Redes Neurais de Maneira Fácil (Parte 11): Uma visão sobre a GPT
Dmitriy Gizlyk | 4 maio, 2021
Índice
- Introdução
- 1. Entendendo os modelos GPT
- 2. Diferenças entre a GPT e o Transformer considerado anteriormente
- 3. Implementação
- 3.1. Criando uma Nova Classe para o Nosso Modelo
- 3.2. Propagação direta
- 3.3. Retropropagação
- 3.4. Alterações nas Classes Base da Rede Neural
- 4. Teste
- Conclusão
- Referências
- Programas utilizados no artigo
Introdução
Em junho de 2018, a OpenAI apresentou o modelo de rede neural GPT, que imediatamente mostrou os melhores resultados em uma série de testes de linguagem. A GPT-2 foi lançada em 2019 e a GPT-3 foi apresentada em Maio de 2020. Esses modelos demonstraram a capacidade da rede neural de gerar textos relacionados. Experimentos adicionais envolveram a capacidade de gerar música e imagens. A principal desvantagem de tais modelos está relacionada aos recursos de computação que o envolvem. Levou-se um mês para treinar a primeira GPT em uma máquina com 8 GPUs. Esta desvantagem pode ser parcialmente compensada pela possibilidade de usar modelos pré-treinados para resolver novos problemas. Mas são necessários recursos consideráveis para manter o funcionamento do modelo, considerando o seu tamanho.
1. Entendendo os modelos GPT
Conceitualmente, os modelos GPT são construídos com base no Transformer anteriormente considerado. A ideia principal é conduzir um pré-treinamento não supervisionado de um modelo em uma grande quantidade de dados e, em seguida, ajustá-lo em uma quantidade relativamente pequena de dados rotulados.
O motivo do treinamento em duas etapas é o tamanho do modelo. Modelos modernos de aprendizado de máquina profundo, como a GPT, envolvem um grande número de parâmetros, até centenas de milhões. Portanto, o treinamento de tais redes neurais requer uma grande amostra de treinamento. Ao usar o aprendizado supervisionado, a criação de um conjunto de treinamento rotulado exigiria muito trabalho. Ao mesmo tempo, existem muitos textos digitalizados e não rotulados na web, que são ótimos para o treinamento de modelos não supervisionados. No entanto, as estatísticas mostram que os resultados da aprendizagem não supervisionada são inferiores à aprendizagem supervisionada. Portanto, após o treinamento não supervisionado, o modelo é ajustado em uma amostra relativamente pequena de dados rotulados.
O aprendizado não supervisionado permite que a GPT aprenda o modelo de linguagem, enquanto o treinamento adicional em dados rotulados ajusta o modelo para tarefas específicas. Assim, um modelo pré-treinado pode ser replicado e ajustado para executar diferentes tarefas de linguagem. A limitação é baseada no idioma do conjunto original para a aprendizagem não supervisionada.
A prática tem mostrado que essa abordagem gera bons resultados em uma ampla gama de problemas de linguagem. Por exemplo, o modelo da GPT-3 é capaz de gerar textos coerentes sobre um determinado tópico. No entanto, observe que o modelo especificado contém 175 bilhões de parâmetros, e foi pré-treinado em um conjunto de dados de 570 GB.
Embora os modelos da GPT tenham sido desenvolvidos para o processamento de linguagem natural, eles também tiveram um bom desempenho em tarefas de geração de música e imagem.
Em teoria, os modelos da GPT podem ser usados com qualquer sequência de dados digitalizados. O único pré-requisito é a suficiência de dados e recursos para o pré-aprendizado não supervisionado.
2. Diferenças entre a GPT e o Transformer considerado anteriormente
Vamos considerar o que difere os modelos da GPT do Transformer anteriormente considerado. Em primeiro lugar, os modelos da GPT não usam um codificador, pois eles usam apenas um decodificador. Embora não haja codificador, os modelos não têm mais a camada interna de Self-Attention do Encoder-Decoder. A figura abaixo mostra um bloco do transformer da GPT.
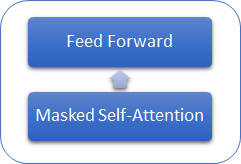
Semelhante ao Transformer clássico, os blocos nos modelos da GPT são construídos uns sobre os outros. E cada bloco tem suas próprias matrizes de peso para o mecanismo de atenção e camadas Feed Forward totalmente conectadas. O número de blocos determina o tamanho do modelo. A pilha de blocos pode ser muito grande. A GPT-1 e a menor GPT-2 (GPT-2 Small) têm 12 blocos; A GPT-2 Extra Large tem 48 deles, enquanto a GPT-3 tem 96 blocos.
Semelhante aos modelos de linguagem tradicionais, a GPT permite encontrar relacionamentos apenas com elementos anteriores da sequência, mas ela não pode olhar para o futuro. Mas, ao contrário do transformer, a GPT não usa mascaramento de elementos — em vez disso, ela faz alterações no processo computacional. A GPT redefine as taxas de atenção na matriz Score para os elementos subsequentes.
Ao mesmo tempo, a GPT pode ser classificada como um modelo autoregressivo. Um token de sequência é gerado em cada iteração. O token resultante é adicionado à sequência de entrada e alimentado no modelo para a próxima iteração.
Como no transformer clássico, três vetores são gerados para cada token dentro do mecanismo de self-attention: um query, um key e um value. No modelo autoregressivo, no qual a cada nova iteração a sequência de entrada muda em apenas 1 token, não há necessidade de recalcular os vetores para cada token. Portanto, cada camada na GPT calcula os vetores apenas para novos elementos da sequência e os calcula para cada elemento da sequência. Cada bloco do transformer salva seus vetores para uso posterior.
Essa abordagem permite que o modelo gere textos palavra por palavra, antes de receber o token final.
Obviamente, os modelos da GPT usam o mecanismo Multi-Head Attention.
3. Implementação
Antes de começar, vamos repetir brevemente o algoritmo:
- Uma sequência de entrada de tokens é alimentada no bloco do transformer.
- Três vetores são calculados para cada token (query, key, value) multiplicando o vetor do token pela matriz de pesos W correspondente, que está sendo treinada.
- Multiplicando 'query' e 'key', nós determinamos as dependências entre os elementos da sequência. Nesta etapa, o vetor 'query' de cada elemento da sequência é multiplicado pelos vetores 'key' do elemento atual e de todos os elementos anteriores da sequência.
- A matriz dos escores de atenção obtidos é normalizada usando a função SoftMax no contexto de cada query. Um escore de atenção igual a zero é definido para os elementos subsequentes da sequência.
- Multiplicando os escores de atenção normalizados pelos vetores 'value' dos elementos correspondentes da sequência e, em seguida, adicionando os vetores resultantes, nós obtemos o valor corrigido de atenção para cada elemento da sequência (Z).
- Em seguida, nós determinamos o vetor Z ponderado com base nos resultados de todas as cabeças de atenção. Para isso, os vetores 'value' corrigidos de todas as cabeças de atenção são concatenados em um único vetor e, em seguida, multiplicados pela matriz W0 que está sendo treinada.
- O tensor resultante é adicionado à sequência de entrada e normalizado.
- O mecanismo Multi-Heads Self-Attention é seguido por duas camadas totalmente conectadas do bloco Feed Forward. A primeira camada (oculta) contém 4 vezes mais neurônios do que a sequência de entrada com a função de ativação ReLU. A dimensão da segunda camada é igual à dimensão da sequência de entrada e os neurônios não usam a função de ativação.
- O resultado das camadas totalmente conectadas é resumido com o tensor que é alimentado no Bloco da Feed Forward. O tensor resultante é então normalizado.
Uma sequência para todas as Cabeças de Self-Attention. Além disso, as ações em 2-5 são idênticas para cada cabeça de atenção.
Como resultado das etapas 3 e 4, nós obtemos uma matriz quadrada Score, dimensionado de acordo com o número de elementos na sequência, em que a soma de todos os elementos no contexto de cada 'query' é "1".
3.1. Criando uma Nova Classe para o Nosso Modelo.
Para implementar nosso modelo, vamos criar uma nova classe CNeuronMLMHAttentionOCL, com base na classe base CNeuronBaseOCL. Eu deliberadamente dei um passo para trás e não usei as classes de atenção criadas anteriormente. Isso ocorre porque agora nós lidamos com os novos princípios de criação da Multi-Head Self-Attention. Anteriormente, no artigo 10, nós criamos a classe CNeuronMHAttentionOCL, que forneceu um recálculo sequencial de 4 threads de atenção. O número de threads foi codificado em métodos e, portanto, alterar o número de threads exigiria um esforço significativo, relacionado às mudanças no código da classe e seus métodos.
Uma advertência. Conforme mencionado acima, o modelo da GPT usa uma pilha de blocos de transformers idênticos com os mesmos hiperparâmetros (inalteráveis), com a única diferença nas matrizes sendo treinadas. Portanto, eu decidi criar um bloco multicamadas que permitisse criar modelos com hiperparâmetros que podem ser passados na hora de criar uma classe. Isso inclui o número de repetições de blocos do transformer na pilha.
Como resultado, nós temos uma classe que pode criar quase todo o modelo com base em alguns parâmetros especificados. Portanto, no bloco 'protegido' da nova classe, nós declaramos cinco variáveis para armazenar os parâmetros do bloco:
| iLayers | Número de blocos de transformer no modelo |
| iHeads | Número de cabeças de Self-Attention |
| iWindow | Tamanho da janela de entrada (1 token de sequência de entrada) |
| iWindowKey | Dimensões de vetores internos Query, Key, Value |
| iUnits | Número de elementos (tokens) na sequência de entrada |
Além disso, no bloco 'protected', nós declaramos 6 matrizes para armazenar uma coleção de buffers para os nossos tensores e matrizes de peso de treinamento:
| QKV_Tensors | Matriz para armazenar os tensores Query, Key, Value e seus gradientes |
| QKV_Weights | Matriz para armazenar uma coleção de matrizes de peso Wq, Wk, Wv e suas matrizes de momento |
| S_Tensors | Matriz para armazenar uma coleção de matrizes Score e seus gradientes |
| AO_Tensors | Matriz para armazenar os tensores de saída do mecanismo Self-Attention e seus gradientes |
| FF_Tensors | Matriz para armazenar os tensores de entrada, ocultos e de saída do bloco Feed Forward e seus gradientes |
| FF_Weights | Matriz para armazenar as matrizes de peso do bloco Feed Forward e seus momentos. |
Nós vamos considerar os métodos de classe mais tarde, ao implementá-los.
class CNeuronMLMHAttentionOCL : public CNeuronBaseOCL { protected: uint iLayers; ///< Number of inner layers uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CCollection *QKV_Tensors; ///< The collection of tensors of Queries, Keys and Values CCollection *QKV_Weights; ///< The collection of Matrix of weights to previous layer CCollection *S_Tensors; ///< The collection of Scores tensors CCollection *AO_Tensors; ///< The collection of Attention Out tensors CCollection *FF_Tensors; ///< The collection of tensors of Feed Forward output CCollection *FF_Weights; ///< The collection of Matrix of Feed Forward weights ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. virtual bool ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ); ///< \brief Convolution Feed Forward method of calling kernel ::FeedForwardConv(). virtual bool AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true); ///< \brief Multi-heads attention scores method of calling kernel ::MHAttentionScore(). virtual bool AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out); ///< \brief Multi-heads attention out method of calling kernel ::MHAttentionOut(). virtual bool SumAndNormilize(CBufferDouble *tensor1, CBufferDouble *tensor2, CBufferDouble *out); ///< \brief Method sum and normalize 2 tensors by calling 2 kernels ::SumMatrix() and ::Normalize(). ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends on optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. virtual bool ConvolutuionUpdateWeights(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *momentum1, CBufferDouble *momentum2, uint window, uint window_out); ///< Method for updating weights in convolution layer.\details Calling one of kernels ::UpdateWeightsConvMomentum() or ::UpdateWeightsConvAdam() in depends on optimization type (#ENUM_OPTIMIZATION). virtual bool ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ); ///< Method of passing gradients through a convolutional layer. virtual bool AttentionInsideGradients(CBufferDouble *qkv,CBufferDouble *qkv_g,CBufferDouble *scores,CBufferDouble *scores_g,CBufferDouble *gradient); ///< Method of passing gradients through attention layer. public: /** Constructor */CNeuronMLMHAttentionOCL(void); /** Destructor */~CNeuronMLMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMLMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
No construtor de classe, nós definimos os valores iniciais dos hiperparâmetros da classe e inicializamos as matrizes de coleção.
CNeuronMLMHAttentionOCL::CNeuronMLMHAttentionOCL(void) : iLayers(0), iHeads(0), iWindow(0), iWindowKey(0), iUnits(0) { QKV_Tensors=new CCollection(); QKV_Weights=new CCollection(); S_Tensors=new CCollection(); AO_Tensors=new CCollection(); FF_Tensors=new CCollection(); FF_Weights=new CCollection(); }
Da mesma forma, nós excluímos as matrizes de coleção no destrutor de classe.
CNeuronMLMHAttentionOCL::~CNeuronMLMHAttentionOCL(void) { if(CheckPointer(QKV_Tensors)!=POINTER_INVALID) delete QKV_Tensors; if(CheckPointer(QKV_Weights)!=POINTER_INVALID) delete QKV_Weights; if(CheckPointer(S_Tensors)!=POINTER_INVALID) delete S_Tensors; if(CheckPointer(AO_Tensors)!=POINTER_INVALID) delete AO_Tensors; if(CheckPointer(FF_Tensors)!=POINTER_INVALID) delete FF_Tensors; if(CheckPointer(FF_Weights)!=POINTER_INVALID) delete FF_Weights; }
A inicialização da classe junto com a construção do modelo é realizada no método Init. O método recebe nos parâmetros:
| numOutputs | Número de elementos na camada subsequente para a criação dos links |
| myIndex | Índice dos neurônios na camada |
| open_cl | Ponteiro de objeto OpenCL |
| window | Tamanho da janela de entrada (token de sequência de entrada) |
| window_key | Dimensões de vetores internos Query, Key, Value |
| heads | Número de cabeças de Self-Attention (threads) |
| units_count | Número de elementos na sequência de entrada |
| layers | Número de blocos (camadas) na pilha do modelo |
| optimization_type | Método de otimização de parâmetros durante o treinamento |
bool CNeuronMLMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint window_key,uint heads,uint units_count,uint layers,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,window*units_count,optimization_type)) return false; //--- iWindow=fmax(window,1); iWindowKey=fmax(window_key,1); iUnits=fmax(units_count,1); iHeads=fmax(heads,1); iLayers=fmax(layers,1);
No início do método, nós inicializamos a classe pai chamando o método apropriado. Observe que nós não realizamos as verificações básicas para validar o ponteiro do objeto OpenCL recebido e o tamanho da sequência de entrada, pois essas verificações já estão implementadas no método da classe pai.
Após a inicialização bem-sucedida da classe pai, nós salvamos os hiperparâmetros nas variáveis correspondentes.
A seguir, nós calculamos os tamanhos dos tensores que estão sendo criados. Preste atenção à abordagem modificada anteriormente para organizar o Multi-Head Attention. Nós não criaremos as matrizes separadas para os vetores 'query', 'key' e 'value' - eles serão combinados em uma matriz. Além disso, nós não criaremos as matrizes separadas para cada cabeça de atenção. Em vez disso, nós criaremos as matrizes comuns para QKV (query + key+ value), Scores e saídas do mecanismo de self-attention. Os elementos serão divididos em sequências no nível dos índices do tensor. Claro, essa abordagem é mais difícil de entender. Também pode ser mais difícil encontrar o elemento necessário no tensor. Mas permite tornar o modelo flexível, de acordo com o número de cabeças de atenção, e organizar o recálculo simultâneo de todas as cabeças de atenção paralelizando os fios no nível do kernel.
O tamanho do tensor QKV_Tensor (num) é definido como o produto de três tamanhos do vetor interno (query + key + value) e o número de cabeças. O tamanho da matriz concatenada de pesos QKV_Weight é definido como o produto de três tamanhos do token de sequência de entrada, aumentados pelo elemento de deslocamento, pelo tamanho do vetor interno e o número de cabeças de atenção. Da mesma forma, vamos calcular os tamanhos dos tensores restantes.
uint num=3*iWindowKey*iHeads*iUnits; //Size of QKV tensor uint qkv_weights=3*(iWindow+1)*iWindowKey*iHeads; //Size of weights' matrix of QKV tensor uint scores=iUnits*iUnits*iHeads; //Size of Score tensor uint mh_out=iWindowKey*iHeads*iUnits; //Size of multi-heads self-attention uint out=iWindow*iUnits; //Size of our tensor uint w0=(iWindowKey+1)*iHeads*iWindow; //Size W0 tensor uint ff_1=4*(iWindow+1)*iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2=(4*iWindow+1)*iWindow; //Size of weights' matrix 2-nd feed forward layer
Depois de determinar os tamanhos de todos os tensores, executamos um ciclo pelo número de camadas de atenção no bloco para criar os tensores necessários. Observe que há dois loops aninhados organizados dentro do corpo do loop. O primeiro loop cria matrizes para tensores de valor e seus gradientes. O segundo cria arrays para as matrizes de peso e seus momentos. Observe que, para a última camada, nenhuma nova matriz é criada para o tensor de saída do bloco Feed Forward e seu gradiente. Em vez disso, os ponteiros para a saída da classe pai e matrizes de gradiente são adicionados à coleção. Essa etapa simples evita uma iteração desnecessária de transferência de valores entre matrizes, bem como elimina o consumo desnecessário de memória.
for(uint i=0; i<iLayers; i++) { CBufferDouble *temp=NULL; for(int d=0; d<2; d++) { //--- Initialize QKV tensor temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(num,0)) return false; if(!QKV_Tensors.Add(temp)) return false; //--- Initialize scores temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(scores,0)) return false; if(!S_Tensors.Add(temp)) return false; //--- Initialize multi-heads attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(mh_out,0)) return false; if(!AO_Tensors.Add(temp)) return false; //--- Initialize attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(4*out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i==iLayers-1) { if(!FF_Tensors.Add(d==0 ? Output : Gradient)) return false; continue; } temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; } //--- Initialize QKV weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; for(uint w=0; w<qkv_weights; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!QKV_Weights.Add(temp)) return false; //--- Initialize Weights0 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w=0; w<w0; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- Initialize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- for(int d=0; d<(optimization==SGD ? 1 : 2); d++) { temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights,0)) return false; if(!QKV_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(w0,0)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initialize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_1,0)) return false; if(!FF_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_2,0)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
Como resultado, para cada camada nós obtemos a seguinte matriz de tensores.
| QKV_Tensor |
|
| S_Tensors |
|
| AO_Tensors |
|
| FF_Tensors |
|
| QKV_Weights |
|
| FF_Weights |
|
Depois de criar as coleções de array, nós saímos do método com 'true'. O código completo de todas as classes e seus métodos está disponível no anexo.
3.2. Feed-forward.
O passo de feed-forward é tradicionalmente organizado no método feedForward, que recebe nos parâmetros um ponteiro para a camada anterior da rede neural. No início do método, verificamos a validade do ponteiro recebido.
bool CNeuronMLMHAttentionOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false;
A seguir, vamos organizar um loop para recalcular todas as camadas do nosso bloco. Ao contrário dos métodos análogos descritos anteriormente de outras classes, este método é de nível superior. As operações organizadas se resumem à preparação dos dados e à chamada dos métodos auxiliares (a lógica desses métodos será descrita a seguir).
No início do loop, nós recebemos da coleção o buffer de dados de entrada dos tensores QKV e QKV_Weights correspondente à camada atual. Em seguida, nós chamamos a ConvolutionForward para calcular os vetores Query, Key e Value.
for(uint i=0; (i<iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferDouble *inputs=(i==0? NeuronOCL.getOutput() : FF_Tensors.At(6*i-4)); CBufferDouble *qkv=QKV_Tensors.At(i*2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),inputs,qkv,iWindow,3*iWindowKey*iHeads,None)) return false;
Eu encontrei um problema ao aumentar as camadas de atenção. Em algum ponto, eu recebi o erro 5113 ERR_OPENCL_TOO_MANY_OBJECTS. Então, eu tive que pensar em armazenar todos os tensores permanentemente, na memória da GPU. Portanto, após concluir as operações, eu libero os buffers que não serão mais usados nesta etapa. Em seu código, não se esqueça de ler os dados mais recentes dos buffers liberados da memória da GPU. Na classe apresentada neste artigo, os dados do buffer são lidos nos métodos de inicialização do kernel, que discutiremos um pouco mais tarde.
CBufferDouble *temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree();
Escores de atenção e vetores ponderados dos valores do mecanismo Self-Attention são calculados de forma semelhante ao chamar os métodos apropriados.
//--- Score calculation temp=S_Tensors.At(i*2); if(IsStopped() || !AttentionScore(qkv,temp,true)) return false; //--- Multi-heads attention calculation CBufferDouble *out=AO_Tensors.At(i*2); if(IsStopped() || !AttentionOut(qkv,temp,out)) return false; qkv.BufferFree(); temp.BufferFree();
Depois de calcular a Multi-Heads Self-Attention, reduzimos a saída de atenção concatenada para o tamanho da sequência de entrada, adicionamos dois vetores e normalizamos o resultado.
//--- Attention out calculation temp=FF_Tensors.At(i*6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out,temp,iWindowKey*iHeads,iWindow,None)) return false; out.BufferFree(); //--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp,inputs,temp)) return false; if(i>0) inputs.BufferFree();
O mecanismo de autoatenção no transformador é seguido pelo bloco Feed Forward que consiste em duas camadas totalmente conectadas. Em seguida, o resultado é adicionado à sequência de entrada. O tensor final é normalizado e alimentado na próxima camada. No nosso caso, nós fechamos o ciclo.
//--- Feed Forward inputs=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),inputs,temp,iWindow,4*iWindow,LReLU)) return false; out=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); out.BufferFree(); out=FF_Tensors.At(i*6+2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),temp,out,4*iWindow,iWindow,activation)) return false; temp.BufferFree(); temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); //--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out,inputs,out)) return false; inputs.BufferFree(); } //--- return true; }
O código do método completo é fornecido em anexo abaixo. Agora, vamos considerar os métodos auxiliares chamados do método FeedForward. O primeiro método que chamamos é o ConvolutionForward. Ele é chamado quatro vezes por ciclo do método de feed forward. No corpo do método, é chamado o kernel da propagação direta da camada convolucional. Este método, neste caso, desempenha o papel de uma camada totalmente conectada para cada token separado da sequência de entrada. A solução foi discutida em mais detalhes no artigo 8. Em contraste com a solução descrita anteriormente, o novo método recebe ponteiros para os buffers nos parâmetros, para transferir dados para o kernel OpenCL. Portanto, no início do método, nós verificamos a validade dos ponteiros recebidos.
bool CNeuronMLMHAttentionOCL::ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(outputs)==POINTER_INVALID) return false;
Em seguida, nós criamos os buffers na memória da GPU e passamos as informações necessárias para eles.
if(!weights.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!outputs.BufferCreate(OpenCL)) return false;
Isso é seguido pelo código descrito no artigo 8, sem alterações. O kernel chamado é usado como está, sem alterações.
uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=outputs.Total()/window_out; OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_i,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_o,outputs.GetIndex()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_inputs,inputs.Total()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_step,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_window_in,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffс_window_out,window_out); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_activation,(int)activ); if(!OpenCL.Execute(def_k_FeedForwardConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel FeedForwardConv: %d",GetLastError()); return false; } //--- return outputs.BufferRead(); }
Mais adiante, no código do método feedForward, vem a chamada do método AttentionScore, que chama um kernel para calcular e normalizar as pontuações de atenção - esses valores resultantes são então gravados na matriz Score. Um novo kernel foi escrito para este método; será considerado mais tarde, após nós considerarmos o próprio método.
Como o método anterior, o AttentionScore recebe os ponteiros para os buffers de dados iniciais e os registros dos valores obtidos nos parâmetros. Assim, no início do método, nós verificamos a validade dos ponteiros recebidos.
bool CNeuronMLMHAttentionOCL::AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID) return false;
Seguindo a lógica descrita acima, vamos criar buffers para a troca de dados com a GPU.
if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false;
Após o trabalho preparatório, vamos prosseguir para a especificação dos parâmetros do kernel. As threads deste kernel serão criadas em duas dimensões: no contexto dos elementos da sequência de entrada e no contexto das cabeças de atenção. Isso fornece uma computação paralela para todos os elementos da sequência e todas as cabeças de atenção.
uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_score,scores.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_dimension,iWindowKey); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_mask,(int)mask);
A seguir, nós passamos diretamente para a chamada do kernel. Os resultados dos cálculos são lidos no buffer de 'score'.
if(!OpenCL.Execute(def_k_MHAttentionScore,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionScore: %d",GetLastError()); return false; } //--- return scores.BufferRead(); }
Vamos ver a lógica do kernel MHAttentionScore chamado. Conforme mostrado acima, o kernel recebe nos parâmetros um ponteiro para a matriz de dados de origem qkv e uma matriz para registrar as pontuações resultantes. Além disso, o kernel recebe nos parâmetros o tamanho dos vetores internos (Query, Key) e um flag para habilitar o algoritmo de mascaramento para os elementos subsequentes.
Primeiro, nós obtemos os números ordinais da consulta q sendo processada e a cabeça de atenção h. Além disso, nós obtemos a dimensão do número de consultas e cabeças de atenção.
__kernel void MHAttentionScore(__global double *qkv, ///<[in] Matrix of Querys, Keys, Values __global double *score, ///<[out] Matrix of Scores int dimension, ///< Dimension of Key int mask ///< 1 - calc only previous units, 0 - calc all ) { int q=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1);
Com base nos dados obtidos, determinamos a mudança nas matrizes para 'query' e 'score'.
int shift_q=dimension*(h+3*q*heads); int shift_s=units*(h+q*heads);
Além disso, calculamos um coeficiente de correção do Score.
double koef=sqrt((double)dimension); if(koef<1) koef=1;
Os escores de atenção são calculadas em um loop, no qual nós iremos iterar através das chaves de toda a sequência de elementos na cabeça de atenção correspondente.
No início do loop, verificamos a condição para usar o mecanismo de atenção. Se esta funcionalidade estiver habilitada, verificamos o número de série da chave. Se a chave atual corresponder ao próximo elemento da sequência, escrevemos a pontuação zero no array 'score' e vamos para o próximo elemento.
double sum=0; for(int k=0;k<units;k++) { if(mask>0 && k>q) { score[shift_s+k]=0; continue; }
Se o escore de atenção for calculado para a chave analisada, então nós organizamos um loop aninhado para calcular o produto dos dois vetores. Observe que o corpo do ciclo tem dois ramos de cálculo: um usando cálculos vetoriais e outro sem tais cálculos. A primeira ramificação é usada quando há 4 ou mais elementos da posição atual no vetor chave até seu último elemento; a segunda ramificação é usada para os últimos 4 elementos não múltiplos do vetor chave.
double result=0; int shift_k=dimension*(h+heads*(3*k+1)); for(int i=0;i<dimension;i++) { if((dimension-i)>4) { result+=dot((double4)(qkv[shift_q+i],qkv[shift_q+i+1],qkv[shift_q+i+2],qkv[shift_q+i+3]), (double4)(qkv[shift_k+i],qkv[shift_k+i+1],qkv[shift_k+i+2],qkv[shift_k+i+3])); i+=3; } else result+=(qkv[shift_q+i]*qkv[shift_k+i]); }
De acordo com o algoritmo transformer, os escores de atenção são normalizados usando a função SoftMax. Para implementar esse recurso, nós dividiremos o resultado do produto dos vetores pelo coeficiente de correção e determinaremos o expoente para o valor resultante. O resultado do cálculo deve ser escrito no elemento correspondente do tensor 'score' e adicionado à soma dos expoentes.
result=exp(clamp(result/koef,-30.0,30.0)); if(isnan(result)) result=0; score[shift_s+k]=result; sum+=result; }
Da mesma forma, nós calcularemos os expoentes para todos os elementos. Para completar a normalização SoftMax dos escores de atenção, nós organizamos outro ciclo, no qual todos os elementos do tensor 'Score' são divididos pela soma dos expoentes previamente calculada.
for(int k=0;(k<units && sum>1);k++) score[shift_s+k]/=sum; }
Saimos do kernel no final do ciclo.
Vamos prosseguir com o método feedForward e considerar o método auxiliar AttentionOut. O método recebe nos parâmetros os ponteiros para os três tensores: QKV, Scores e Out. A estrutura do método é semelhante àquelas consideradas anteriormente. Ele lança os kernels MHAttentionOut em duas dimensões: elementos de sequência e cabeças de atenção.
bool CNeuronMLMHAttentionOCL::AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID || CheckPointer(out)==POINTER_INVALID) return false; uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false; if(!out.BufferCreate(OpenCL)) return false; //--- OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_score,scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_out,out.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionOut,def_k_mhao_dimension,iWindowKey); if(!OpenCL.Execute(def_k_MHAttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionOut: %d",GetLastError()); return false; } //--- return out.BufferRead(); }
Como o kernel anterior, MHAttentionOut foi escrito novamente, levando em consideração o Multi-Head Attention. Ele usa um único buffer para os tensores de consultas, chaves e valores. O kernel recebe nos parâmetros os ponteiros para os tensores Scores, QKV, Out e o tamanho do vetor de valor. O primeiro e o segundo buffers fornecem os dados originais e o último é usado para registrar o resultado.
Além disso, no início do kernel, determinamos os números ordinais da consulta q sendo processada e o cabeçalho de atenção h, bem como a dimensão do número de consultas e cabeças de atenção.
__kernel void MHAttentionOut(__global double *scores, ///<[in] Matrix of Scores __global double *qkv, ///<[in] Matrix of Values __global double *out, ///<[out] Output tensor int dimension ///< Dimension of Value ) { int u=get_global_id(0); int units=get_global_size(0); int h=get_global_id(1); int heads=get_global_size(1);
Em seguida, determinamos a posição do escore de atenção necessário e do primeiro elemento do vetor de valor de saída que está sendo analisado. Além disso, calculamos o comprimento do vetor de um elemento no tensor QKV - este valor será usado para determinar o deslocamento no tensor QKV.
int shift_s=units*(h+heads*u); int shift_out=dimension*(h+heads*u); int layer=3*dimension*heads;
Nós implementaremos os loops aninhados para os principais cálculos. O loop externo será executado para o tamanho do vetor de valores; o loop interno será executado pelo número de elementos na sequência original. No início do loop externo, vamos declarar uma variável para calcular o valor resultante e inicializá-la com um valor igual a zero. O loop interno começa a definir um deslocamento para o vetor de valores. Observe que o passo do loop interno é igual a 4, porque mais tarde nós iremos usar os cálculos vetoriais.
for(int d=0;d<dimension;d++) { double result=0; for(int v=0;v<units;v+=4) { int shift_v=dimension*(h+heads*(3*v+2))+d;
Como no kernel MHAttentionScore, vamos dividir os cálculos em duas threads: uma usando os cálculos vetoriais e
a outra sem eles. A segunda thread será usada apenas para os últimos elementos, nos casos em que o comprimento da sequência não for múltiplo de 4.
if((units-v)>4) { result+=dot((double4)(scores[shift_s+v],scores[shift_s+v+1],scores[shift_s+v+1],scores[shift_s+v+3]), (double4)(qkv[shift_v],qkv[shift_v+layer],qkv[shift_v+2*layer],qkv[shift_v+3*layer])); } else for(int l=0;l<(int)fmin((double)(units-v),4.0);l++) result+=scores[shift_s+v+l]*qkv[shift_v+l*layer]; } out[shift_out+d]=result; } }
Depois de sair do loop aninhado, escrevemos o valor resultante no elemento correspondente do tensor de saída.
Além disso, no método feedForward, o método ConvolutionForward descrito acima é usado. O código completo de todos os métodos e funções está disponível em anexo.
3.3. Retropropagação.
Como em todas as classes consideradas anteriormente, o processo de retropropagação contém dois subprocessos: propagação do gradiente de erro e atualização dos pesos. A primeira parte é implementada no método calcInputGradients. A segunda parte é implementada no updateInputWeights.
A construção do método calcInputGradients é semelhante à de feedForward. O método recebe nos parâmetros um ponteiro para a camada anterior da rede neural, à qual deve ser passado o gradiente de erro. Portanto, no início do método, verificamos a validade do ponteiro recebido.
bool CNeuronMLMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
Em seguida, nós fixamos o tensor do gradiente recebido da próxima camada de neurônios e organizamos um loop sobre todas as camadas internas para calcular sequencialmente o gradiente de erro. Como este é o processo de retropropagação, o loop irá iterar sobre as camadas internas em uma ordem reversa.
for(int i=(int)iLayers-1; (i>=0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),out_grad,FF_Tensors.At(i*6+1),FF_Tensors.At(i*6+4),4*iWindow,iWindow,None)) return false; CBufferDouble *temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+3); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(i*6+4),FF_Tensors.At(i*6),temp,iWindow,4*iWindow,LReLU)) return false;
No início do loop, calculamos a propagação do gradiente de erro através das camadas de neurônios totalmente conectadas do bloco Feed Forward do Transformer. Essa iteração é realizada pelo método ConvolutionInputGradients. Liberamos os buffers após a conclusão do método.
Como nosso algoritmo implementa o fluxo de dados em todo o processo, o mesmo processo deve ser implementado para o gradiente de erro. Assim, o gradiente de erro obtido do bloco Feed Forward é somado ao gradiente de erro recebido da camada anterior de neurônios. Para eliminar o risco de uma "explosão do gradiente", normalizamos a soma dos dois vetores. Todas essas operações são realizadas no método SumAndNormilize. Liberamos os buffers após a conclusão do método.
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; if(i!=(int)iLayers-1) out_grad.BufferFree(); out_grad=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+4); temp.BufferFree(); temp=FF_Tensors.At(i*6); temp.BufferFree();
Mais adiante no algoritmo, vamos dividir o gradiente de erro por cabeças de atenção. Isso é feito chamando o método ConvolutionInputGradients para a matriz W0.
//--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out_grad,AO_Tensors.At(i*2),AO_Tensors.At(i*2+1),iWindowKey*iHeads,iWindow,None)) return false; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=AO_Tensors.At(i*2); temp.BufferFree();
A propagação do gradiente adicional ao longo das cabeças de atenção é organizada no método AttentionInsideGradients.
if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i*2),QKV_Tensors.At(i*2+1),S_Tensors.At(i*2),S_Tensors.At(i*2+1),AO_Tensors.At(i*2+1))) return false; temp=QKV_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2+1); temp.BufferFree(); temp=AO_Tensors.At(i*2+1); temp.BufferFree();
No final do loop, nós calculamos o gradiente de erro passado para a camada anterior. Aqui, o gradiente de erro recebido da iteração anterior é passado através do tensor concatenado QKV_Weights e, em seguida, o vetor recebido é somado com o gradiente de erro do bloco Feed Forward do mecanismo de autoatenção e o resultado é normalizado para eliminar uma explosão nos gradientes.
CBufferDouble *inp=NULL; if(i==0) { inp=prevLayer.getOutput(); temp=prevLayer.getGradient(); } else { temp=FF_Tensors.At(i*6-1); inp=FF_Tensors.At(i*6-4); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(i*2+1),inp,temp,iWindow,3*iWindowKey*iHeads,None)) return false; //--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; out_grad.BufferFree(); if(i>0) out_grad=temp; temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(i*2+1); temp.BufferFree(); } //--- return true; }
Não se esqueça de liberar os buffers de dados usados. Preste atenção que a camada anterior dos buffers de dados é deixada na memória da GPU.
Vamos dar uma olhada nos métodos chamados. Como você pode ver, o método chamado com mais frequência é o ConvolutionInputGradients, que se baseia em um método semelhante ao da camada convolucional e é otimizado para a tarefa atual. O método recebe nos parâmetros os ponteiros para os tensores de pesos, do gradiente da próxima camada, dos dados de saída da camada anterior e do tensor para armazenar o resultado da iteração. Além disso, o método recebe nos parâmetros os tamanhos da janela de dados de entrada e saída e a função de ativação usada.
bool CNeuronMLMHAttentionOCL::ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(gradient)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(inp_gradient)==POINTER_INVALID) return false;
No início do método, verificamos a validade dos ponteiros recebidos e criamos buffers de dados na memória da GPU.
if(!weights.BufferCreate(OpenCL)) return false; if(!gradient.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!inp_gradient.BufferCreate(OpenCL)) return false;
Depois de criar os buffers de dados, implementamos a chamada do kernel do programa OpenCL apropriado. Aqui nós usamos um kernel de rede convolucional sem alterações.
//--- uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=inputs.Total(); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_g,gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_o,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_ig,inp_gradient.GetIndex()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_outputs,gradient.Total()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_step,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_in,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_out,window_out); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_activation,activ); //Comment(com+"\n "+(string)__LINE__+"-"__FUNCTION__); if(!OpenCL.Execute(def_k_CalcHiddenGradientConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel CalcHiddenGradientConv: %d",GetLastError()); return false; } //--- return inp_gradient.BufferRead(); }
O método AttentionInsideGradients, que também é chamado a partir do método ConvolutionInputGradients, é construído de acordo com um algoritmo semelhante. Por favor, veja em anexo para o código do método. Agora, vamos dar uma olhada no kernel do programa OpenCL chamado a partir do método especificado, porque todos os cálculos são executados no kernel.
O kernel MHAttentionInsideGradients é iniciado pelas threads em duas dimensões: elementos da sequência e cabeças de atenção. O kernel recebe nos parâmetros os ponteiros para o tensor QKV concatenado e o tensor de seus gradientes, os tensores da matriz Scores e seus gradientes, o tensor do gradiente de erro da iteração anterior e o tamanho do vetor de chaves.
__kernel void MHAttentionInsideGradients(__global double *qkv,__global double *qkv_g, __global double *scores,__global double *scores_g, __global double *gradient, int dimension) { int u=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1); double koef=sqrt((double)dimension); if(koef<1) koef=1;
No início do método, nós obtemos os números ordinais do elemento de sequência processado e a cabeça de atenção, bem como seus tamanhos. Além disso, nós calculamos o coeficiente de atualização da matriz de pontuação.
Em seguida, nós organizamos um loop para calcular o gradiente de erro para a matriz Scores. Ao definir uma barreira após o loop, nós podemos sincronizar o processo de computação em todos as threads. O algoritmo mudará para o próximo bloco de operações somente após o recálculo completo dos gradientes da matriz Scores.
//--- Calculating score's gradients uint shift_s=units*(h+u*heads); for(int v=0;v<units;v++) { double s=scores[shift_s+v]; if(s>0) { double sg=0; int shift_v=dimension*(h+heads*(3*v+2)); int shift_g=dimension*(h+heads*v); for(int d=0;d<dimension;d++) sg+=qkv[shift_v+d]*gradient[shift_g+d]; scores_g[shift_s+v]=sg*(s<1 ? s*(1-s) : 1)/koef; } else scores_g[shift_s+v]=0; } barrier(CLK_GLOBAL_MEM_FENCE);
Vamos implementar outro loop para calcular os gradientes de erro nos vetores queries, key e value.
//--- Calculating gradients for Query, Key and Value uint shift_qg=dimension*(h+3*u*heads); uint shift_kg=dimension*(h+(3*u+1)*heads); uint shift_vg=dimension*(h+(3*u+2)*heads); for(int d=0;d<dimension;d++) { double vg=0; double qg=0; double kg=0; for(int l=0;l<units;l++) { uint shift_q=dimension*(h+3*l*heads)+d; uint shift_k=dimension*(h+(3*l+1)*heads)+d; uint shift_g=dimension*(h+heads*l)+d; double sg=scores_g[shift_s+l]; kg+=sg*qkv[shift_q]; qg+=sg*qkv[shift_k]; vg+=gradient[shift_g]*scores[shift_s+l]; } qkv_g[shift_qg+d]=qg; qkv_g[shift_kg+d]=kg; qkv_g[shift_vg+d]=vg; } }
O código completo de todos os métodos e funções está disponível em anexo.
Os pesos são atualizados nos métodos updateInputWeights que são construídos pelos princípios dos métodos feedForward e calcInputGradients considerados anteriormente. Apenas um método auxiliar ConvolutuionUpdateWeights atualizando os pesos da rede convolucional é chamado sequencialmente dentro deste método.
bool CNeuronMLMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false; CBufferDouble *inputs=NeuronOCL.getOutput(); for(uint l=0; l<iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(l*2+1),inputs,(optimization==SGD ? QKV_Weights.At(l*2+1) : QKV_Weights.At(l*3+1)),(optimization==SGD ? NULL : QKV_Weights.At(l*3+2)),iWindow,3*iWindowKey*iHeads)) return false; if(l>0) inputs.BufferFree(); CBufferDouble *temp=QKV_Weights.At(l*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(l*2+1); temp.BufferFree(); if(optimization==SGD) { temp=QKV_Weights.At(l*2+1); } else { temp=QKV_Weights.At(l*3+1); temp.BufferFree(); temp=QKV_Weights.At(l*3+2); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)),FF_Tensors.At(l*6+3),AO_Tensors.At(l*2),(optimization==SGD ? FF_Weights.At(l*6+3) : FF_Weights.At(l*9+3)),(optimization==SGD ? NULL : FF_Weights.At(l*9+6)),iWindowKey*iHeads,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(l*6+3); temp.BufferFree(); temp=AO_Tensors.At(l*2); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+3); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+3); temp.BufferFree(); temp=FF_Weights.At(l*9+6); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(l*6+4),FF_Tensors.At(l*6),(optimization==SGD ? FF_Weights.At(l*6+4) : FF_Weights.At(l*9+4)),(optimization==SGD ? NULL : FF_Weights.At(l*9+7)),iWindow,4*iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(l*6+4); temp.BufferFree(); temp=FF_Tensors.At(l*6); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+4); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+4); temp.BufferFree(); temp=FF_Weights.At(l*9+7); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2),FF_Tensors.At(l*6+5),FF_Tensors.At(l*6+1),(optimization==SGD ? FF_Weights.At(l*6+5) : FF_Weights.At(l*9+5)),(optimization==SGD ? NULL : FF_Weights.At(l*9+8)),4*iWindow,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(l*6+5); if(temp!=Gradient) temp.BufferFree(); temp=FF_Tensors.At(l*6+1); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+5); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+5); temp.BufferFree(); temp=FF_Weights.At(l*9+8); temp.BufferFree(); } inputs=FF_Tensors.At(l*6+2); } //--- return true; }
O código completo de todas as classes e seus métodos está disponível no anexo.
3.4. Alterações nas Classes Base da Rede Neural
Como em todos os artigos anteriores, vamos fazer alterações na classe base depois de criar uma nova classe, para garantir o funcionamento adequado de nossa rede.
Vamos adicionar um novo identificador de classe.
#define defNeuronMLMHAttentionOCL 0x7889 ///<Multilayer multi-headed attention neuron OpenCL \details Identified class #CNeuronMLMHAttentionOCL
Além disso, no bloco define, nós adicionamos as constantes para trabalhar com os novos kernels do programa OpenCL.
#define def_k_MHAttentionScore 20 ///< Index of the kernel of the multi-heads attention neuron to calculate score matrix (#MHAttentionScore) #define def_k_mhas_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhas_score 1 ///< Matrix of Scores #define def_k_mhas_dimension 2 ///< Dimension of Key #define def_k_mhas_mask 3 ///< 1 - calc only previous units, 0 - calc all //--- #define def_k_MHAttentionOut 21 ///< Index of the kernel of the multi-heads attention neuron to calculate multi-heads out matrix (#MHAttentionOut) #define def_k_mhao_score 0 ///< Matrix of Scores #define def_k_mhao_qkv 1 ///< Matrix of Queries, Keys, Values #define def_k_mhao_out 2 ///< Matrix of Outputs #define def_k_mhao_dimension 3 ///< Dimension of Key //--- #define def_k_MHAttentionGradients 22 ///< Index of the kernel for gradients calculation process (#AttentionInsideGradients) #define def_k_mhag_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhag_qkv_g 1 ///< Matrix of Gradients to Queries, Keys, Values #define def_k_mhag_score 2 ///< Matrix of Scores #define def_k_mhag_score_g 3 ///< Matrix of Scores Gradients #define def_k_mhag_gradient 4 ///< Matrix of Gradients from previous iteration #define def_k_mhag_dimension 5 ///< Dimension of Key
Além disso, vamos adicionar a declaração de novos kernels no construtor de classe da rede neural.
//--- create kernels opencl.SetKernelsCount(23); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut");
E a criação de um novo tipo de neurônio no construtor da rede neural.
case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break;
Vamos também adicionar o processamento da nova classe de neurônios aos métodos de despacho da classe base de neurônios CNeuronBaseOCL.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; } bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; } //--- return false; } bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
O código completo de todas as classes e seus métodos está disponível no anexo.
4. Teste
Dois Expert Advisors foram criados para testar a nova arquitetura: Fractal_OCL_AttentionMLMH e Fractal_OCL_AttentionMLMH_v2. Esses EAs foram criados com base no EA do artigo anterior, apenas o bloco de atenção foi substituído. O EA Fractal_OCL_AttentionMLMH tem um bloco de 5 camadas com 8 cabeças de Self-Attention. O segundo EA usa um bloco de 12 camadas com 12 cabeças de Self-Attention.
A nova classe da rede neural foi testada no mesmo conjunto de dados, que foi usado nos testes anteriores: EURUSD com o intervalo de tempo H1, os dados históricos das últimas 20 velas são alimentadas na rede neural.
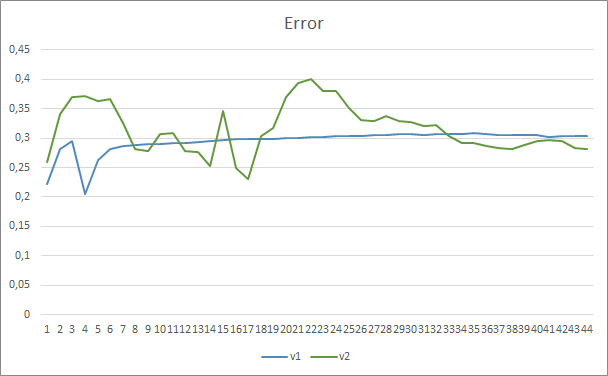
Os resultados do teste confirmaram a suposição de que mais parâmetros requerem um período de treinamento mais longo. Nas primeiras épocas de treinamento, um Expert Advisor com menos parâmetros mostra resultados mais estáveis. No entanto, conforme o período de treinamento é estendido, um Expert Advisor com muitos parâmetros mostram melhores valores. Em geral, após 33 épocas o erro do Fractal_OCL_AttentionMLMH_v2 diminuiu abaixo do nível de erro do EA Fractal_OCL_AttentionMLMH, e ainda permaneceu baixo.
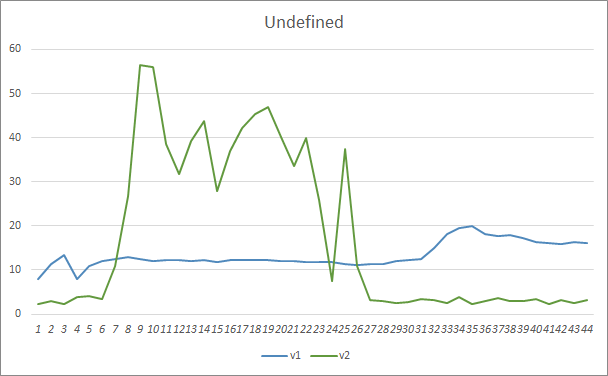
O parâmetro do padrão perdido mostrou resultados semelhantes. No início do treinamento, os parâmetros desbalanceados do EA Fractal_OCL_AttentionMLMH_v2 perdeu mais de 50% dos padrões. Porém, mais adiante, ao longo do treinamento, esse valor diminuiu e, após 27 épocas, ele se estabilizou em 3-5%, enquanto o EA com menos parâmetros mostrou resultados mais suaves, mas ao mesmo tempo perdeu 10-16% dos padrões.
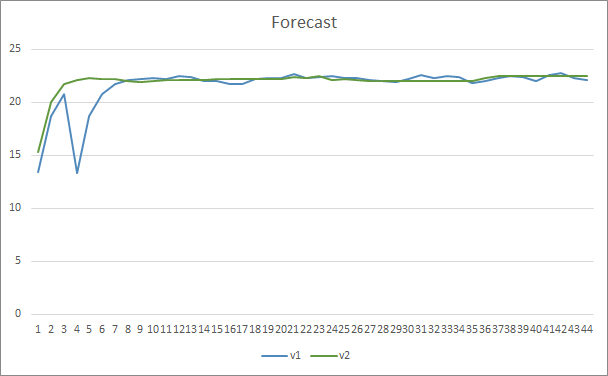
Em termos de precisão de predição de padrão, ambos os Expert Advisors mostraram resultados uniformes no nível de 22-23%.
Conclusão
Neste artigo, nós criamos uma nova classe de neurônios de atenção, semelhante às arquiteturas GPT apresentadas pela OpenAI. Obviamente, é impossível repetir e treinar essas arquiteturas em sua forma completa, porque seu treinamento e operação consomem tempo e recursos. No entanto, o objeto que criamos pode ser bem usado em redes neurais para fins de criação de robôs de negociação.
Referências
- Redes neurais de maneira fácil
- Redes neurais de maneira fácil (Parte 2): Treinamento e teste da rede
- Redes Neurais de Maneira Fácil (Parte 3): Redes Convolucionais
- Redes Neurais de Maneira Fácil (Parte 4): Redes Recorrentes
- Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
- Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural
- Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
- Redes Neurais de Maneira Fácil (Parte 8): Mecanismos de Atenção
- Redes Neurais de Maneira Fácil (Parte 9): Documentação do trabalho
- Redes neurais de maneira fácil (Parte 10): Atenção Multi-Cabeça
- Improving Language Understanding with Unsupervised Learning
- Better Language Models and Their Implications
- How GPT3 Works - Visualizations and Animations
…
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a arquitetura GTP, com 5 camadas de atenção |
| 2 | Fractal_OCL_AttentionMLMH_v2.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a arquitetura GTP, com 12 camadas de atenção |
| 3 | NeuroNet.mqh | Biblioteca de classe | Uma biblioteca de classes para a criação de uma rede neural |
| 4 | NeuroNet.cl | Código Base | Biblioteca do código do programa OpenCL |
| 5 | NN.chm | Ajuda HTML | Um arquivo CHM compilado. |