Discussione sull’articolo "Growing Neural Gas: Implementazione in MQL5"
Sembra figo :)
Ma cosa sia e come si usi non l'ho ancora capito :)
Sembra figo :)
Ma che cos'è e come usarlo dobbiamo capirlo meglio :)
può essere utilizzato come primo strato nascosto - per la riduzione della dimensionalità o il clustering stesso, può essere utilizzato nelle reti probabilistiche e molte altre opzioni.
Grazie per il materiale!
Cercherò di impararlo con calma :)
Grazie per il nuovo articolo su un interessante metodo di networking. Se si esamina la letteratura, ce ne sono decine, se non centinaia. Ma il problema per i trader non è la mancanza di strumenti, bensì il loro corretto utilizzo. L'articolo sarebbe ancora più interessante se contenesse un esempio di utilizzo di questo metodo in un Expert Advisor.

Grazie per il nuovo articolo su un interessante metodo di networking. Se si esamina la letteratura, ce ne sono decine, se non centinaia. Ma il problema per i trader non è la mancanza di strumenti, bensì il loro corretto utilizzo. L'articolo sarebbe ancora più interessante se contenesse un esempio di utilizzo di questo metodo in un Expert Advisor.
1. L'articolo è buono. È presentato in modo accessibile, il codice non è complicato.
2. Tra gli svantaggi dell'articolo c'è il fatto che non si parla affatto dei dati di input per la rete. Si sarebbe potuto scrivere qualche parola sui dati in ingresso: vettore di quotazioni per il periodo/indicatore, vettore di deviazioni di prezzo, quotazioni normalizzate o altro. Per l'uso pratico dell'algoritmo, la questione dei dati di input e della loro preparazione è fondamentale. Per tali algoritmi consiglio di utilizzare un vettore di variazioni di prezzo relative: x[i]=prezzo[i+1]-prezzo[i].
Inoltre, prima di procedere, il vettore di input può essere normalizzato (x_normal[i]=x[i]/M), per cui si può utilizzare come M la deviazione massima del prezzo per il periodo in esame (qui e di seguito, per brevità, non scrivo le dichiarazioni delle variabili):
M=x[ArrayMaximum(x)]-x[ArrayMinimum(x)];
In questo caso, tutti i vettori di input si troveranno in un ipercubo unitario con lato [-0,5,0,5], il che aumenterà notevolmente la qualità del clustering. È anche possibile utilizzare la deviazione normale standard o qualsiasi altra variabile di media sulle deviazioni relative delle quotazioni nel periodo come M.
3. Il documento suggerisce di utilizzare il quadrato della norma della differenza come distanza tra il vettore dei pesi dei neuroni e il vettore di input:
for(i=0, sum=0; i<m; i++, sum+=Pow(x[i]-w[i],2));
A mio parere, questa funzione di distanza non è efficace in questo compito di clustering. Più efficace è la funzione che calcola il prodotto scalare o il prodotto scalare normalizzato, cioè il coseno dell'angolo tra il vettore dei pesi e il vettore di input:
for(i=0, norma_x=0, norma_w=0; i<m; i++, norma_x+=x[i]*x[i], norma_w+=w[i]*w[i]); norma_x=sqrt(norma_x); norma_w=sqrt(norma_w); for(i=0, sum=0; i<m; i++, sum+=x[i]*w[i]); if(norma_x*norma_w!=0) sum=sum/(norma_x*norma_w);
In questo modo, in ogni cluster verranno raggruppati vettori simili tra loro per le direzioni delle oscillazioni, ma non per l'entità di queste oscillazioni, il che ridurrà significativamente la dimensionalità del problema da risolvere e aumenterà le caratteristiche delle distribuzioni dei pesi della rete neurale addestrata.
4.È stato correttamente osservato che è necessario definire un criterio di arresto per l'addestramento della rete. Il criterio di arresto deve determinare il numero necessario di cluster della rete addestrata. E questo numero dipende a sua volta dal problema generale da risolvere. Se il compito è quello di prevedere una serie temporale per 1-2 campioni in anticipo e a questo scopo, ad esempio, si utilizzerà un perseptron multistrato, allora il numero di cluster non dovrebbe differire molto dal numero di neuroni dello strato di ingresso del perseptron.

In generale, il numero di barre della storia non supera i 5.300.000 sul grafico a minuti più dettagliato (10 anni*365 giorni*24 ore*60 minuti). Sul grafico orario è di 87.000 barre. In altre parole, la creazione di un classificatore con un numero di cluster superiore a 10000-20000 non è giustificata a causa dell'effetto "overtraining", quando ogni vettore di quotazioni ha un proprio cluster separato.
Mi scuso per eventuali errori.
1. Grazie, ho fatto del mio meglio per voi:)
2. Sì, sono d'accordo. Ma ancora gli ingressi - questo è un grande problema separato, su cui da solo si possono scrivere decine di articoli.
3. E qui sono completamente in disaccordo. Nel caso di input normalizzati, il confronto dei prodotti scalari è equivalente al confronto delle norme euclidee - espandi le formule.
4. Poiché il numero massimo di cluster è già uno dei parametri dell'algoritmo.
max_nodes
Procederei, ad esempio, nel modo seguente: misurare l'errore del vincitore agli ultimi N passi e valutarne la dinamica in qualche modo (ad esempio, misurare la pendenza della retta di regressione) Se l'errore cambia poco, fermarsi. Se l'errore continua a diminuire e i dati di addestramento sono già esauriti, allora vale la pena di considerare il loro smussamento per sopprimere il rumore o eliminare in qualche modo il deficit di esempi.
3. Non capisco dove sia l'equivalenza delle formule. La formula per il coseno dell'angolo tra i vettori(x,w)/ (|x||w|) non è "molto" simile a |x-w|^2. La normalizzazione degli input non cambia le differenze fondamentali tra queste misure:
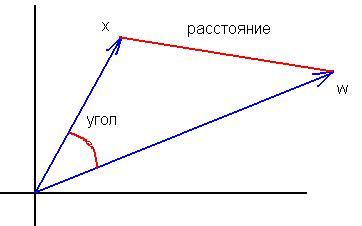
L'equivalenza è che il massimo della distanza corrisponde sempre al minimo del prodotto scalare e viceversa. La relazione nel caso di vettori normalizzati è reciprocamente univoca e monotona, quindi non importa se si calcola il quadrato della distanza o dell'angolo.
Ciao Alex,
Grazie per la chiara spiegazione dell'argomento.
Sarebbe possibile condividere qualche codice pratico per la ricostruzione del prezzo futuro, ad esempio a partire da segnali ottimali.
L'idea è che:
1. Input (Fonte): più valute (18)
2. Destinazione: Segnale ottimale della valuta che si desidera prevedere (immagine: 2. Optimal_Signals).
3. Trovare una neuro-connessione tra Sorgente e Destinazione e farla esplodere nel trading.

Un'altra domanda sulla ricostruzione NN:
È possibile utilizzare i nostri campioni al posto dei campioni casuali, come nella figura 2?
Il nostro cervello può ricostruire l'immagine in meno di un secondo, vediamo quanto tempo impiega la NN a fare lo stesso, è solo una battuta, non è una sfida.

I campioni generati a caso non sono molto interessanti da vedere perché non c'è alcun significato dietro o utilizzo, ma se potessimo disegnare noi stessi dei punti con un qualche significato dietro, sarebbe molto più divertente. :-0)

- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Il nuovo articolo Growing Neural Gas: Implementazione in MQL5 è stato pubblicato:
L'articolo mostra un esempio di come sviluppare un programma MQL5 che implementa l'algoritmo adattivo di clustering chiamato Growing neural gas (GNG). L'articolo è destinato agli utenti che hanno studiato la documentazione linguistica e hanno determinate capacità di programmazione e conoscenze di base nell'area della neuro informatica.
Quando si programma l'algoritmo dovremo ovviamente fare i conti con la necessità di memorizzare quelli che vengono chiamati "set". Avremo due insiemi: un insieme di neuroni e un insieme di bordi tra di loro. Mentre entrambe le strutture si evolveranno nel corso del programma (e stiamo pianificando sia di aggiungere che di rimuovere elementi), dovremmo anche fornire meccanismi per questo.
Naturalmente, potremmo provare a utilizzare array dinamici di oggetti, ma dovremmo eseguire numerose operazioni di copia-spostamento dei dati, che essenzialmente rallenterebbero il programma. Un'opzione più adatta per lavorare con le astrazioni con le proprietà specificate sono i grafici del programma e la loro versione più semplice: un elenco collegato.
Ricorderò ai nostri lettori il principio di funzionamento della lista collegata (Fig. 1). Gli oggetti della classe base contengono un puntatore allo stesso oggetto di uno dei membri, che consente di combinarli in strutture lineari, indipendentemente dall'ordine fisico degli oggetti in memoria. Inoltre, c'è la classe "carriage", che incapsula la procedura di spostamento attraverso l'elenco, l'aggiunta, l'inserimento e l'eliminazione di nodi, la ricerca, il confronto e l'ordinamento e, se necessario, altre procedure.
Autore: Alexey Subbotin