Redes neurais de maneira fácil (Parte 13): normalização em lote
Dmitriy Gizlyk | 14 junho, 2021
Sumário
- Introdução
- 1. Contextualização teórica da normalização
- 2. Implementação
- 2.1. Criamos uma nova classe para nosso modelo
- 2.2. Passagem para frente
- 2.3. Passagem para atrás
- 2.4. Mudanças pontuais nas classes base da rede neural
- 3. Teste
- Fim do artigo
- Links
- Programas usados no artigo
Introdução
No artigo anterior, começamos a examinar métodos para aumentar a convergência de redes neurais durante o treinamento, e nos familiarizamos com Dropout, que é usado para reduzir a adaptação conjunta de recursos. Neste artigo, proponho continuar este tópico e apresentar os métodos de normalização.
1. Contextualização teórica da normalização
A prática da utilização de redes neurais aplica diferentes abordagens à normalização de dados. Mas todas elas visam manter os dados da amostra de treinamento e os dados de saída das camadas ocultas da rede neural dentro de um determinado intervalo e com certas características estatísticas da amostra, tais como variância e mediana. Por que isso é tão importante se, afinal, lembramos que os neurônios da rede aplicam transformações lineares, que no processo de treinamento deslocam a amostra para o antigradiente?
Consideremos um perceptron totalmente conectado com 2 camadas ocultas. Durante a passagem para frente, cada camada gera um determinado conjunto de dados que serve como uma amostra de treinamento para a próxima camada. O resultado da camada de saída é comparado com os dados de referência, enquanto o gradiente de erro desde a camada de saída através das camadas ocultas até os dados de origem é propagado na passagem para atrás. Dado um gradiente de erro diferente em cada neurônio, atualizamos os coeficientes de peso ajustando nossa rede neural às amostras de treinamento da última passagem para frente. E aqui surge um conflito: ajustamos a segunda camada oculta (H2 na figura abaixo) para a amostra de dados na saída da primeira camada oculta (na figura H1), enquanto já alteramos a matriz de dados alterando os parâmetros da primeira camada oculta. ajustamos a segunda camada oculta a uma amostra de dados que ainda não existe. A situação é semelhante com a camada de saída, que se ajusta à saída já modificada da segunda camada oculta. E se considerarmos também a distorção entre a primeira e a segunda camada oculta, a escala do erro aumenta. E quanto mais profunda for a rede neural, mais forte será a manifestação deste efeito. Este fenômeno tem sido denominado de mudança de covariância interna.
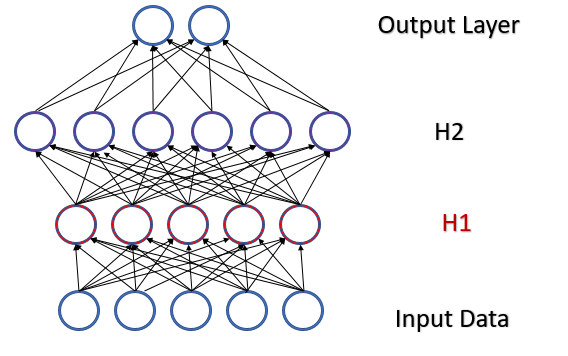
Nas redes neurais clássicas, esse problema foi parcialmente resolvido pela redução da taxa de aprendizado. Pequenas mudanças nos coeficientes de peso não alteram significativamente a distribuição da amostragem na saída da camada neural. Mas essa abordagem não resolve o problema de dimensionamento com um aumento no número de camadas da rede neural e reduz a taxa de aprendizado. Outro problema de uma pequena taxa de aprendizado é ficar preso em mínimos locais, já falamos sobre isso no artigo [6]
Em fevereiro de 2015, Sergey Ioffe e Christian Szegedy propuseram um método de normalização em lote para resolver o problema de mudança interna de covariância [13]. A essência do método era normalizar cada neurônio individual em algum intervalo de tempo com uma mudança da mediana da amostra para zero e trazer a variância da amostra para 1.
O algoritmo de normalização é o seguinte. Primeiro, o valor médio é calculado a partir de uma amostra de dados.
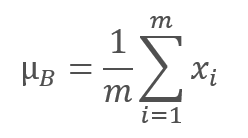
onde m é o tamanho da amostra (batch).
Em seguida, calculamos a variância da amostra original.
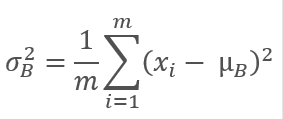
E normalizamos os dados da amostra, levando a amostra à média zero e à variância unitária.
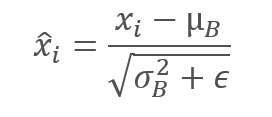
Observe que uma constante ϵ, um pequeno número positivo, é adicionado à variância da amostra no denominador para eliminar a divisão por zero.
Mas, como se verificou, tal normalização pode distorcer o efeito dos dados de origem. Portanto, os autores do método adicionaram mais uma etapa - dimensionamento e deslocamento. 2 variáveis γ e β foram introduzidas e treinadas junto com a rede neural pelo método de descida de gradiente inversa.
![]()
A aplicação deste método permite obter uma amostra de dados com a mesma distribuição em cada etapa do treinamento, o que na prática torna o treinamento da rede neural mais estável e permite aumentar a taxa de aprendizado. Em geral, isto melhorará a qualidade do aprendizado com menos tempo de treinamento gasto na rede neural.
Mas, ao mesmo tempo, o custo de armazenamento de coeficientes adicionais aumenta. E o cálculo da média móvel e da variância também requer o armazenamento de dados históricos de cada neurônio na memória para todo o tamanho do lote. E aqui podemos olhar para a média exponencial. A figura abaixo mostra claramente os gráficos da média móvel e da variância móvel para 100 elementos em comparação com a média móvel exponencial e a variância móvel exponencial para os mesmos 100 elementos. O gráfico foi traçado para 1000 itens aleatórios da faixa de -1,0 a 1,0.
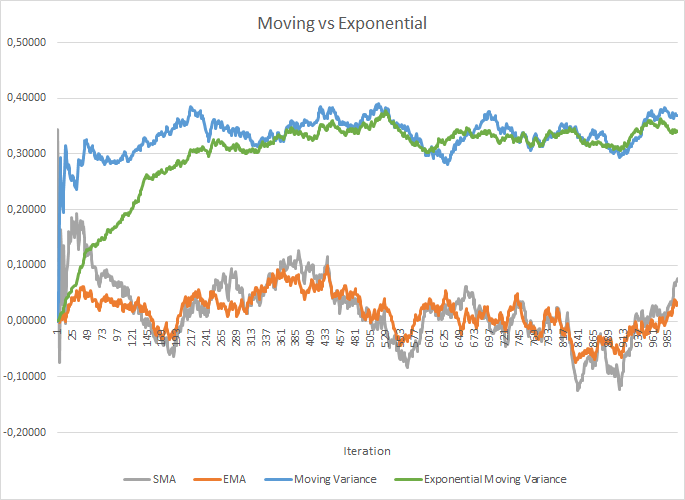
Como se pode ver no gráfico, a média móvel e a média móvel exponencial convergem após 120-130 iterações e, além disso, o desvio é mínimo, o que pode ser ignorado. Além disso, o gráfico de média móvel exponencial tem um aspecto mais suave. O valor anterior da função e o elemento da sequência atual é suficiente para calcular o EMA. Deixe-me lembrá-lo da fórmula da média móvel exponencial.
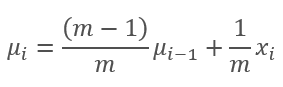 ,
,
Onde
- m é o tamanho da amostra (batch),
- i é a iteração.
Foram necessárias um pouco mais de iterações (310-320) para convergir os gráficos de variância móvel e variância móvel exponencial, mas o quadro geral é semelhante. No caso da variância, o uso do exponencial não só economiza memória, mas também reduz significativamente o número de cálculos, uma vez que para a variância móvel, recalcularíamos o desvio da média de todo o lote.
Os experimentos realizados pelos autores do método mostram que o uso do método de Normalização em Lotes também atua como regularizador. Isto torna possível abandonar o uso de outros métodos de regularização, em particular o Dropout discutido anteriormente. Além disso, existem trabalhos mais recentes que mostram que o uso combinado de Dropout e Normalização em lote afeta negativamente o desempenho do aprendizado da rede neural.
Em arquiteturas de rede neural modernas, o algoritmo de normalização proposto pode ser encontrado em diferentes variações. Os autores sugerem o uso da normalização em lote antes da não linearidade (fórmula de ativação). O método de Normalização de Camadas apresentado em julho de 2016 pode ser considerado uma das variações deste algoritmo. Nós o encontramos ao estudar o mecanismo de atenção [9]
2. Implementação
2.1 Criamos uma nova classe para nosso modelo
Após rever os aspectos teóricos do método, vamos ver como podemos implementá-lo em nossa biblioteca. Para implementar o algoritmo, vamos criar uma nova classe CNeuronBatchNormOCL.
A nova classe será herdada da classe base CNeuronBaseOCL. Similarmente à classe CNeuronDropoutOCL, vamos adicionar a variável PrevLayer. O método de substituição de buffer de dados demonstrado no artigo anterior será usado quando o tamanho do lote for inferior a "2", que armazenaremos na variável iBatchSize.
O algoritmo de normalização em lote preserva vários parâmetros que são individuais para cada neurônio na camada normalizada. Para não produzir muitos buffers separados para cada parâmetro individual, criaremos um único buffer de parâmetros BatchOptions com a estrutura a seguir.

Como se pode ver pela estrutura apresentada, o tamanho do buffer de parâmetros dependerá do método de otimização de parâmetros aplicado e, portanto, será criado no método de inicialização da classe.
O conjunto de métodos de classe já é padrão e vamos examiná-los em ordem. No construtor de classes, zeramos os ponteiros para os objetos e definimos um único tamanho de lote, o que praticamente exclui a camada da rede até que ela seja inicializada.
No destruidor de classes, vamos apagar o objeto do buffer de parâmetros e zerar o ponteiro para a camada anterior. Note que não apagamos o objeto da camada anterior, apenas reinicializamos o ponteiro para zero. O objeto será apagado onde foi criado.
Consideremos o método de inicialização da classe CNeuronBatchNormOCL::Init. Nos parâmetros passamos para a classe o número de neurônios da próxima camada, o índice de identificação do neurônio, o ponteiro para o objeto OpenCL, o número de neurônios na camada de normalização, o tamanho do lote e o método de otimização dos parâmetros.
No início do método, vamos chamar o método da classe pai com o mesmo nome, onde as variáveis base e os buffers de dados serão inicializados. Em seguida, salvamos o tamanho do lote e definimos a função de ativação da camada para None.
A função de ativação deve ser enfatizada aqui. A inclusão dessa funcionalidade depende da arquitetura da rede neural que está sendo construída. Se a arquitetura da rede neural permitir a normalização antes da função de ativação, como recomendado pelos autores do método, é necessário desativar a função de ativação na camada anterior e especificar a função requerida na camada de normalização. Tecnicamente, a função de ativação é especificada por meio da chamada do método SetActivationFunction da classe pai depois que a instância de classe é inicializada. Se, no entanto, a arquitetura da rede permitir a normalização após a função de ativação, o método de ativação é especificado na camada anterior e a camada de normalização permanece sem a função de ativação.
No final do método de inicialização, vamos criar um buffer de parâmetros. Como mencionado acima, o tamanho do buffer depende do número de neurônios na camada e do método de otimização dos parâmetros. Quando usamos SGD, reservamos 7 elementos para cada neurônio, enquanto com a otimização de Adam, precisamos de 9 elementos buffer por neurônio. Após a criação bem-sucedida do buffer, vamos preenchê-lo com zeros e sair do método com o resultado true.
O código completo das classes pode ser encontrado no anexo.
2.2. Passagem para frente
Vamos seguir adiante com o algoritmo e considerar o método de passagem para frente. E eu sugiro que comecemos olhando para o kernel de passagem para frente BatchFeedForward. Executaremos o algoritmo do kernel para cada neurônio individualmente.
Nos parâmetros, o kernel recebe ponteiros para 3 buffers: dados de origem, buffer de parâmetros e buffer para escrever os resultados. Adicionalmente, nos parâmetros, passaremos o tamanho do lote, o método de otimização e o algoritmo de ativação de neurônios.
No início do kernel, verificamos o tamanho especificado da janela de normalização. Se a normalização for realizada em um único neurônio, abandonamos o método sem realizar mais operações.
Após a verificação bem-sucedida, receberemos o identificador do fluxo que indicará a posição do valor normalizado no tensor de dados de entrada. Com ele, definimos o deslocamento para o primeiro parâmetro no tensor dos parâmetros de normalização. Nesta etapa, o método de otimização nos dirá a estrutura do buffer de parâmetros.
A seguir, vamos calcular a média exponencial e a variância nesta etapa. Vamos usá-los para calcular o valor normalizado de nosso elemento.
A próxima etapa do algoritmo de normalização em lote é o deslocamento e o dimensionamento. Deixe-me lembrá-lo de que, durante a inicialização, preenchemos o buffer de parâmetros com zeros, portanto, realizar esta operação "no estado puro" na primeira etapa retornará "0". Para evitar que isso aconteça, verificamos o valor atual do parâmetro γ e, se for igual a "0", alteramos seu valor para "1". Deixamos o deslocamento em zero. E, nesta forma, vamos realizar o deslocamento e o dimensionamento.
Após obter o valor normalizado, vamos verificar se há necessidade de realizar a função de ativação em dada camada e realizar as ações necessárias.
Agora só falta salvar os novos valores nos buffers de dados e sair do kernel.
Esperamos que o algoritmo de construção do kernel BatchFeedForward esteja fora de questão e possamos passar à criação do método para chamar o kernel a partir do programa principal. Esta funcionalidade será, como de costume, realizada pelo método CNeuronBatchNormOCL::feedForward. O algoritmo do método é semelhante aos métodos com o mesmo nome de outras classes. Nos parâmetros, o método recebe um ponteiro para a camada anterior da rede neural.
No início do método, vamos verificar a validade do ponteiro obtido e do ponteiro para o objeto OpenCL (deixe-me lembrar que esta é uma réplica de classe da biblioteca padrão para trabalhar com o programa OpenCL).
Na próxima etapa, salvamos o ponteiro para a camada anterior da rede neural e verificamos o tamanho do lote. Se o tamanho da janela de normalização não for maior que "1", copiamos o tipo de função de ativação da camada anterior e saímos do método com o resultado true. Dessa forma, forneceremos dados para troca de buffers e excluiremos iterações desnecessárias do algoritmo.
Se, após todas as verificações, chegarmos à inicialização do kernel de passagem para frente, prepararemos os dados de origem para iniciá-lo. Primeiro, vamos verificar a validade do ponteiro para o buffer de parâmetros do algoritmo de normalização. Se necessário, criamos e inicializamos um novo buffer. Em seguida, vamos criar um buffer na memória da placa de vídeo e carregar o conteúdo do buffer.
Definiremos o número de threads a serem executados com base no número de neurônios na camada e passaremos os ponteiros para os buffers de dados e os parâmetros necessários para o kernel.
Após a conclusão do trabalho preparatório, vamos enviar o kernel para execução e ler os dados atualizados do buffer de volta da memória da placa de vídeo. Observe que recebemos dados de 2 buffers da placa de vídeo: informações da saída do algoritmo e um buffer de parâmetro, no qual salvamos a média, a variância e o valor normalizado atualizados. Precisaremos desses dados nas próximas iterações.
Após a conclusão do algoritmo, excluímos o buffer de parâmetros da memória da placa de vídeo, liberando assim memória para carregar buffers das camadas subsequentes da rede neural e sair do método com o resultado true.
O código completo de todas as classes e seus métodos de nossa biblioteca pode ser encontrado no anexo.
2.3. Passagem para atrás
A passagem para atrás consiste em duas etapas: propagação inversa de erro e atualização dos coeficientes de peso. Somente ensinaremos os parâmetros γ e β das funções de deslocamento e deslocamento em vez dos coeficientes de peso habituais.
Primeiro, consideraremos a funcionalidade de descida de gradiente. Para implementar seu algoritmo, vamos criar um kernel CalcHiddenGradientBatch. Nos parâmetros, o kernel recebe ponteiros para os tensores dos parâmetros de normalização recebidos da próxima camada de gradientes, a saída da camada anterior (obtida durante a última passagem para frente) e o tensor de gradiente da camada anterior da rede neural, onde os resultados do algoritmo serão gravados. O tamanho do lote, o tipo de função de ativação e o método de otimização de parâmetros também serão passados para o kernel nos parâmetros.
Como na passagem para frente, verificamos o tamanho do lote no início do kernel e se for menor ou igual a "1", saímos do kernel sem realizar outras iterações.
O próximo passo é obter o número de série de nosso fluxo e determinar o deslocamento no tensor de parâmetros. Estas ações são similares às descritas para a passagem para frente.
Em seguida, calcularemos sequencialmente os gradientes para todas as funções do algoritmo.
E, finalmente, vamos desenhar um gradiente por meio da função de ativação da camada anterior. O valor obtido será armazenado no tensor de gradiente da camada anterior.
Depois do kernel СalcHeaderBatch, vamos agora desmontar o método CNeuronBatchNormOCL::calcInputGradients que irá iniciar a execução do kernel a partir do programa principal. Como métodos de outras classes com o mesmo nome, o método recebe um ponteiro para um objeto da camada anterior da rede neural em seus parâmetros.
No início do método, verificamos a validade do ponteiro obtido e do ponteiro para o objeto OpenCL. Em seguida, verificamos o tamanho do lote. Se for menor ou igual a "1", saímos do método. O resultado retornado pelo método dependerá da validade do ponteiro para a camada anterior salva durante a passagem para frente.
Se formos mais longe no algoritmo, verificamos a validade do buffer de parâmetros. Se houver um erro, abandonamos o método com o resultado false.
Note que o gradiente de descida está relacionado à última passagem para frente. Por isso, nos dois últimos pontos de controle, verificamos os objetos que participam da passagem para frente.
O número de threads do kernel acionados como na passagem para frente será igual ao número de neurônios na camada. Enviamos o conteúdo do buffer de parâmetros de normalização para a memória da placa de vídeo e passamos apontadores para os tensores e parâmetros necessários para o kernel.
Após realizar todas as operações acima, executamos o kernel e calculamos os gradientes resultantes da memória da placa de vídeo no buffer correspondente.
No final do método, apagamos o tensor do parâmetro de normalização da memória da placa de vídeo e saímos do método com o resultado true.
Após a transferência do gradiente, é hora de atualizar os parâmetros de deslocamento e de dimensionamento. Para executar estas iterações, vamos criar 2 kernels, UpdateBatchOptionsMomentum e UpdateBatchOptionsAdam, de acordo com o número de métodos de otimização descritos acima.
Antes de tudo, vamos dar uma olhada no método UpdateBatchOptionsMomentum. Nos parâmetros, o método recebe indicações para 2 tensores: parâmetros de normalização e gradientes. Também passamos constantes no método de otimização, ou seja, fator de treinamento e momentum, nos parâmetros do método.
No início do kernel, obteremos o número de fluxo e determinaremos a mudança no tensor do parâmetro de normalização.
Usando os dados iniciais, vamos calcular o tamanho do delta para γ e β. Utilizei cálculos vetoriais com vetor double de 2 elementos para realizar esta operação. Este método permite fazer os cálculos em paralelo.
Vamos corrigir os parâmetros γ, β e salvar os resultados nos elementos correspondentes do tensor do parâmetro de normalização.
O kernel UpdateBatchOptionsAdam é construído usando o mesmo esquema, sendo a diferença no algoritmo do próprio método de otimização. Em seus parâmetros, o kernel recebe indicações para o mesmo parâmetro e tensores de gradiente. Além disso, ele obtém parâmetros do método de otimização.
Vamos definir o número de fluxo e o deslocamento do parâmetro tensor no início do núcleo.
Usando os dados obtidos, calcularemos o primeiro e segundo momentum. Os cálculos vetoriais também foram aplicados aqui, permitindo-nos calcular os momentum para 2 parâmetros simultaneamente.
Usando os momentum obtidos, calculamos os deltas e os novos valores dos parâmetros. Vamos salvar os resultados do cálculo nos elementos correspondentes do tensor dos parâmetros de normalização.
Vamos criar o método CNeuronBatchNormOCL::updateInputWeights para iniciar os kernels a partir do programa principal. Nos parâmetros, o método recebe um ponteiro para a camada anterior da rede neural. Essencialmente, este ponteiro não será usado no algoritmo do método, mas deixado para a herança de métodos da classe pai.
No início do método, verificamos a validade do ponteiro resultante e do ponteiro para o objeto OpenCL. Da mesma forma que o método CNeuronBatchNormOCL::calcInputGradients anteriormente considerado, verificamos o tamanho do lote e a validade do buffer de parâmetros. Carregamos o conteúdo do buffer de parâmetros na memória do adaptador de vídeo. Definimos o número de fluxos igual ao número de neurônios na camada.
Agora ramificamos o algoritmo de acordo com o método de otimização especificado. Transmitimos os parâmetros iniciais para o kernel necessário e iniciamos sua execução.
Independentemente do método de otimização dos parâmetros, vamos ler o conteúdo atualizado do buffer de parâmetros de normalização e remover o buffer da memória da placa de vídeo.
Após a execução bem-sucedida de todas as operações do método, saímos com o resultado true.
Os métodos de substituição de buffers foram descritos em detalhes no artigo anterior e, creio, não serão difíceis de entender. Assim como os métodos de trabalho com arquivos (salvar e carregar uma rede neural treinada).
O código completo das classes pode ser encontrado no anexo.
2.4. Mudanças pontuais nas classes base da rede neural
E seguindo a tradição, após a criação de uma nova classe, ela deve ser integrada à estrutura geral de nossa rede neural. A primeira coisa a fazer é criar um identificador para nossa classe.
Em seguida, definiremos substituições de macro de constantes para trabalhar com novos kernels.
No construtor de redes neurais CNet::CNet acrescentamos blocos de criação de objetos da nova classe e inicialização de novos núcleos (as alterações estão destacadas).
Da mesma forma, inicializamos novos núcleos ao carregar a rede neural pré-treinada.
Adicionamos um novo tipo de neurônio ao método de carregamento da rede neural pré-treinada.
Da mesma forma, acrescentamos um novo tipo de neurônios nos métodos da classe base CNeuronBaseOCL.
O código completo de todas as classes e seus métodos pode ser encontrado no anexo.
3. Teste
Continuamos testando novas classes nos EAs criados anteriormente, o que nos dá dados comparáveis para avaliar o trabalho de elementos individuais. Vamos testar o método de normalização com base no Expert Advisor do artigo [12], em que substituímos Dropout pela Normalização em lote. A estrutura da rede neural do novo Expert Advisor é apresentada abaixo. Além disso, a taxa de aprendizagem foi aumentada de 0,000001 para 0,001.
O Expert Advisor foi testado no EURUSD, timeframe H1. A entrada da rede neural é alimentada com os dados históricos das últimas 20 velas, como nos testes anteriores.
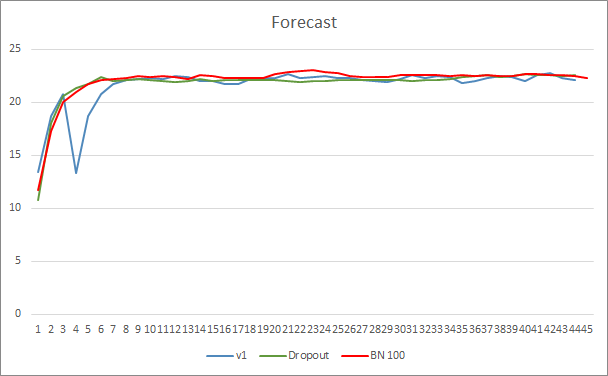
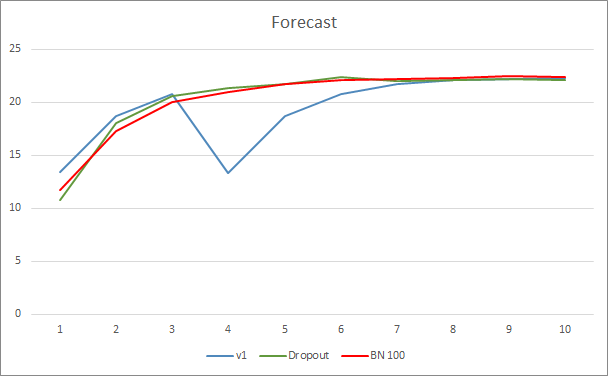
O gráfico do erro de previsão da rede neural mostra que o EA com normalização mostra um gráfico menos suavizado que pode ser causado por um forte aumento na curva da taxa de aprendizagem. Além disso, o erro de previsão em si é inferior aos testes anteriores ao longo de todo o período de teste.
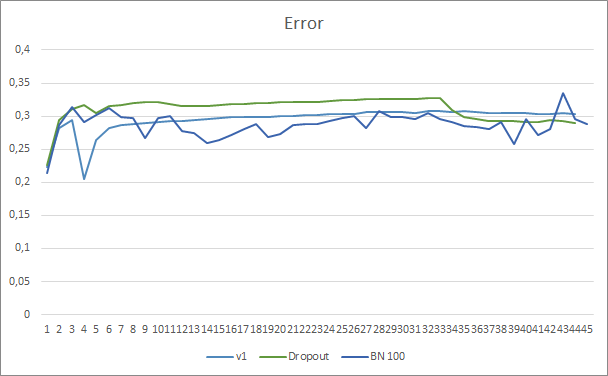
A curva de acerto dos padrões previstos para os três EAs é bastante próxima e não nos permite dizer que qualquer um dos métodos é superior.
Fim do artigo
Neste artigo continuamos nosso conhecimento dos métodos de melhoria da convergência da rede neural e acrescentamos a classe de normalização de dados em lote à nossa biblioteca. Os testes mostraram que o uso deste método permite reduzir o erro da rede neural e aumentar a velocidade de aprendizagem.
Links
- Redes neurais de maneira fácil
- Redes neurais de maneira fácil (Parte 2): Treinamento e teste da rede
- Redes Neurais de Maneira Fácil (Parte 3): Redes Convolucionais
- Redes Neurais de Maneira Fácil (Parte 4): Redes Recorrentes
- Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
- Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural
- Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
- Redes Neurais de Maneira Fácil (Parte 8): Mecanismos de Atenção
- Redes Neurais de Maneira Fácil (Parte 9): Documentação do trabalho
- Redes neurais de maneira fácil (Parte 10): Atenção Multi-Cabeça
- Redes Neurais de Maneira Fácil (parte 11): uma Visão sobre a GPT
- Redes neurais de maneira fácil (Parte 12): Dropout
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Layer Normalization
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH_b.mq5 | Expert Advisor | Expert Advisor com rede neural de classificação (3 neurônios na camada de saída) usando arquitetura GPT, 5 camadas de atenção+ BatchNorm |
| 2 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para a criação de uma rede neural |
| 3 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
| 4 | NN.chm | Ajuda HTML | Arquivo de ajuda CHM compilado com ajuda da biblioteca. |