1] - MARKUP + (pr - last_price)) chart.append(chart[-1] + (pr - last_price)) continue if last_deal == 1 and pred < 0.5 and pred_meta==1: last_deal = 2 report.append(report[-1] - MARKUP + (last_price - pr)) chart.append(chart[-1] + (pr - last_price)) y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(chart) plt.axvline(x = line, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x = line2, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
La función auxiliar de comprobación de modelos ya entrenados tiene ahora un aspecto más conciso. Toma una lista de modelos como entrada, calcula las probabilidades de las clases y las transmite al simulador como si se tratara de un frame de datos listo con características y etiquetas para la prueba. Por lo tanto, el propio simulador trabajará tanto con los frames de datos de entrenamiento inicial como con los frames de datos formados como resultado de la obtención de pronósticos de modelos ya entrenados.
def test_model(result: list, plt= False): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
YANG (práctica)
Tras establecer los hiperparámetros, pasaremos directamente al entrenamiento del modelo, que se realizará en un ciclo.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learner(folds_number= 5, iter= 150, depth= 5, l_rate= 0.01)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
Aquí entrenaremos 25 modelos, tras lo cual los probaremos y exportaremos al terminal MetaTrader5.
Los resultados del entrenamiento se ven más influidos por los parámetros resaltados, así como por el intervalo de fechas para el entrenamiento y las pruebas, y la duración de las operaciones. Conviene experimentar con estos parámetros.
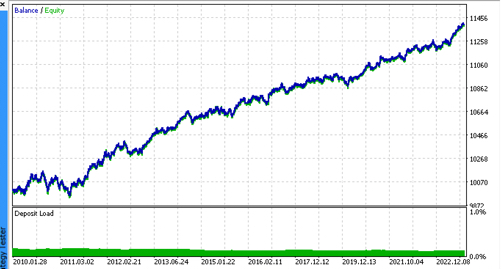
Vamos a echar un vistazo a los 5 mejores modelos según R^2, considerando los nuevos datos. Las líneas horizontales de los gráficos muestran los OOS a izquierda y derecha.
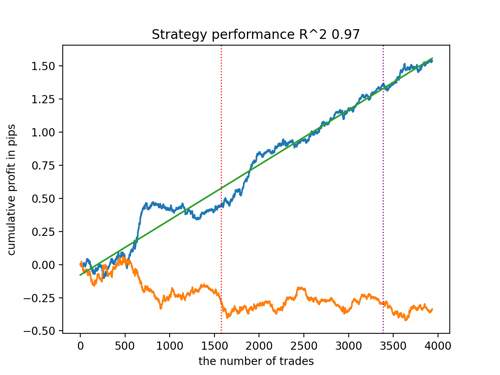
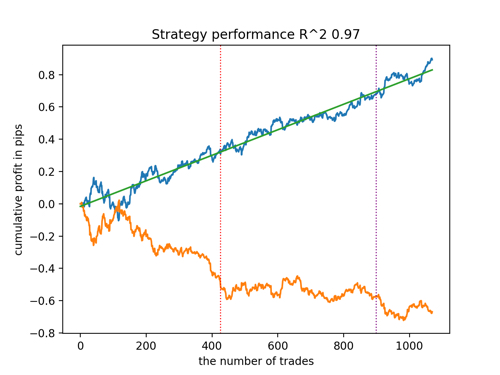
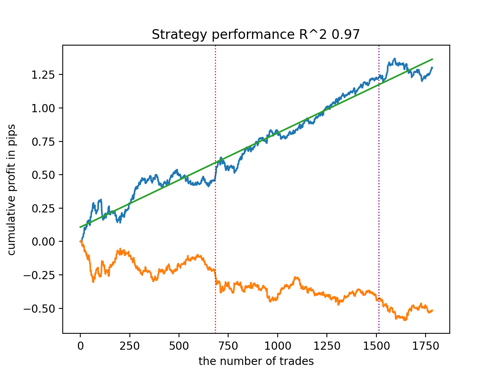
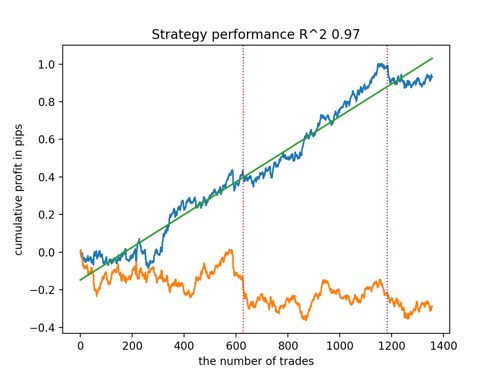
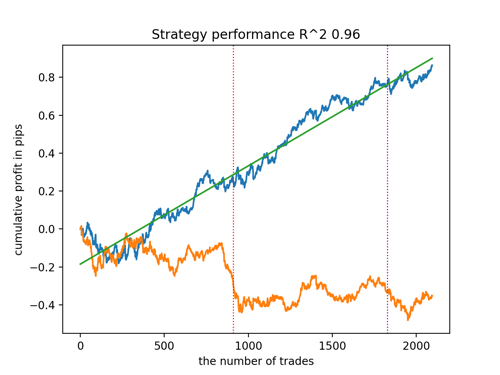
El gráfico de balance se muestra en azul, mientras que el de cotizaciones se muestra en naranja. Podemos observar que todos los modelos son diferentes entre sí. Esto se debe al muestreo aleatorio de las operaciones y a la aleatoriedad de cada modelo. No obstante, estos modelos ya no parecen los griales de los simuladores y trabajan de forma bastante segura con OOS. Además, podemos comparar el número de operaciones, el beneficio en pips y el aspecto general de las curvas. Por supuesto, los modelos primero y segundo se compararán favorablemente, así que los exportaremos al terminal.
Tenga en cuenta que cambiando los parámetros de entrenamiento y haciendo múltiples reinicios obtendremos un comportamiento único, los gráficos casi nunca serán idénticos, pero una parte significativa de ellos (importante) se mostrará bastante bien con OOS.
Exportación del modelo al formato ONNX
En artículos anteriores hemos utilizado parseo de modelos sintácticos de lenguaje cpp a lenguaje MQL. El terminal MetaTrader 5 ahora admite la importación de modelos en formato ONNX. Esto resulta muy útil porque podemos escribir menos código y portar casi cualquier modelo entrenado en el lenguaje Python.
El algoritmo CatBoost tiene su propio método de exportación de modelos al formato ONNX. Veamos el proceso de exportación con mayor detalle.
Como salida, tenemos dos modelos CatBoost y una función que genera características como incrementos. Como la función resulta bastante sencilla, nos limitaremos a trasladarla al código del bot, mientras que los modelos se exportarán a archivos ONNX.
def export_model_to_ONNX(model, model_number): model[1].save_model( export_path +'catmodel' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) model[2].save_model( export_path + 'catmodel_m' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) code = '#include ' code += '\n' code += '#resource "catmodel'+str(model_number)+'.onnx" as uchar ExtModel[]' code += '\n' code += '#resource "catmodel_m'+str(model_number)+'.onnx" as uchar ExtModel2[]' code += '\n' code += 'int Periods' + '[' + str(len(PERIODS)) + \ '] = {' + ','.join(map(str, PERIODS)) + '};' code += '\n\n' # get features code += 'void fill_arays' + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods''[i],pr);\n' code += ' ret[0] = MathMean(pr) - pr[Periods[i]-1];\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(SYMBOL) + ' ONNX include' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
A la función de exportación se le transmitirá una lista de modelos, cada uno de los cuales se guardará en ONNX, con parámetros de exportación opcionales. Todo este código guarda los modelos en la carpeta Include del terminal, y también genera un archivo .mqh que tiene este aspecto:
#resource "catmodel.onnx" as uchar ExtModel[] #resource "catmodel_m.onnx" as uchar ExtModel2[] #include int Periods[4] = {10,20,30,40}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods[i],pr); ret[0] = MathMean(pr) - pr[Periods[i]-1]; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Luego deberemos conectarlo al robot. Cada archivo tiene un nombre único, que se especificará mediante una marca de símbolo y un número de serie del modelo al final. Por lo tanto, podremos mantener una colección de esos modelos ya entrenados en el disco, o podremos conectar varios al bot a la vez. Nos limitaremos a un solo archivo para mostrar todo con mayor facilidad.
#include En la función, deberemos inicializar los modelos correctamente como se muestra a continuación. Lo más importante es establecer correctamente las dimensiones de los datos de entrada y salida. Nuestros modelos tienen un vector de características de longitud variable, dependiendo del número de características que se especifiquen en la lista PERIODS o en el array exportado, por lo que definiremos la dimensionalidad del vector de entrada como se muestra a continuación. Ambos modelos tomarán el mismo número de características como entrada.
La dimensionalidad del vector de salida podría causar cierta confusión.
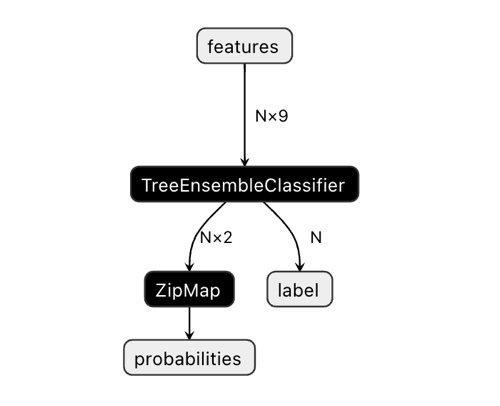

En la aplicación Netron, podemos ver que el modelo tiene dos salidas. La primera es un tensor unitario con etiquetas de clase, que se definirá a continuación en el código como salida cero o salida de índice cero. Pero no puede usarse para obtener predicciones, ya que existen problemas conocidos, como se describe en la documentación de CatBoost:
"The label is inferred incorrectly for binary classification. This is a known bug in the onnxruntime implementation. Ignore the value of this parameter in case of binary classification."
En consecuencia, deberíamos utilizar la segunda salida "probabilities", pero no me las he arreglado para configurarla correctamente en el código MQL, así que simplemente no la definiremos. Sin embargo, se he definido sola y todo funciona. No sé cuál es el motivo.
Por lo tanto, utilizaremos una segunda salida para obtener las probabilidades de las clases en el bot.
const long ExtInputShape [] = {1, ArraySize(Periods)};
int OnInit() { ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); ExtHandle2 = OnnxCreateFromBuffer(ExtModel2, ONNX_DEFAULT); if(ExtHandle == INVALID_HANDLE || ExtHandle2 == INVALID_HANDLE) { Print("OnnxCreateFromBuffer error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetInputShape(ExtHandle, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle); return(-1); } if(!OnnxSetInputShape(ExtHandle2, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle2); return(-1); } const long output_shape[] = {1}; if(!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetOutputShape(ExtHandle2, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); }
Y la recepción de señales modelo se realizará de este modo. Aquí declararemos un array de características y lo rellenaremos usando la función fill_arrays(), que se encuentra en el archivo .mqh exportado.
A continuación, declararemos otro array f para invertir el orden de los valores del array features, y lo enviaremos a Onnx Runtime para su ejecución. La primera salida como vector debería transmitirse sin más, pero no la usaremos. Entre tanto, transmitiremos un array de estructuras como segunda salida.
Los modelos (principal y meta) se ejecutarán y retornarán los valores predichos al array tensor. Nosotros tomaremos de ellos las probabilidades de la segunda clase.
void OnTick() { if(!isNewBar()) return; double features[]; fill_arays(features); double f[ArraySize(Periods)]; int k = ArraySize(Periods) - 1; for(int i = 0; i < ArraySize(Periods); i++) { f[i] = features[i]; k--; } static vector out(1), out_meta(1); struct output { long label[]; float tensor[]; }; output out2[], out2_meta[]; OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, out, out2); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f, out_meta, out2_meta); double sig = out2[0].tensor[1]; double meta_sig = out2_meta[0].tensor[1];
El resto del código del bot debería resultarle familiar del artículo anterior. Allí comprobaremos la señal de permiso meta_sig. Si es superior a 0,5, entonces dará el visto bueno para abrir y cerrar operaciones, según la dirección dada por la señal sig del primer modelo.
if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } } if(meta_sig > 0.5) if(countOrders() < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(meta_sig), ORDER_TYPE_BUY)) { double l = LotsOptimized(meta_sig); if(sig < 0.5) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = OrderSend(Symbol(), OP_BUY, l, Ask, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } else { if(sig > 0.5) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = OrderSend(Symbol(), OP_SELL, l, Bid, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } } }
Pruebas finales
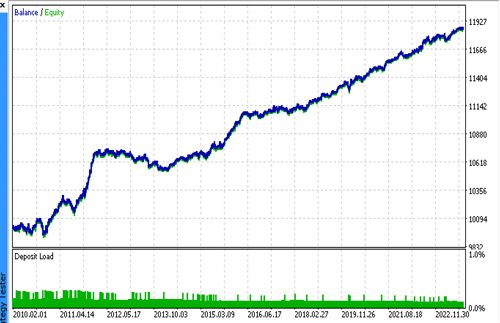
Conectaremos sucesivamente 2 archivos con los modelos que nos gusten y nos aseguraremos de que los resultados del simulador personalizado coincidan plenamente con los resultados del simulador de MetaTrader 5.
Además, en el optimizador de MetaTrader 5 podemos probar los bots con ticks reales, optimizar los stop loss y take profit, seleccionar el tamaño del lote y añadir más operaciones.
Una última palabra
No sé si este enfoque de la clasificación de las series temporales con fines comerciales tiene una base científica. Se ha creado por ensayo y error y, a nuestro juicio, parece bastante interesante y prometedor.
Con este pequeño estudio, queríamos subrayar que a veces los modelos de aprendizaje automático deben entrenarse de una forma distinta a la que parece obvia. No es la elección de una arquitectura concreta lo que desempeña un gran papel (que también es importante, por supuesto), sino la forma en que se aplican estos modelos. Al mismo tiempo, se impone un enfoque estadístico para analizar los resultados del aprendizaje, ya sea la semblanza totalmente automatizada de "tráder e investigador" que presentamos en este artículo, o algoritmos más sencillos que requieran la intervención experta de un "Maestro".
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11147
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso