От теории к практике - страница 173
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Приветствую, Владимир!
Нет его работ по квантовой физике в Интернете - все обыскал. Осталось только барахло, написанное уже на старости лет. Очень хочу понять, как он пришел к этому псевдодифференциальному уравнению... Не поверите - его аналитические выводы полностью соответствуют моим экспериментальным данным.
В https://www.mql5.com/ru/forum/221552/page158#comment_6392311 я давал Вам ссылку.
Там как раз есть параметр (Овершот), программы на MQL, его вычисляющие, способы их применения и интерпретации результатов - в общем, то, чего нет у негэнтропии. И, главное, прямое доказательство того, что отделяются именно тренд от флета. В отличие от негэнтропии, в нужных свойствах которой пока что нас убеждает Ваше традиционное "Вот так-то", цену которому здесь уже выяснили на множестве примеров Вашей убежденности, уверенности. В том числе абсолютных.
Поставьте памятник авторам того сообщения (статьи).
Тренд от флета прекрасно отделяется обычным обновлением хая/лоя, если что (по смыслу очень близко к овершотам, о которых пишет Vladimir. Правда, у зигзага порог фиксированный, и мне это не очень нравится).
Хотелось бы уточнить.
По-моему, интересно влияние характера колебаний на прибыльность торговли на пробой уровня и на отбой от уровня. Отсюда и деление тренд/флет, и его цель. В http://www.argolab.net/izuchaem-zigzagi.html эта цель отражена непосредственно:
"Если на практике среднее значение овершотов окажется значительно больше единицы, это значит, нам будет выгодно открывать сделку по направлению образовавшегося колена ЗигЗага («на пробой»). А если существенно меньше 1, то нам следует открывать сделку в противоположном направлении («на откат»)."
Я пока не понимаю, как эта цель отражена в "обычном обновлении хая/лоя". Расскажете?
Это всего лишь инструмент, как и зигзаг, например: High(i, 30)-High(i+5, 30). Просто мне он ближе, потому что (наверное) лучше учитывает текущую волатильность. Как и в зигзаге, можно изобрести какие-то метрики, например поделить величину обновления на высоту (ширину?) канала. На флете будет близко к нулю, на тренде порядка 0.5-1. Там, где у зигзага овершот, у этого инструмента будет обновление хая/лоя.
Что касается характера колебаний, то усреднение метрик по всему активу - это вроде "средней температуры по больнице", потому что трендовость/флетовость сосредоточена в определенные часы суток (если мы говорим о работе внутри дня). Хотя есть два кросса (думаю, знаете, какие), у которых флетовость в среднем чуть выше чем у остальных пар.
К вопросу о параметре, анализируя который можно отделить флэт от тренда.
Этим параметром является отнюдь не коэффициент Херста.
А знаете что? Этот параметр называется негэнтропия https://en.wikipedia.org/wiki/Negentropy
Вот кто первым научиться правильно ее вычислять и использовать в алгоритмах, тому надо памятник при жизни ставить от благодарного человечества. Вот так-то!
очередная попытка сглаживания
можно и так
только одно но
опять же теряется точность
а ведь "копейка рубль бережет"
очередная попытка сглаживания
можно и так
только одно но
опять же теряется точность
а ведь "копейка рубль бережет"
Не, это классная вещь. Фактически - это сумма произведений вероятностей приращений и логарифмов этих вероятностей при определенном объеме выборки. Показывает, насколько сильно на данный момент времени распределение вероятностей отличается от некоего эталона. Надо просто таблицу, как Херст составить и все.
Я давно искал этот скрытый параметр, т.к. асимметрии и эксцесса недостаточно. Со слезами на глазах просил трейдеров здесь на форуме помочь мне найти его. Откликнулись только 2 уважаемых мной трейдера - Vladimir и Dmitriy Skub. Предложили свои варианты. У остальных же - полнейшее непонимание и одубение. И как вообще кто-то деньги тут зарабатывает, абсолютно не шаря ни в чем? Парадокс!
Вот графики для пары AUDCAD за прошедшие 2 недели при объеме выборки 16900 тиков для экспоненциального времени считывания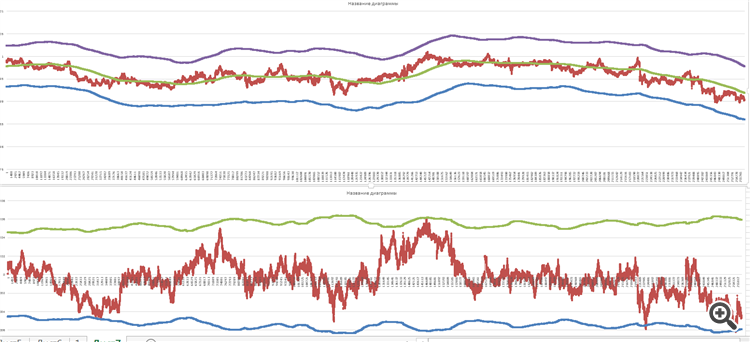
Да, вроде все отлично и хорошо, но что-то меня тревожит... Щас объясню что.
Сначала немного теории:
Вот это произведение F(x,t) и есть то распределение приращений, которое мы видим.
Функция Макдональда отвечает за "память" нашего процесса.
А вот что получаю я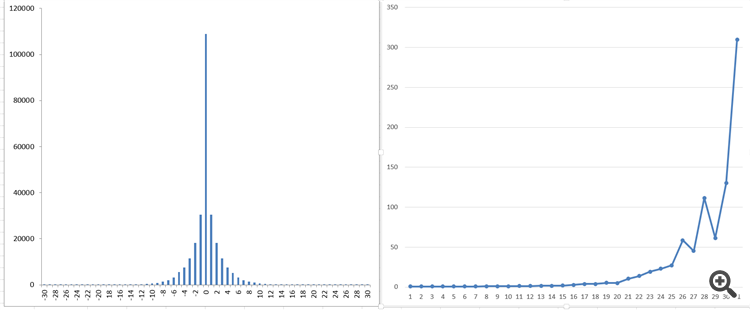
Вот то, что Вы видите справа - это то, что я получаю в виде "памяти" процесса.
Это при генеральной совокупности более 250.000 тиков!
Увы, я не вижу гладкой функции, подобной модифицированным функциям Бесселя. Не должно быть этих "скачков"...
Вот из-за этого я почти пришел к выводу, что все-таки, скорее всего, тиковые данные я принимаю НЕПРАВИЛЬНО.
Все-таки надо принимать через равномерные интервалы времени. Хотя... Только практика может это подтвердить.
Пока остаюсь при хорошем результате и безудержных сомнениях...
А вот что получаю я
Вот то, что Вы видите справа - это то, что я получаю в виде "памяти" процесса.
Это при генеральной совокупности более 250.000 тиков!
Увы, я не вижу гладкой функции, подобной модифицированным функциям Бесселя. Не должно быть этих "скачков"...
Вот из-за этого я почти пришел к выводу, что все-таки, скорее всего, тиковые данные я принимаю НЕПРАВИЛЬНО.
Все-таки надо принимать через равномерные интервалы времени. Хотя... Только практика может это подтвердить.
Пока остаюсь при хорошем результате и безудержных сомнениях...
Данные у Вас правильные - у всех такие, причем на всех таймфреймах. Это обычный вид нестационарных приращений, в которых полный букет: меняется средняя, меняется дисперсия, хвосты и ARCH-эффект. Моделировать надо все:
И тыщи и тыщи людей занимаются этим лет 30 или 40.