
Redes neuronales: así de sencillo (Parte 61): El problema del optimismo en el aprendizaje por refuerzo offline

Introducción
Recientemente se han generalizado los métodos de aprendizaje por refuerzo offline, que prometen muchas perspectivas en la resolución de problemas de diversa complejidad. No obstante, uno de los principales retos a los que se enfrentan los investigadores es el optimismo que puede surgir en el proceso de aprendizaje. El Agente optimiza su estrategia basándose en los datos de la muestra de entrenamiento y gana confianza en sus acciones, pero la muestra de entrenamiento no suele cubrir toda la variedad de estados y transiciones posibles del entorno. Dada la estocasticidad del entorno, dicha confianza resulta no ser del todo razonable. En tales casos, la estrategia optimista de un agente puede provocar mayores riesgos y consecuencias indeseables.
En busca de una solución a este problema, merece la pena analizar la investigación sobre conducción autónoma. Obviamente, los algoritmos de esta área de investigación tienen como meta la reducción de riesgos (aumentar la seguridad del usuario) y un aprendizaje en línea mínimo. Uno de estos métodos es el SeParated Latent Trajectory Transformer (SPLT-Transformer), presentado en el artículo «Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning» (julio de 2022).
1. El método SPLT-Transformer
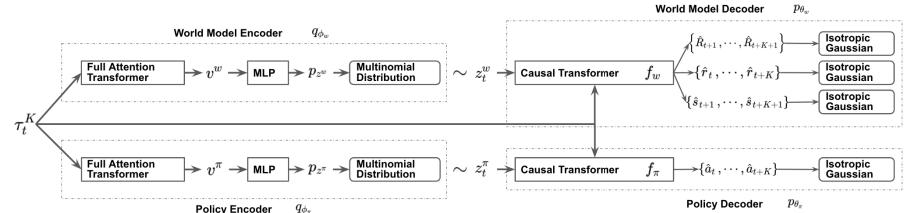
El modelo SPLT-Transformer, similar al Decision Transformer, se refiere a los modelos de generación de secuencias que utilizan la arquitectura Transformer. Pero a diferencia del DT mencionado, utiliza dos flujos de información separados para modelar la política del Actor y el modelo del entorno.
Los autores del método tratan de resolver 2 problemas principales:
- Los modelos deben facilitar la creación de una variedad de candidatos para el comportamiento del Agente en cualquier situación;
- Los modelos deben cubrir la mayoría de los distintos modos de transiciones potenciales a un nuevo estado del entorno.
Para lograr este objetivo, se entrenan 2 VAE basados en el Transformer para los modelos de política y entorno del Actor. Los autores del método generan variables latentes estocásticas para ambos flujos y las usan durante todo el horizonte de planificación, lo que permite enumerar todas las posibles trayectorias candidatas sin aumentar exponencialmente la ramificación y proporciona una búsqueda eficaz de opciones de comportamiento durante las pruebas.
La idea es que las variables políticas latentes correspondan a diferentes intenciones de alto nivel, de forma similar a las habilidades de los algoritmos jerárquicos. Al mismo tiempo, las variables latentes del modelo del entorno deben corresponder a las diversas tendencias posibles y al cambio más probable de su estado.
Los codificadores de la política y del entorno utilizan la misma arquitectura mediante Transformadores. Obtienen los mismos datos de entrada en forma de trayectoria previa, pero a diferencia de los algoritmos anteriores, la trayectoria solo incluye el conjunto de estados y acciones del Actor. Las salidas del codificador son variables latentes discretas con un número limitado de valores en cada dimensión.
Los autores del método proponen usar la media de las salidas del transformador de todos los elementos para combinar toda la trayectoria en una única representación vectorial.
A continuación, cada una de estas salidas es procesada por un pequeño perceptrón multicapa que muestra distribuciones categóricas independientes de la representación latente.
El descodificador de la política recibe a la entrada la misma trayectoria original aumentada con la representación latente correspondiente. El objetivo del decodificador de la política es estimar las probabilidades y predecir la siguiente acción más probable en la trayectoria. Los autores del método presentan un descodificador que usa el modelo de Transformer.
Como ya hemos dicho, excluimos la recompensa de la secuencia, pero añadimos una representación latente. Sin embargo, la representación latente no sustituye a la recompensa como elemento de la secuencia en cada paso. Los autores del método introducen una representación latente que se transforma usando un único vector de incorporación, similar a la codificación posicional utilizada en algunos otros trabajos que emplean la arquitectura de Transformer.
El descodificador del modelo del entorno tiene una arquitectura similar a la del descodificador de la política, solo que la salida del decodificador del modelo del entorno tiene "3 cabezas" para predecir el estado posterior más probable y su coste, así como la recompensa por la transición.
Los modelos se entrenan, como en el DT, con los datos de la muestra de entrenamiento utilizando técnicas de aprendizaje supervisado. Los modelos se entrenan para asignar las trayectorias a las acciones posteriores (Actor), las transiciones a los nuevos estados y sus costes (modelo del entorno).
Durante las pruebas y el funcionamiento, la acción óptima se selecciona según la evaluación de las trayectorias predictivas candidatas en un horizonte de planificación determinado. Luego se realiza una generación secuencial de acciones y estados con recompensas a lo largo del horizonte de planificación para componer una única trayectoria candidata planificada. A continuación, se selecciona la trayectoria óptima y se realiza su primera acción. Tras la transición al nuevo estado del entorno, se repetirá todo el algoritmo.
Como podemos ver, el algoritmo implica la planificación de múltiples trayectorias candidatas, pero solo se realiza una acción de la trayectoria óptima. Aunque este planteamiento podría no parecer eficiente, minimiza el riesgo al planificar varios pasos por adelantado. Al mismo tiempo, existe la posibilidad de ajustar la trayectoria en el tiempo como consecuencia de reevaluar cada estado visitado.
A continuación le presentamos la visualización del método por parte del autor.
2. Implementación usando MQL5
Tras considerar los aspectos teóricos del método SPLT-Transformer, vamos a comenzar la implementación de los enfoques propuestos mediante MQL5. Me gustaría decir de entrada que nuestra aplicación estará más lejos que nunca del algoritmo del autor, y la razón es mi percepción subjetiva. Toda la experiencia de esta serie de artículos demuestra la dificultad de crear un modelo del entorno para los mercados financieros. Todos nuestros intentos han dado resultados más bien modestos. La precisión de las predicciones resulta bastante baja en 1-2 pasos. Y a medida que aumenta el horizonte de planificación, tiende a 0. Por lo tanto, hemos decidido no construir trayectorias candidatas, sino limitarnos a generar algunas variantes de acción candidatas a partir del estado actual.
Pero este enfoque implica una desconexión entre la acción y su evaluación. Como podemos ver en la visualización anterior, la política de Actor y el modelo del entorno reciben los mismos datos de entrada, pero la información adicional llega en flujos paralelos. Como consecuencia, al predecir el estado posterior y la recompensa esperada, el modelo del entorno no sabe nada sobre la acción que elegirá el Agente. Aquí solo podemos hablar de alguna suposición con cierto grado de probabilidad basada en la experiencia previa de la muestra de entrenamiento. Y debemos señalar que la muestra de entrenamiento se ha creado sobre la base de políticas de Actor distintas a la utilizada actualmente.
En la versión del autor, esto se equilibra añadiendo la acción del Agente y el estado previsto a la trayectoria en el siguiente paso. No obstante, en nuestro caso, dada nuestra experiencia con la mala calidad en la planificación del entorno posterior, corremos el riesgo de añadir a la trayectoria estados y acciones completamente descoordinados, lo que provocará una reducción aún mayor de la calidad de la planificación de los siguientes pasos de la trayectoria predictiva. A mi juicio, la eficacia de semejante planificación y la evaluación de tales trayectorias resulta muy cuestionable. Por lo tanto, no malgastaremos recursos en predecir las trayectorias candidatas.
Al mismo tiempo, necesitaremos un mecanismo capaz de hacer coincidir las acciones del Agente con la recompensa esperada. Por un lado, podemos usar el modelo del Crítico, pero esto romperá fundamentalmente el algoritmo y eliminará por completo el modelo del entorno. A menos, por supuesto, que lo usemos como Crítico.
Sin embargo, hemos decidido experimentar con un enfoque diferente que se acerca más al algoritmo original. Para empezar, hemos decidido utilizar un codificador para ambos flujos. El estado latente resultante se añade a la trayectoria y se introduce en la entrada de dos descodificadores. El actor genera una acción predictiva basada en los datos de entrada, y el modelo del entorno devuelve la cantidad de recompensa futura descontada.
La idea es que, al recibir los mismos datos como entrada, los modelos arrojen resultados coherentes. Para ello, excluimos la estocasticidad en los modelos de Actor y el modelo del entorno. Al hacerlo, creamos estocasticidad en la representación latente, lo cual nos permite crear múltiples acciones candidatas y estimaciones predictivas de estado vinculadas. Basándonos en estas puntuaciones, clasificaremos las acciones candidatas para seleccionar el paso ponderado óptimo.
Para optimizar el número de operaciones a efectuar, debemos considerar otro punto. Suministrando la misma trayectoria a la entrada del Codificador repetiremos los resultados de todas sus capas internas con precisión matemática. Las diferencias solo se forman en la capa del autocodificador variacional cuando se muestrea a partir de una distribución determinada. Por ello, para formar las acciones candidatas, será razonable que traslademos dicha capa fuera del Codificador. Esto nos permitirá hacer una sola pasada del codificador en cada iteración. Tras pensarlo brevemente, hemos trasladado la capa del autocodificador variacional al modelo del entorno.
Debemos decir que hemos ido más allá en el camino de la optimización del flujo de operaciones. Los tres modelos utilizan una única trayectoria como entrada. Como ya sabe, los elementos de la trayectoria no son homogéneos, y pasan por una capa de incorporación antes de procesarse. Esto nos dio la idea de incorporar los datos en un solo modelo y luego utilizar los datos resultantes en los dos modelos restantes. Así que hemos dejado la capa de incorporación solo en el Codificador.
Una cosa más: El modelo del entorno y el Actor han usado como entradas el vector de trayectoria concatenado y la representación latente. Más arriba, ya hemos determinado que la capa del autocodificador variacional para formar la representación latente estocástica se transfiere al modelo del entorno. Aquí también realizaremos la unión de los vectores, y pasaremos el resultado ya obtenido a la entrada del Actor.
Ahora vamos a traducir las ideas presentadas a código. Así, crearemos una descripción de nuestros modelos, que, como siempre, se generará en el método CreateDescriptions. En los parámetros, el método obtiene los punteros a los tres objetos de descripción de nuestros modelos.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *latent, CArrayObj *world) { //--- CLayerDescription *descr;
La descripción de la arquitectura probablemente debería comenzar con el modelo de codificador, que introduce datos de secuencia sin procesar.
//--- latent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Luego pasamos los datos resultantes por una capa de normalización por lotes para que sean comparables.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Y pasamos los datos ya normalizados por la capa de incorporación. Recuerde esta capa. Partiendo de ahí, introducimos los datos en el modelo del entorno.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!latent.Add(descr)) { delete descr; return false; }
A continuación, trazamos la trayectoria resultante a través del bloque del Transformador. Hemos utilizado un bloque de atención dispersa con 8 cabezas de autoatención y 4 capas en el bloque.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = prev_wout; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Tras el bloque de atención, redimensionaremos ligeramente la capa de convolución y pasaremos los datos por un bloque de decisión de capas totalmente conectadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
En la salida del modelo codificador, usaremos una capa neuronal totalmente conectada sin función de activación y con un tamaño dos veces superior al tamaño de la incorporación de un único elemento de trayectoria, lo cual representa los valores medios y la varianza de la distribución de la representación latente. Esto nos permitirá muestrear la representación latente a partir de una distribución dada en el siguiente paso.
A continuación, pasamos a la descripción del modelo del entorno. Su capa de datos de entrada es igual a la capa de resultados del modelo Encoder. Y a esto le sigue una capa de autocodificador variacional, que nos permite muestrear inmediatamente la representación latente.
//--- World if(!world) { world = new CArrayObj(); if(!world) return false; } //--- world.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; prev_count = descr.count = prev_count / 2; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
A continuación, debemos añadir el tensor de incorporación de la trayectoria. Para ello, utilizaremos la capa de concatenación. La salida de esta capa nos ofrece los datos de entrada procesados para nuestro modelo del entorno y el Actor.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.step = 4 * EmbeddingSize * HistoryBars; prev_count = descr.count = descr.step + prev_count; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Vamos a pasar los datos por el bloque de autoatención descargado. Como en el codificador, utilizamos 8 cabezas y 4 capas.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Luego reducimos la dimensionalidad de los datos usando la capa de convolución.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; }
Y procesamos los datos obtenidos mediante el perceptrón completamente conectado del bloque de decisión.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
En la salida del modelo, obtendremos un vector de recompensas descompuestas.
Y al final de este bloque, veremos la estructura de nuestro modelo Actor. Como ya hemos mencionado, el modelo obtiene sus datos de entrada a partir del estado latente del modelo del entorno. En consecuencia, la capa de datos de origen deberá tener un tamaño suficiente.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = EmbeddingSize * (4 * HistoryBars + 1); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Los datos obtenidos serán el resultado del modelo y no requerirán tratamiento adicional. Por eso utilizamos enseguida el bloque de atención dispersa. Los parámetros de los bloques son similares a los usados en los modelos comentados anteriormente. Así que los tres modelos utilizan la misma arquitectura del transformador.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Al igual que en el modelo del entorno, redimensionamos y procesamos los datos en un perceptrón de decisión totalmente conectado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
La salida del modelo genera un vector de acciones del Agente.
Aquí también debemos señalar que para implementar este método, necesitaremos añadir una entidad adicional al búfer de reproducción de experiencias en forma de distribución de la representación latente generada a la salida del Codificador. Para ello, crearemos un array adicional en la estructura de descripción del estado del entorno.
struct SState { ....... ....... float latent[2 * EmbeddingSize]; ....... ....... }
El tamaño del nuevo array es de dos incorporaciones porque incluye los valores medios y la varianza de la distribución.
Además de declarar un array, también deberemos añadir su mantenimiento a todos los métodos de la estructura:
- Inicializar con valores iniciales
SState::SState(void) { ....... ....... ArrayInitialize(latent, 0); }
- Limpiar una estructura
void Clear(void) { ....... ....... ArrayInitialize(latent, 0); }
- Copiar una estructura
void operator=(const SState &obj) { ....... ....... ArrayCopy(latent, obj.latent); }
- Almacenar una estructura
bool SState::Save(int file_handle) { ....... ....... //--- total = ArraySize(latent); if(FileWriteInteger(file_handle, total) < sizeof(int)) return false; for(int i = 0; i < total; i++) if(FileWriteFloat(file_handle, latent[i]) < sizeof(float)) return false; //--- return true; }
- Cargar una estructura desde un archivo
bool SState::Load(int file_handle) { ....... ....... //--- total = FileReadInteger(file_handle); if(total != ArraySize(latent)) return false; //--- for(int i = 0; i < total; i++) { if(FileIsEnding(file_handle)) return false; latent[i] = FileReadFloat(file_handle); } //--- return true; }
Ya nos hemos familiarizado con la arquitectura de los modelos entrenados y hemos actualizado la estructura de datos. El siguiente paso será recopilar los datos para entrenarlos. Esta funcionalidad está implementada en el asesor "...\SPLT\Research.mq5". Y debemos señalar inmediatamente que el método SPLT-Transformer prevé la generación de trayectorias candidatas (en nuestra implementación, son acciones candidatas). El número de dichos candidatos es uno de los hiperparámetros del modelo que introduciremos en los parámetros externos del asesor.
input int Agents = 5;
Pero permítanme recordarles que antes usábamos el parámetro externo "Agentes" como parámetro auxiliar para especificar el número de agentes de exploración del entorno concurrentes en el modo de optimización del simulador de estrategias. Ahora cambiaremos el nombre del parámetro de servicio del asesor.
input int OptimizationAgents = 1;
En lo sucesivo, no nos extenderemos sobre todos los métodos del asesor para recoger la muestra de entrenamiento. Ya hemos descrito muchas veces su algoritmo en esta serie de artículos. Así que podrá ver el código completo de todos los programas utilizados en el artículo en el archivo adjunto. Vamos a analizar solo el método de interacción directa con el entorno OnTick en el que se implementan las características clave del algoritmo implementado.
Al principio del método, como de costumbre, comprobaremos la aparición del evento de apertura de una nueva barra y, de ser necesario, actualizaremos los datos históricos del movimiento del precio y los valores de los indicadores analizados.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A continuación, generamos un búfer de datos de origen para los modelos. En primer lugar, introduciremos datos históricos sobre los movimientos de los precios y los valores de los indicadores analizados.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates(); //--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Luego añadiremos el estado actual de la cuenta y la información sobre las posiciones abiertas.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
A continuación, realizaremos la identificación temporal de los datos añadiendo una marca temporal a nuestro búfer de datos.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
E indicaremos las últimas acciones del Agente que nos han inculcado esta condición del entorno.
//--- Prev action
bState.AddArray(AgentResult);
Los datos recogidos sobre el paso actual bastarán para generar la representación latente, así que llamaremos al método de pasada directa del Codificador. Al mismo tiempo, nos aseguraremos de controlar el proceso de las operaciones. Y, de ser necesario, informaremos al usuario.
//--- Latent representation ResetLastError(); if(!Latent.feedForward(GetPointer(bState), 1, false)) { PrintFormat("Error of Latent model feed forward: %d",GetLastError()); return; }
Tras crear con éxito una representación latente, pasaremos a nuestros descodificadores.
Recordemos que en esta fase deberemos generar acciones candidatas. Las entrenaremos en un ciclo cuyo número de iteraciones sea igual al número de candidatos necesarios y se especifique en los parámetros externos del asesor.
Para registrar la información sobre las acciones candidatas generadas, crearemos dos arrays: actions y values. En la primera escribiremos los vectores de acción. El segundo será la recompensa esperada de la política.
Como ya hemos mencionado, en el modelo del codificador solo generamos datos sobre la distribución de la representación latente. El vector de representación latente se muestrea en el modelo del entorno, así que, en el cuerpo del ciclo, primero realizaremos una pasada directa del modelo del entorno. Y luego llamaremos al método de pasada directa del Agente, que utilizará los estados ocultos del modelo del entorno como entrada.
Después guardaremos los resultados de las pasadas directas del modelo en las matrices previamente preparadas.
matrix<float> actions = matrix<float>::Zeros(Agents, NActions); matrix<float> values = matrix<float>::Zeros(Agents, NRewards); for(ulong i = 0; i < (ulong)Agents; i++) { if(!World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer) || !Agent.feedForward(GetPointer(World), 2,(CBufferFloat *)NULL)) return; vector<float> result; Agent.getResults(result); actions.Row(result, i); World.getResults(result); values.Row(result, i); }
El uso de políticas estocásticas se basa en el supuesto de que existe una probabilidad igual de que ocurra uno de los sucesos dentro de la distribución aprendida. Como consecuencia, cada acción candidata muestreada tendrá la misma probabilidad de recibir la recompensa esperada en el entorno. Nuestro objetivo será maximizar la rentabilidad. Por tanto, en condiciones de igual probabilidad, elegiremos la acción con mayor rendimiento esperado.
Como comprenderá, nuestras matrices están correlacionadas fila por fila. Así que buscaremos la fila con la máxima recompensa esperada en la matriz de values y seleccionaremos una acción de la fila correspondiente de la matriz actions.
vector<float> temp = values.Sum(1); temp = actions.Row(temp.ArgMax());
La acción seleccionada se realizará en el entorno,
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
mientras que los resultados de la interacción con el entorno se recogerán en una estructura previamente preparada y se almacenarán en el búfer de reproducción de experiencias.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; Latent.getResults(sState.latent); if(!Base.Add(sState)) ExpertRemove(); }
Con esto concluye nuestra introducción al asesor de interacción con el entorno y recopilación de datos para la muestra de entrenamiento. Podrá ver su código completo en el archivo adjunto. También podrá encontrar allí el código completo de todos los programas utilizados en el artículo. Vamos a trabajar ahora en el asesor de entrenamiento offline de modelos "...\SPLT\Study.mq5".
En el método de inicialización asesor, primero cargaremos la muestra de entrenamiento. Y nos aseguraremos de supervisar el proceso de las operaciones. Para el entrenamiento offline de modelos, esta será la única fuente de datos y su ausencia imposibilitará el resto del proceso.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
A continuación, intentaremos cargar los modelos preentrenados. Y, de ser necesario, crearemos otros nuevos.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !World.Load(FileName + "Wld.nnw", temp, temp, temp, dtStudied, true) || !Latent.Load(FileName + "Lat.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *latent = new CArrayObj(); CArrayObj *world = new CArrayObj(); if(!CreateDescriptions(agent, latent, world)) { delete agent; delete latent; delete world; return INIT_FAILED; } if(!Agent.Create(agent) || !World.Create(world) || !Latent.Create(latent)) { delete agent; delete latent; delete world; return INIT_FAILED; } delete agent; delete latent; delete world; //--- }
Como habrá observado en el algoritmo del asesor para la recopilación de muestras de entrenamiento, a menudo se utiliza la transferencia de datos entre modelos entrenados. Durante el proceso de entrenamiento, la cantidad de datos transferidos aumenta, ya que el flujo de datos se produce en dos direcciones: con la pasadas directa e inversa. Para eliminar operaciones innecesarias de copiado de datos entre el contexto OpenCL y la memoria principal, desplazaremos todos los modelos a un único contexto OpenCL.
COpenCL *opcl = Agent.GetOpenCL(); Latent.SetOpenCL(opcl); World.SetOpenCL(opcl);
A continuación, comprobaremos la coherencia de la arquitectura de los modelos entrenados.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Agent does not match the actions count (%d <> %d)", 6, Result.Total()); return INIT_FAILED; } //--- Latent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Latent model doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Latent.Clear();
Después de transmitir con éxito todos los controles, generaremos el evento de inicio de entrenamiento del modelo y finalizaremos el método de inicialización del asesor.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
El proceso de entrenamiento del modelo se organizará directamente en el método Train. En el cuerpo del método, definiremos el número de trayectorias en el búfer de repetición de experiencias y fijaremos la hora de inicio del proceso de entrenamiento en una variable local. Nos servirá como punto de referencia para informar periódicamente al usuario sobre el progreso del proceso de entrenamiento del modelo.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Recordemos que nuestros modelos usan la arquitectura GPT, que es sensible a la secuencia de los datos de origen. Como en otros casos similares, usaremos un sistema de ciclos anidados para entrenar los modelos. En el ciclo externo, tomaremos una muestra de la trayectoria a partir del búfer de repetición de experiencias y del estado inicial del entorno.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
A continuación, inicializaremos los búferes del modelo y crearemos un ciclo anidado en el que suministraremos secuencialmente un fragmento aparte de datos históricos a la entrada del modelo.
Actions = vector<float>::Zeros(NActions); Latent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) {
En el cuerpo del ciclo anidado, las operaciones pueden parecerse en parte a la recopilación de los datos de entrenamiento. También rellenaremos el búfer de datos de origen del mismo modo. Solo que ahora no estamos solicitando datos del entorno, estamos recuperando datos del búfer de reproducción de experiencias. Al hacerlo, respetaremos estrictamente la secuencia de registro de datos. En primer lugar, introduciremos la información sobre los movimientos de precio y los indicadores analizados en el búfer de datos de origen.
//--- History data
State.AssignArray(Buffer[tr].States[state].state);
Luego vendrán los datos sobre el estado de la cuenta y las posiciones abiertas,
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
que se identifican por una marca temporal.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Y por supuesto especificaremos las acciones del Agente que nos han llevado a este estado.
//--- Prev action
State.AddArray(Actions);
Una vez más, querríamos hacer hincapié en el estricto cumplimiento de la secuencia. La cuestión es que los datos del búfer no tienen nombre. El modelo evalúa los datos según su posición en el búfer. Un cambio en la secuencia será percibido por el modelo como un estado completamente diferente. El resultado de la decisión será completamente diferente y no predecible. Por ello, para no confundir el modelo y obtener siempre soluciones adecuadas, deberemos tener clara la coherencia de los datos en todas las fases del entrenamiento y el funcionamiento del modelo.
Tras reunir el búfer de datos de origen, realizaremos primero una pasada directa del codificador y el modelo del entorno.
//--- Latent and Wordl if(!Latent.feedForward(GetPointer(State)) || !World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Tenga en cuenta que no generaremos acciones candidatas durante el entrenamiento. Además, el entrenamiento del modelo del entorno y la política del Actor se realiza por separado. Esto se debe a la especificidad del entrenamiento de los modelos.
El modelo del entorno se entrenará para evaluar la política del Agente partiendo de la trayectoria anterior y predecir la futura adquisición de recompensas dado el estado actual del entorno y la política utilizada. Al mismo tiempo, ajustaremos la distribución de la representación latente. Para ello, después de una pasada directa exitosa, realizaremos una pasada inversa del modelo del entorno y el codificador, con el objetivo de minimizar el error de las predicciones del modelo del entorno y la recompensa real del búfer de repetición de experiencias.
Actions.Assign(Buffer[tr].States[state].rewards); vector<float> result; World.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!World.backProp(Result,GetPointer(Latent),LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL,LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Obsérvese que, tras la pasada inversa del modelo del entorno, primero realizaremos una pasada inversa parcial del codificador para optimizar los parámetros de incorporación según los requisitos del modelo del entorno. A continuación, realizaremos una pasada inversa completa del codificador, durante la cual se optimizará la distribución de la representación latente.
Luego optimizaremos la política del Actor para mapear el estado latente y la acción realizada. Por ello, extraeremos la distribución de la representación latente del búfer de repetición de experiencias y la introduciremos en la entrada del modelo del entorno para volver a muestrear la representación latente. Y realizaremos la pasada directa de los modelos del entorno y el Actor.
//--- Policy Feed Forward Result.AssignArray(Buffer[tr].States[state+1].latent); Latent.GetLayerOutput(LatentLayer,Result2); if(Result2.GetIndex()>=0) Result2.BufferWrite(); if(!World.feedForward(Result, 1, false, Result2) || !Agent.feedForward(GetPointer(World),2,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Después, realizaremos una pasada inversa del Actor para minimizar el error entre la acción predicha y la realizada realmente a partir del búfer de repetición de experiencias.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result,NULL,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
De este modo, entrenaremos la política del Actor y la haremos más predecible. Simultáneamente, entrenaremos un modelo del entorno para estimar trayectorias previas y comprender la oportunidad de beneficio. Entrenaremos al Codificador para que destile las trayectorias entrantes y extraiga información básica sobre las tendencias del entorno y las políticas actuales de los actores.
Todo esto junto da lugar a unas políticas de Actor bastante interesantes, dada la estocasticidad del entorno y las probabilidades de beneficio.
Una vez completadas con éxito las operaciones de actualización del modelo, informaremos al usuario sobre el progreso del proceso de entrenamiento y pasaremos a la siguiente iteración de nuestro sistema de ciclos anidados.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "World", iter * 100.0 / (double)(Iterations), World.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completadas todas las iteraciones del sistema de ciclos, borraremos el campo de comentarios. Luego enviaremos los resultados del entrenamiento del modelo al registro. E inicializaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "World", World.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluye nuestra consideración del asesor de entrenamiento de modelos para nuestra interpretación del método SPLT-Transformer. El código completo del asesor, así como todos los programas utilizados en el artículo, se encuentran en el archivo adjunto. También hallará el código del asesor de prueba de modelos "...\SPLT\Test.mq5". En este artículo no nos detendremos a analizar sus métodos. La estructura del asesor repite los asesores similares de artículos anteriores. Las peculiaridades de la implementación del algoritmo presentado en la función OnTick repiten totalmente la implementación de un método similar en el asesor de recopilación de datos para la muestra de entrenamiento. Le sugiero que se familiarice con este asesor en los archivos adjuntos.
Vamos a pasar a la siguiente etapa: ahora probaremos los modelos con datos históricos en el Simulador de Estrategias de MetaTrader 5.
3. Pruebas
El entrenamiento de los modelos, como antes, lo hemos realizado con datos históricos de los 7 primeros meses del marco temporal H1 de EURUSD. Los parámetros de todos los indicadores se han establecido por defecto sin optimización adicional.
En primer lugar, ejecutaremos el asesor para recopilar una muestra de entrenamiento en el modo de optimización lenta del simulador de estrategias. Esto nos permitirá que múltiples agentes de prueba recopilen datos en paralelo. De este modo, aumentaremos el número de trayectorias en el búfer de repetición de experiencias al tiempo que minimizamos el tiempo dedicado a la recopilación de datos.
El algoritmo analizado supone que los modelos se entrenan únicamente offline. Así que para probar su rendimiento, proponemos maximizar el búfer de repetición de experiencias y rellenarlo con una variedad de trayectorias. Pero hay que considerar que la generación de acciones candidatas es un proceso bastante costoso. Y a medida que aumente el número de candidatos, también lo harán los costes de la recogida de datos.
Tras recopilar los datos, entrenaremos los modelos sin recopilación adicional de trayectorias como se había hecho anteriormente. Entrenar un modelo será, como siempre, un proceso largo. Como no tenía previsto recoger trayectorias adicionales, he aumentado el número de trayectorias y he dejado el ordenador para el entrenamiento a largo plazo.
A continuación, el modelo entrenado se ha probado con los datos históricos de agosto de 2023, que no formaban parte de la muestra de entrenamiento.
Debo decir que según los resultados de las pruebas, el modelo ha mostrado un pequeño beneficio y un comercio bastante preciso. Como recordatorio, el método SPLT-Transformer se desarrolló para la conducción autónoma y está diseñado para maximizar la reducción de riesgos.
En el gráfico de prueba, podemos ver la tendencia de crecimiento del balance prácticamente durante todo el mes. Solo en la última semana del mes se observa una serie de operaciones perdedoras. No obstante, el beneficio acumulado anteriormente ha sido suficiente para cubrir las pérdidas. En general, se ha registrado un pequeño beneficio a final de mes.


Durante todo el periodo de pruebas, el modelo solo ha abierto 16 posiciones con un volumen mínimo. El porcentaje de operaciones rentables es solo del 37,5%. Sin embargo, la media de operaciones rentables es casi un 70% superior a la media de las pérdidas. En consecuencia, los resultados de las pruebas han registrado un factor de beneficio de 1,02.
Conclusión
En este artículo, hemos presentado el SPLT-Transformer, un método novedoso desarrollado para abordar problemas relacionados con el aprendizaje por refuerzo offline vinculados con el comportamiento optimista de los Agentes. Mediante el uso de dos modelos separados que representan la política y el modelo del mundo se consigue la construcción de políticas de Agente robustas y eficientes.
Los componentes básicos del SPLT-Transformer, incluido el algoritmo de generación de trayectorias candidatas, permiten modelizar diversos escenarios y tomar decisiones considerando múltiples resultados futuros posibles. Esto hace que el método presentado resulte altamente adaptable y seguro en diversos entornos estocásticos. Los autores del método proporcionaron resultados experimentales en el campo de la conducción autónoma, que confirman el rendimiento superior del SPLT-Transformer en comparación con los métodos existentes.
En la parte práctica del artículo hemos creado nuestra propia interpretación, ligeramente simplificada, del método analizado. Asimismo, hemos entrenado y probado los modelos resultantes. Los resultados de las pruebas han demostrado que el modelo es capaz de mostrar un comportamiento tanto prudente como optimista en función de la situación. Esto lo convierte en la opción ideal para sistemas de importancia crítica.
En general, el método merece una mayor elaboración. En mi opinión, un entrenamiento más exhaustivo de los modelos puede producir mejores resultados.
Y una vez más les recuerdo que todos los programas presentados en esta serie de artículos se han creado únicamente con fines demostrativos y de prueba para los algoritmos considerados, así que no resultan adecuados para su uso en el comercio en cuentas reales. Antes de utilizar un modelo concreto en operaciones reales, le recomendamos entrenarlo a fondo y someterlo a pruebas exhaustivas.
Enlaces
- Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
- Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer-DT)
- Redes neuronales: así de sencillo (Parte 59): Dicotomía de control (DoC)
- Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer-ODT)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13639
 Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso