OpenCL: 병렬 세계로의 다리
Sceptic Philozoff | 5 8월, 2021
개요
이 문서는 OpenCL 또는 Open Computing Language의 프로그래밍에 대한 짧은 시리즈 간행물 중 첫 번째 문서입니다. OpenCL에 대한 지원을 제공하기 전에 현재의 MetaTrader 5 플랫폼은 컴퓨팅 속도를 높이기 위해 멀티 코어 프로세서의 장점을 직접 사용하고 즐기는 것을 허용하지 않았습니다.
분명히 개발자들은 단말기가 멀티스레딩되고 "모든 EA/스크립트가 별도의 스레드에서 실행된다"는 말을 끝없이 반복할 수 있었지만, 코더는 다음과 같은 단순 루프를 비교적 쉽게 병렬 실행할 기회가 주어지지 않았습니다(이것은 파이 값 = 3.149265...).
long num_steps = 1000000000; double step = 1.0 / num_steps; double x, pi, sum = 0.0; for (long i = 0; i<num_steps; i++) { x = (i + 0.5)*step; sum += 4.0/(1.0 + x*x); } pi = sum*step;
하지만 18개월 전까지만 해도 "병렬 연산 MetaTrader 5"이라는 제목의 매우 흥미로운 작품이 "기사" 섹션에 실렸습니다. 그런데도요...접근 방식의 독창성에도 불구하고 다소 부자연스럽다는 인상을 받게 됩니다. 위의 루프에서 계산을 가속화하기 위해 작성된 전체 프로그램 계층(Expert Advisor와 두 개의 지표)은 너무 좋은 일이었을 것입니다.
우리는 이미 OpenMP를 지원할 계획이 없으며, OMP를 추가하는 컴파일러의 과감한 재프로그래밍이 필요하다는 사실을 알고 있습니다. 생각할 필요가 없는 코더를 위한 저렴하고 쉬운 해결책은 없을 것입니다.
따라서 MQL5의 OpenCL에 대한 네이티브 지원 발표 는 매우 반가운 소식이었습니다. 동일한 뉴스 스레드의 22페이지부터 MetaDriver 는 CPU와 GPU의 구현 차이를 평가할 수 있는 스크립트를 게시하기 시작했습니다. OpenCL은 엄청난 관심을 불러일으켰습니다.
이 글의 작성자는 먼저 프로세스를 선택하지 않았습니다: 상당히 낮은 수준의 컴퓨터 구성(Pentium G840/8Gb DDR-III 1333/비디오 카드 없음)은 OpenCL의 효과적인 사용을 제공하지 않는 것 같습니다.
그러나 AMD에서 개발한 전문 소프트웨어인 AMD APP SDK를 설치한 후, 이산형 비디오 카드를 사용할 수 있는 경우에만 다른 사람에 의해 실행된 첫 번째 스크립트가 작성자의 컴퓨터에서 성공적으로 실행되었으며, 그에 비해 속도가 결코 작은 것이 아님을 입증했습니다.하나의 프로세서 코어에서 표준 스크립트 런타임이 약 25배 빨라집니다. 지원 팀의 도움으로 Intel OpenCL Runtime을 성공적으로 설치했기 때문에 나중에 동일한 스크립트 런타임의 가속도가 75에 도달했습니다.
저자는 ixbt.com에서 제공하는 포럼과 자료를 면밀히 검토한 결과 Intel의 Integrated Graphics Processor(IGP)가 Ivy Bridge 프로세서 이상에서만 OpenCL 1.1을 지원한다는 사실을 알게 되었습니다. 결과적으로, 위와 같은 구성의 PC에서 달성된 가속은 IGP와 아무런 관련이 없으며, 이 경우 OpenCL 프로그램 코드는 x86 코어 CPU에서만 실행되었습니다.
저자가 가속 수치를 ixbt 전문가와 공유하자 즉각적으로 이 모든 것이 소스 언어(MQL5)의 상당한 저최적화의 결과라고 대답했습니다. OpenCL 전문가 커뮤니티에서는 C++(물론 멀티 코어 프로세서 및 SSEx 벡터 명령 사용)에서 소스 코드를 올바르게 최적화하면 최상의 결과를 얻을 수 있으며, 최악의 경우 매우 높은 보류(시간) 상황 등으로 인해, 데이터를 전달할때, 손실도 발생할 수 있습니다.
따라서 - 또 다른 추정: 순수한 OpenCL 에뮬레이션에 대한 MetaTrader 5의 '기적의' 가속도는 OpenCL 자체의 "쿨함"에 기인하지 않고 적절히 처리되어야 합니다. C++의 최적화된 프로그램에 비해 GPU의 강력한 장점은 일부 알고리즘에서 GPU의 컴퓨팅 기능이 최신 CPU의 기능을 훨씬 능가하기 때문에 매우 강력한 별개의 비디오 카드를 사용해야만 얻을 수 있습니다.
터미널 개발자들은 아직 제대로 최적화되지 않았다고 말합니다. 또한 최적화 이후 여러 차례에 걸쳐 가속에 대한 힌트를 주었습니다. 따라서 OpenCL의 모든 가속 수치가 동일한 "몇 배"만큼 감소됩니다. 하지만, 그들은 여전히 통합보다 훨씬 더 클 것입니다.
진행하려는 OpenCL 언어(비디오 카드가 OpenCL 1.1을 지원하지 않거나 누락되어 있더라도)를 배우는 것이 좋습니다. 먼저 Open CL을 지원하는 소프트웨어 및 적절한 하드웨어와 같은 필수 기본에 대해 몇 가지 말씀드리겠습니다.
1. 필수 소프트웨어 및 하드웨어
1.1.AMD
이질적인 환경에서 컴퓨팅과 관련하여 서로 다른 언어 사양을 개발하는 비영리 산업 컨소시엄인 Khronos 그룹의 회원인 AMD, Intel 및 NVidia가 적절한 소프트웨어를 생산합니다.
몇 가지 유용한 자료는 Khronos 그룹의 공식 웹사이트에서 확인할 수 있습니다. 예를 들어 다음과 같습니다.
터미널에서 아직 OpenCL에 대한 도움말 정보를 제공하지 않으므로 OpenCL을 학습하는 과정에서 이러한 문서를 자주 사용해야 합니다(OpenCL API에 대한 간략한 요약만 있음). 세 회사(AMD, Intel 및 NVidia)는 모두 비디오 하드웨어 공급업체이며, 각 회사는 자체 OpenCL Runtime 구현 및 각 소프트웨어 개발 키트(SDK)를 보유하고 있습니다. 비디오 카드를 선택하는 특징, AMD 제품을 예로 들어 보겠습니다.
AMD 비디오 카드가 오래되지 않은 경우(2009-2010년 이상에 처음 생산 상태로 출시됨) 매우 간단합니다. 비디오 카드 드라이버를 업데이트하면 즉시 작동될 수 있습니다. OpenCL 호환 비디오 카드 목록은 여기서여기 확인할 수 있습니다. 반면, Radeon HD 4850(4870)과 같이 당대에 적합한 비디오 카드도 OpenCL을 처리할 때 문제를 덜 수 없습니다.
아직 AMD 비디오 카드가 없지만 구입할 수 있는 경우 먼저 사양을 확인하십시오. 여기서는 상당히 포괄적인 Modern AMD 비디오 카드 사양 표를 볼 수 있습니다. 우리에게 가장 중요한 것은 다음과 같습니다:
- 온-보드 메모리 — 로컬 메모리의 양. 크면 클수록 좋습니다. 보통 1GB면 충분합니다.
- 코어 클럭 — 코어 주파수를 작동. GPU 멀티프로세서의 작동 빈도가 높을수록 좋다는 점도 분명합니다. 650-700MHz는 전혀 나쁘지 않습니다.
- [메모리] 유형 — 비디오 메모리 유형. 메모리는 GDDR5와 같이 이상적으로 빨라야 합니다. 하지만 GDDR3 또한 메모리 대역폭 면에서 약 두 배 정도 더 나쁠 수 있습니다.
- [메모리] 클럭(Eff.) - 비디오 메모리의 작동(유효) 주파수. 기술적으로 이 파라미터는 이전 파라미터와 밀접한 관련이 있습니다. GDDR5 작동 유효 주파수는 평균적으로 GDDR3 주파수보다 두 배 높습니다. "높은" 메모리 유형이 더 높은 주파수에서 작동한다는 사실과는 무관하지만, 메모리에서 사용하는 데이터 전송 채널의 수 때문입니다. 즉, 메모리 대역폭과 관련이 있습니다.
- [메모리] 버스 - 버스 데이터 폭. 256비트 이상을 사용하는 것이 좋습니다.
- MBW — 메모리 대역폭. 이 매개변수는 실제로 위의 세 가지 비디오 메모리 매개변수의 조합입니다. 높을수록 좋습니다.
- 구성 코어 (SPU:TMU(TF):ROP) — GPU 구성 코어 유닛. 우리에게 중요한 것, 즉 비시각적 계산은 첫 번째 숫자입니다. 1024:64:32 1024(통합 스트리밍 프로세서 또는 셰이더의 수)가 필요하다는 것을 의미합니다. 높을수록 좋은 게 분명합니다.
- 처리 전력 — 부동 소수점 계산에서 이론적인 성능 (FP32 (단일 정밀도) / FP64 (이중 정밀도). 사양 테이블에는 항상 FP32(모든 비디오 카드가 단일 정밀 계산을 처리할 수 있음)에 해당하는 값이 포함되어 있지만, FP64의 경우 모든 비디오 카드에서 이중 정밀도를 지원하지 않기 때문에 이와는 거리가 멉니다. GPU 계산에서 이중 정밀도(이중 유형)가 필요하지 않은 경우 두 번째 매개 변수를 무시할 수 있습니다. 하지만 어떤 경우든 이 매개변수가 높을수록 좋습니다.
- TDP — 열 설계 전력. 이는 대략적으로 말해서 비디오 카드가 가장 어려운 계산에서 소모하는 최대 전력입니다. Expert Advisor가 GPU에 자주 액세스하는 경우 비디오 카드는 많은 전력을 소비할 뿐만 아니라 상당한 소음이 발생할 수 있습니다.
두 번째 경우: 비디오 카드가 없거나 기존 비디오 카드가 OpenCL 1.1을 지원하지 않지만 AMD 프로세서가 있습니다. 여기 런타임 외에도 SDK, 커널 분석기 및 프로파일러를 포함하는 AMD APP SDK를 다운로드할 수 있습니다. AMD APP SDK를 설치한 후에는 프로세서가 OpenCL 디바이스로 인식되어야 합니다. 또한 CPU의 에뮬레이션 모드에서 모든 기능을 갖춘 OpenCL 애플리케이션을 개발할 수 있습니다.
AMD와 달리 SDK의 주요 기능은 Intel 프로세서와도 호환된다는 것입니다 (Intel CPU를 개발할 때 네이티브 SDK는 최근에야 AMD 프로세서에서 사용할 수 있게 된 SSE 4.1, SSE 4.2 및 AVX 명령 집합을 지원할 수 있기 때문에 훨씬 더 효율적입니다).
1.2. Intel
Intel 프로세서에서 작업하기 전에Intel OpenCL SDK/Runtime을 다운로드하는 것이 좋습니다.
우리는 다음을 주목해야 합니다.
- CPU(OpenCL 에뮬레이션 모드)만 사용하여 OpenCL 애플리케이션을 개발하려는 경우 Intel CPU 그래픽 커널이 Sandy Bridge보다 오래된 프로세서에 대해 OpenCL 1.1을 지원하지 않습니다. 이 지원은 Ivy Bridge 프로세서에서만 사용할 수 있지만 초강력 Intel HD 4000 통합 그래픽 유닛에서도 거의 차이가 없습니다. Ivy Bridge보다 오래된 프로세서의 경우, 이는 MQL5 환경에서 달성되는 가속도가 사용되는 SS(S)Ex 벡터 명령에만 기인한다는 것을 의미합니다. 하지만 그것 또한 중요한 것으로 보입니다.
- Intel OpenCL SDK를 설치한 후, 레지스트리 항목HKEY_LOCAL_MACHINE\SOFTWARE\Khronos\OpenCL\Vendors은 다음과 같이 수정해야 합니다: 네임 칼럼IntelOpenCL64.dll 을 intelocl.dll으로 변경합니다. 그런 다음 재부팅하고 MetaTrader 5를 시작합니다. 이제 CPU가 OpenCL 1.1 장치로 인식됩니다.
솔직히 Intel의 OpenCL 지원 문제는 아직 완전히 해결되지 않았기 때문에 향후 터미널 개발자들로부터 몇 가지 명확한 설명을 기대할 수 있습니다. 기본적으로, 아무도 커널 코드 오류(OpenCL 커널은 GPU에서 실행되는 프로그램)를 감시하지 않는다는 것입니다. MQL5 컴파일러는 아닙니다. 컴파일러는 커널의 전체 큰 줄을 가져와서 실행하려고 할 뿐입니다. 예를 들어 커널에서 사용되는 일부 내부 변수 х 을 선언하지 않은 경우에도 커널은 오류가 발생하더라도 기술적으로 계속 실행됩니다.
그러나 터미널에서 발생하는 모든 오류는 도움말에 설명된 API OpenCL, CLKernelCreate() 그리고 CLProgramCreate()의 오류 중 12개 미만으로 요약됩니다. 언어 구문은 벡터 함수와 데이터 유형으로 강화된 C와 매우 유사합니다 (1999년에 ANSI С 표준으로 채택된 C99 언어입니다).
이 글의 작성자가 OpenCL의 코드를 디버그하는 데 사용하는 것은 Intel OpenCL SDK 오프라인 컴파일러입니다. MetaEditor에서 커널 오류를 무작정 검색하는 것보다 훨씬 편리합니다. 바라건대, 미래에는 상황이 더 좋게 변하기를 바랍니다.
1.3. NVidia
안타깝게도 저자는 이 주제에 대한 정보를 검색하지 않았습니다. 그럼에도 불구하고 일반적인 권고사항은 그대로 유지됩니다. 새 NVidia 비디오 카드용 드라이버는 OpenCL을 자동으로 지원합니다.
기본적으로 이 글의 작성자는 NVidia 비디오 카드에 대해 반대하지 않지만, 정보와 포럼 토론을 통해 얻은 지식을 바탕으로 도출한 결론은 다음과 같습니다. 그래픽이 아닌 계산의 경우 AMD 비디오 카드가 NVidia 비디오 카드보다 가격 대비 성능 면에서 더 최적인 것으로 보입니다.
이제 프로그래밍으로 이동하겠습니다.
2. OpenCL을 사용한 첫 번째 MQL5 프로그램
우리의 첫 번째, 매우 간단한 프로그램을 개발하기 위해서는, 우리는 그 과제를 정의해야 합니다. 병렬 프로그래밍 과정에서는 약 3.14159265와 동일한 pi 값을 계산하는 것이 예로서 관례가 되었을 것입니다.
이를 위해 다음 공식이 사용됩니다(작성자는 이 특정 공식을 접한 적이 없지만 사실인 것 같음).

우리는 소수점 12자리까지 정확하게 값을 계산하고 싶습니다. 기본적으로 이러한 정밀도는 약 100만 번의 반복으로 얻을 수 있지만, GPU 계산 기간이 너무 짧아 OpenCL에서 계산의 이점을 평가할 수 없습니다.
GPGPU 프로그래밍 과정에서는 GPU 작업 기간이 20밀리초 이상이 되도록 계산량을 선택할 것을 권장합니다. 이 경우, 100ms에 버금가는 GetTickCount() 함수의 심각한 오류로 인해 이 제한을 더 높게 설정해야 합니다.
다음은 이 계산이 구현되는 MQL5 프로그램입니다:
//+------------------------------------------------------------------+ //| pi.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" long _num_steps = 1000000000; long _divisor = 40000; double _step = 1.0 / _num_steps; long _intrnCnt = _num_steps / _divisor; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { uint start,stop; double x,pi,sum=0.0; start=GetTickCount(); //--- first option - direct calculation for(long i=0; i<_num_steps; i++) { x=(i+0.5)*_step; sum+=4.0/(1.+x*x); } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); //--- calculate using the second option start=GetTickCount(); sum=0.; long divisor=40000; long internalCnt=_num_steps/divisor; double partsum=0.; for(long i=0; i<divisor; i++) { partsum=0.; for(long j=i*internalCnt; j<(i+1)*internalCnt; j++) { x=(j+0.5)*_step; partsum+=4.0/(1.+x*x); } sum+=partsum; } pi=sum*_step; stop=GetTickCount(); Print("The value of PI is "+DoubleToString(pi,12)); Print("The time to calculate PI was "+DoubleToString(( stop-start)/1000.0,3)+" seconds"); Print("_______________________________________________"); return(0); } //+------------------------------------------------------------------+이 스크립트를 컴파일하여 실행하면 다음과 같은 이점이 있습니다.
2012.05.03 02:02:23 pi (EURUSD,H1) The time to calculate PI was 8.783 seconds 2012.05.03 02:02:23 pi (EURUSD,H1) The value of PI is 3.141592653590 2012.05.03 02:02:15 pi (EURUSD,H1) The time to calculate PI was 7.940 seconds 2012.05.03 02:02:15 pi (EURUSD,H1) The value of PI is 3.141592653590
pi 값 ~ 3.14159265는 약간 다른 두 가지 방법으로 계산됩니다.
첫 번째 방법은 OpenMP, Intel TPP, Intel MKL 등과 같은 다중 스레드 라이브러리의 기능을 시연하는 고전적인 방법이라고 할 수 있습니다.
두 번째 계산은 이중 루프 형태로 동일한 계산입니다. 10억 번의 반복으로 구성된 전체 계산은 외부 루프의 큰 블록(이 중 40000개가 있음)으로 나누어지며, 모든 블록이 내부 루프를 구성하는 25000개의 "기본" 반복을 실행합니다.
계산이 10~15% 더 느리게 실행됨을 알 수 있습니다. 하지만 OpenCL로 전환할 때 기준으로 사용할 계산은 바로 이 계산입니다. 주요 이유는 한 메모리 영역에서 다른 영역으로 데이터를 전송하는 데 소요된 시간과 커널에서 실행되는 데이터 계산 사이의 적절한 절충을 수행하는 커널(GPU에서 실행되는 기본 컴퓨팅 작업) 선택입니다. 따라서 현재 작업 측면에서 커널은 대략적으로 두 번째 계산 알고리즘의 내부 루프가 됩니다.
이제 OpenCL을 사용하여 값을 계산하겠습니다. 전체 프로그램 코드 뒤에 OpenCL에 바인딩된 호스트 언어(MQL5)의 기능 특성에 대한 짧은 설명이 나옵니다. 그러나 먼저 OpenCL의 코딩에 방해가 될 수 있는 일반적인 "장애물"과 관련된 몇 가지 사항을 강조하고자 합니다.
- 커널 외부에 선언된 변수가 커널에 표시되지 않습니다. 그렇기 때문에 전역 변수 _step and _intrnCnt 를 커널 코드의 시작 부분에 다시 선언해야 했습니다(아래 참조). 그리고 커널 코드에서 제대로 읽으려면 각각의 값을 문자열로 변환해야 했습니다. 그러나, OpenCL에서 프로그래밍의 이러한 특수성은 나중에, 예를 들어 C에 기본적으로 없는 벡터 데이터 유형을 만들 때 매우 유용하다는 것이 입증되었습니다.
- 커널의 수를 합리적으로 유지하면서 가능한 많은 계산을 제공하십시오. 기존 하드웨어에서 커널이 이 코드의 속도가 그다지 빠르지 않기 때문에 이 코드에 대해서는 그다지 중요하지 않습니다. 그러나 이 요소는 강력한 이산형 비디오 카드를 사용하는 경우 계산 속도를 높이는 데 도움이 됩니다.
다음은 OpenCL 커널이 포함된 스크립트 코드입니다.
//+------------------------------------------------------------------+ //| OCL_pi_float.mq5 | //+------------------------------------------------------------------+ #property copyright "Copyright (c) 2012, Mthmt" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs; input int _device=0; /// OpenCL device number (0, I have CPU) #define _num_steps 1000000000 #define _divisor 40000 #define _step 1.0 / _num_steps #define _intrnCnt _num_steps / _divisor string d2s(double arg,int dig) { return DoubleToString(arg,dig); } string i2s(int arg) { return IntegerToString(arg); } const string clSrc= "#define _step "+d2s(_step,12)+" \r\n" "#define _intrnCnt "+i2s(_intrnCnt)+" \r\n" " \r\n" "__kernel void pi( __global float *out ) \r\n" // type float "{ \r\n" " int i = get_global_id( 0 ); \r\n" " float partsum = 0.0; \r\n" // type float " float x = 0.0; \r\n" // type float " long from = i * _intrnCnt; \r\n" " long to = from + _intrnCnt; \r\n" " for( long j = from; j < to; j ++ ) \r\n" " { \r\n" " x = ( j + 0.5 ) * _step; \r\n" " partsum += 4.0 / ( 1. + x * x ); \r\n" " } \r\n" " out[ i ] = partsum; \r\n" "} \r\n"; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ int OnStart() { Print("FLOAT: _step = "+d2s(_step,12)+"; _intrnCnt = "+i2s(_intrnCnt)); int clCtx=CLContextCreate(_device); int clPrg = CLProgramCreate( clCtx, clSrc ); int clKrn = CLKernelCreate( clPrg, "pi" ); uint st=GetTickCount(); int clMem=CLBufferCreate(clCtx,_divisor*sizeof(float),CL_MEM_READ_WRITE); // type float CLSetKernelArgMem(clKrn,0,clMem); const uint offs[ 1 ] = { 0 }; const uint works[ 1 ] = { _divisor }; bool ex=CLExecute(clKrn,1,offs,works); //--- Print( "CL program executed: " + ex ); float buf[]; // type float ArrayResize(buf,_divisor); uint read=CLBufferRead(clMem,buf); Print("read = "+i2s(read)+" elements"); float sum=0.0; // type float for(int cnt=0; cnt<_divisor; cnt++) sum+=buf[cnt]; float pi=float(sum*_step); // type float Print("pi = "+d2s(pi,12)); CLBufferFree(clMem); CLKernelFree(clKrn); CLProgramFree(clPrg); CLContextFree(clCtx); double gone=(GetTickCount()-st)/1000.; Print("OpenCl: gone = "+d2s(gone,3)+" sec."); Print("________________________"); return(0); } //+------------------------------------------------------------------+
스크립트 코드에 대한 자세한 설명은 잠시 후에 드리겠습니다.
그 동안 프로그램을 컴파일하고 시작하여 다음 정보를 얻으십시오:
2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) ________________________ 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) OpenCl: gone = 5.538 sec. 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) pi = 3.141622066498 2012.05.03 02:20:20 OCl_pi_float (EURUSD,H1) read = 40000 elements 2012.05.03 02:20:15 OCl_pi_float (EURUSD,H1) FLOAT: _step = 0.000000001000; _intrnCnt = 25000
보시다시피 런타임이 약간 줄었습니다. 그러나 이것은 우리를 행복하게 하기에는 충분하지 않습니다: pi ~ 3.14159265의 값은 분명히 소수점 뒤의 세 번째 자리까지만 정확합니다. 이러한 계산의 복잡함은 실제 계산에서 커널이 부동 소수점 이하 12자리까지 정확하게 필요한 정밀도보다 확실히 낮은 정확도 유형의 숫자를 사용하기 때문입니다.
MQL5 Documentation 설명서에 따르면, 플로트 유형 번호의 정밀도는 7개의 유의한 숫자로만 정확합니다. 반면 이중 유형 숫자의 정밀도는 15개의 유의한 숫자로 정확합니다.
따라서 실제 데이터 유형을 "더 정확하게" 만들어야 합니다. 위의 코드에서 float type을 double type으로 대체해야 하는 행은 comment ///type float로 표시됩니다. 동일한 입력 데이터를 사용하여 컴파일하면 다음 파일(소스 코드가 OCL_pi_double.mq5 인 새 파일)이 표시됩니다.
2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) OpenCl: gone = 12.480 sec. 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:25:35 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.03 03:25:23 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
실행 시간이 상당히 증가했으며 OpenCL 없이 소스 코드의 시간(8.783초)을 초과했습니다.
"확실히 계산을 느리게 하는 것은 이중 유형입니다."라고 생각할 것입니다. 하지만 실험해 보고 입력 매개변수 _divisor를 40000에서 40000000으로 크게 변경해 보겠습니다:
2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) OpenCl: gone = 5.070 sec. 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.03 03:26:55 OCL_pi_double (EURUSD,H1) read = 40000000 elements 2012.05.03 03:26:50 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25
플로트 타입의 경우보다 정확성을 저하시키지 않았으며 런타임도 약간 짧아졌습니다. 그러나 모든 정수 유형을 long에서 int로 변경하고 _divisor = 40000의 이전 값을 복원하면 커널 런타임이 절반 이상 줄어듭니다.
2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) ________________________ 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) OpenCl: gone = 2.262 sec. 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) pi = 3.141592653590 2012.05.16 00:22:46 OCL_pi_double (EURUSD,H1) read = 40000 elements 2012.05.16 00:22:44 OCL_pi_double (EURUSD,H1) DOUBLE: _step = 0.000000001000; _intrnCnt = 25000
항상 기억해야 할 점은 "길지만" "가벼운" 루프(즉, 각 루프마다 많은 반복으로 구성된 루프)가 있는 경우, 데이터 유형이 "무거운" 루프(긴 유형 - 8바이트)에서 "가벼운" 루프(int - 4바이트)로 변경되는 것만으로도 커널 런타임이 크게 감소할 수 있다는 것입니다.
잠시 프로그래밍 실험을 중단하고 커널 코드의 전체 "바인딩"의 의미에 초점을 맞춰 우리가 무엇을 하고 있는지 알아보도록 하겠습니다. 커널 코드 "바인딩"은 일시적으로 커널이 호스트 프로그램과 통신할 수 있는 명령 시스템(이 경우 MQL5의 프로그램과)을 의미합니다.
3. OpenCL API 함수
3.1. 컨텍스트 생성
아래 명령은 OpenCL 개체 및 리소스 관리를 위한 컨텍스트를 생성합니다.
int clCtx = CLContextCreate( _device ); 먼저 플랫폼 모델에 대해 몇 마디 하겠습니다.
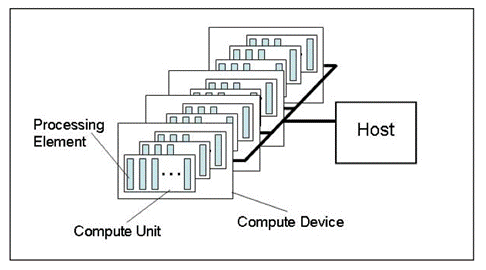
그림 1. 컴퓨팅 플랫폼의 추상적 모델
이 그림은 컴퓨팅 플랫폼의 추상적 모델을 보여줍니다. 그것은 비디오 카드와 관련된 하드웨어의 구조를 아주 상세하게 묘사한 것은 아니지만, 현실에 상당히 가깝고 전반적으로 좋은 아이디어를 줍니다.
호스트는 전체 프로그램 실행 프로세스를 제어하는 기본 CPU입니다. 일부 OpenCL 장치(컴퓨팅 장치)를 인식할 수 있습니다. 대부분의 경우 거래자가 시스템 유닛에서 사용할 수 있는 계산용 비디오 카드를 가지고 있는 경우 비디오 카드를 하나의 장치로 간주합니다(듀얼 프로세서 비디오 카드는 두 개의 장치로 간주됨!). 그 외에도, 호스트 자체, 즉 CPU는 항상 OpenCL 디바이스로 간주됩니다. 모든 장치에는 플랫폼 내 고유 번호가 있습니다.
모든 장치에는 CPU가 x86 코어( Intel CPU "가상의" 코어, 즉, 하이퍼-스레딩을 통해 생성된 "코어")에 해당하는 여러 컴퓨팅 장치가 있습니다. 비디오 카드의 경우 SIMD 엔진이 됩니다. 즉, GPU 컴퓨팅에 관한 SIMD 코어 또는 미니 프로세서). AMD/ATI Radeon 아키텍처 기능. 강력한 비디오 카드에는 일반적으로 약 20개의 SIMD 코어가 있습니다.
모든 SIMD 코어에는 스트림 프로세서가 들어 있습니다. 예를 들어 Radeon HD 5870 비디오 카드에는 모든 SIMD 엔진에 16개의 스트림 프로세서가 있습니다.
마지막으로, 모든 스트림 프로세서에는 동일한 카드에 4개 또는 5개의 처리 요소(ALU)가 있습니다.
하드웨어에 대해 모든 주요 그래픽 공급업체가 사용하는 용어는 특히 초보자에게 상당히 혼란스러운 용어입니다. OpenCL에 관한 포럼 스레드에서 흔히 사용되는 "bees"가 무엇을 의미하는지 항상 분명한 것은 아닙니다. 그럼에도 불구하고, 현대 비디오 카드의 동시 연산 스레드 수는 매우 많습니다. 예를 들어 Radeon HD 5870 비디오 카드의 예상 스레드 수는 5,000개가 넘습니다.
아래 그림은 이 비디오 카드의 표준 기술 사양을 보여줍니다.

그림. 2. Radeon HD 5870 GPU 기능
아래에 지정된 모든 내용(OpenCL 리소스)은 반드시 CLContextCreate() 함수에서 만든 컨텍스트와 연관되어야 합니다.
- OpenCL 장치, 즉 계산에 사용되는 하드웨어입니다.
- 프로그램 객체, 즉 커널을 실행하는 프로그램 코드입니다.
- 커널, 즉 함수는 장치에서 실행됩니다;
- 장치가 조작하는 메모리 객체(예: 버퍼, 2D 및 3D 이미지)입니다;
- 명령 대기열(현재 터미널 언어의 구현에서는 해당 API를 제공하지 않습니다).
생성된 컨텍스트는 아래에 장치가 연결된 빈 필드로 표시될 수 있습니다.
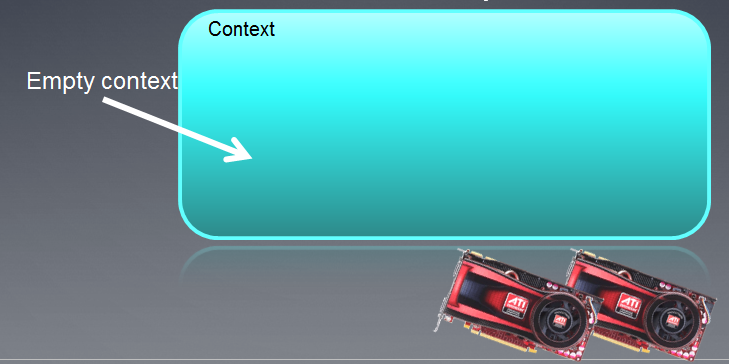
그림 3. OpenCL 컨텍스트
함수를 실행한 후 컨텍스트 필드가 현재 비어 있습니다.
MQL5의 OpenCL 컨텍스트는 하나의 디바이스에서만 작동합니다.
3.2. 프로그램 생성
int clPrg = CLProgramCreate( clCtx, clSrc ); CLProgramCreate() 함수는 리소스 "OpenCL 프로그램"을 생성합니다.
개체 "Program"은 실제로 OpenCL 커널 모음이지만(다음 절에서 설명하기로 함) MetaQuotes 구현에서는 OpenCL 프로그램에 커널이 하나만 있을 수 있습니다. "Program" 개체를 만들려면 소스 코드(여기 - clSrc)를 문자열로 읽어야 합니다.
이 경우 clSrc 문자열이 이미 전역 변수로 선언되었으므로 필요하지 않습니다.

아래 그림은 프로그램이 이전에 작성된 컨텍스트의 일부임을 보여줍니다.

그림 4. 프로그램은 컨텍스트의 일부입니다.
프로그램을 컴파일하지 못한 경우 개발자는 컴파일러 출력 시 데이터 요청을 독립적으로 시작해야 합니다. 완전한 기능을 갖춘 OpenCL API에는 컴파일러 출력 시 문자열이 반환되는 clGetProgramBuildInfo() 라는 API 함수가 있습니다.
현재 버전(b.642)에서는 이 기능을 지원하지 않으므로 OpenCL 개발자에게 커널 코드 정확성에 대한 자세한 정보를 제공하기 위해 OpenCL API에 포함할 가치가 있습니다.
장치(비디오 카드)에서 나오는 "Tongues"는 API 수준의 MQL5에서 지원되지 않을 것으로 보이는 명령 대기열입니다.
3.3. 커널 생성
CLKernelCreate() 함수는 OpenCL 리소스 "Kernel"(커널)을 생성합니다.
int clKrn = CLKernelCreate( clPrg, "pi" );
커널은 OpenCL 장치에서 실행되는 프로그램에 선언된 함수입니다.
우리의 경우, "pi"라는 이름의 pi() 함수입니다. 개체 "커널"은 해당 인수와 함께 커널의 함수입니다. 이 함수의 두 번째 인수는 프로그램 내 함수 이름과 정확히 일치해야 하는 함수 이름입니다.

그림 5. 커널
커널로 선언된 동일한 함수에 대해 서로 다른 인수를 설정할 때 필요한 횟수만큼 개체 "커널"을 사용할 수 있습니다.
이제 CLSetKernelArg() 과 CLSetKernelArgMem() 함수로 이동하여 디바이스 메모리에 저장된 개체에 대해 몇 마디 살펴보겠습니다.
3.4. 메모리 개체
우선 GPU에서 처리되는 모든 "큰" 객체는 GPU 자체의 메모리에서 생성되거나 호스트 메모리(RAM)에서 이동되어야 한다는 점을 이해해야 합니다. "큰" 객체는 버퍼(1차원 배열) 또는 2차원 또는 3차원(2D 또는 3D)일 수 있는 이미지를 의미합니다.
버퍼는 별도의 인접 버퍼 요소를 포함하는 넓은 메모리 영역입니다. 단순 데이터 유형(문자, 이중, 부동, 길이 등) 또는 복합 데이터 유형(구조, 유니언 등)일 수 있습니다. 별도의 버퍼 요소에 직접 액세스, 읽기 및 쓰기가 가능합니다.
현재로서는 특이한 데이터 유형이기 때문에 이미지를 조사하지 않을 것입니다. OpenCL에 대한 스레드의 첫 페이지에 터미널 개발자들이 제공한 코드를 보면 개발자들이 이미지 사용에 관여하지 않았음을 알 수 있습니다.
소개된 코드에서 버퍼를 만드는 함수는 다음과 같습니다:
int clMem = CLBufferCreate( clCtx, _divisor * sizeof( double ), CL_MEM_READ_WRITE );
첫 번째 매개 변수는 OpenCL 버퍼가 리소스로 연결된 컨텍스트 핸들이고, 두 번째 매개 변수는 버퍼에 할당된 메모리이며, 세 번째 매개 변수는 이 개체로 수행할 수 있는 작업을 보여줍니다. 반환된 값은 OpenCL 버퍼에 대한 핸들(만들기 성공한 경우) 또는 -1(오류로 인해 생성에 실패한 경우)입니다.
우리의 경우, 버퍼는 GPU의 메모리에서 직접 생성되었습니다. 즉, OpenCL 장치를 엽니다. 이 기능을 사용하지 않고 RAM에서 생성된 경우 아래 그림과 같이 OpenCL 장치 메모리(GPU)로 이동해야 합니다.

그림 6. OpenCL 메모리 개체
왼쪽에는 OpenCL 메모리 객체가 아닌 입출력 버퍼(반드시 이미지 - 모나리자는 그림 목적으로만 존재합니다!)가 표시됩니다. 초기화되지 않은 빈 OpenCL 메모리 개체는 메인 컨텍스트 필드에 오른쪽에 더 많이 표시됩니다. 초기 데이터"모나리자"는 그 후에 OpenCL 컨텍스트 필드에 옮겨지고, OpenCL 프로그램의 아웃풋이 무엇이든 왼쪽으로 다시 옮기고, 즉 램으로 이동하는 것이 필요할 것이다.
OpenCL에 관하여, host/OpenCL 장치로 또는 거기서 데이터를 복사하는 데 사용되는 용어는 다음과 같습니다:
- 호스트에서 장치 메모리로 데이터를 복사하는 것을 writing (CLBufferWrite() 함수) 라고 합니다.
- 장치 메모리에서 호스트 메모리로 데이터를 복사하는 것을 reading (CLBufferRead() 함수, 아래 참조) 라고 합니다.
쓰기 명령(host -> device)은 데이터별로 메모리 개체를 초기화하는 동시에 장치 메모리에 개체를 배치합니다.
장치에서 사용할 수 있는 메모리 개체의 유효성은 장치에 해당하는 하드웨어 공급업체에 따라 다르기 때문에 OpenCL 규격에 명시되어 있지 않습니다. 따라서 메모리 개체를 만들 때는 주의해야 합니다.
메모리 개체를 초기화하고 장치에 쓴 후 그림은 다음과 같습니다.

그림 7. OpenCL 메모리 개체의 초기화 결과
이제 커널의 매개 변수를 설정하는 기능으로 진행할 수 있습니다.
3.5. 커널의 매개 변수를 설정
CLSetKernelArgMem( clKrn, 0, clMem ); CLSetKernelArgMem() 함수는 이전에 만든 버퍼를 커널의 0 매개 변수로 정의합니다.
커널 코드에서 동일한 매개 변수를 살펴보면 다음과 같이 나타납니다:
__kernel void pi( __global float *out )
커널에서 API 함수 CLBufferCreate()에서 만든 것과 동일한 유형의 out[ ] 어레이입니다.
비 버퍼 매개 변수를 설정하는 것과 유사한 기능이 있습니다.
bool CLSetKernelArg( int kernel, // handle to the kernel of the OpenCL program uint arg_index, // OpenCL function argument number void arg_value ); // function argument value
예를 들어 double x0을 커널의 두 번째 매개 변수로 설정하기로 결정했다면 먼저 MQL5 프로그램에서 선언하고 초기화해야 합니다.
double x0 = -2;
그런 다음 함수를 호출해야 합니다(MQL5 코드에서도):
CLSetKernelArg( cl_krn, 1, x0 ); 위의 조작에 따라 그림은 다음과 같습니다:

그림 8. 커널의 매개 변수 설정 결과
3.6. 프로그램 실행
bool ex = CLExecute( clKrn, 1, offs, works );
작성자는 OpenCL 사양에서 이 기능의 직접적인 아날로그를 찾지 못했습니다. 함수는 지정된 매개 변수를 사용하여 커널 clKrn을 실행합니다. 마지막 매개 변수 'works'는 컴퓨팅 작업의 모든 계산에 대해 실행할 태스크 수를 설정합니다. 이 함수는 SPMD(Single Program Multiple Data) 원칙을 보여줍니다. 함수 호출 한 번으로 작업 매개 변수 값과 동일한 수의 자체 매개 변수를 사용하여 커널 인스턴스가 생성됩니다. 이러한 커널 인스턴스는 일반적으로 AMD 용어로 서로 다른 스트림 코어에서 동시에 실행됩니다.
OpenCL의 일반성은 언어가 코드 실행과 관련된 기본 하드웨어 인프라에 바인딩되어 있지 않다는 사실로 구성됩니다. 즉, 코더가 OpenCL 프로그램을 제대로 실행하기 위해 하드웨어 사양을 알 필요가 없습니다. 계속 실행됩니다. 그러나 코드의 효율성을 높이기 위해서는 이러한 사양을 아는 것이 좋습니다(예: 속도).
예를 들어, 이 코드는 별도의 비디오 카드가 없는 작성자의 하드웨어에서 정상적으로 실행됩니다. 즉, 저자는 전체 에뮬레이션이 수행되는 CPU의 구조에 대해 매우 모호하게 알고 있습니다.
그래서, OpenCL 프로그램이 드디어 실행되었고, 그 결과를 호스트 프로그램에 활용할 수 있게 되었습니다.
3.7. 출력 데이터 일기
다음은 디바이스에서 데이터를 읽는 호스트 프로그램의 일부입니다.
float buf[ ]; ArrayResize( buf, _divisor ); uint read = CLBufferRead( clMem, buf );
OpenCL에서 데이터를 읽으면 이 데이터가 디바이스에서 호스트로 복사됩니다. 이 세 줄은 어떻게 하는지를 보여줍니다. 메인 프로그램의 읽기 OpenCL 버퍼와 동일한 유형의 buf[] 버퍼를 선언하고 함수를 호출하면 충분합니다. 호스트 프로그램에서 생성된 버퍼 유형(여기서 MQL5 언어)은 커널에 있는 버퍼 유형과 다를 수 있지만 크기는 정확히 일치해야 합니다.
이제 데이터가 호스트 메모리에 복사되어 기본 프로그램(예: MQL5의 프로그램) 내에서 완전히 사용할 수 있습니다.
OpenCL 장치에서 필요한 모든 계산을 수행한 후에는 메모리를 모든 개체에서 분리해야 합니다.
3.8. 모든 OpenCL 개체 삭제
이 작업은 다음 명령을 사용하여 수행됩니다.
CLBufferFree( clMem ); CLKernelFree( clKrn ); CLProgramFree( clPrg ); CLContextFree( clCtx );
이러한 일련의 기능의 주요 특징은 객체가 생성 순서대로 파괴되어야 한다는 것입니다.
이제 커널 코드 자체에 대해 잠시 살펴보겠습니다.
3.9. 커널
보시다시피 전체 커널 코드는 여러 문자열로 구성된 하나의 긴 문자열입니다.
커널 헤더는 표준 함수처럼 보입니다:
__kernel void pi( __global float *out )
커널 헤더에 대한 몇 가지 요구 사항이 있습니다:
- 반환된 값의 유형은 항상 유효하지 않습니다;
- The specifier __kernel 에는 두 개의 밑줄 문자가 포함될 필요가 없으며 커널일 수도 있습니다;
- 인수가 배열(버퍼)인 경우 참조로만 전달됩니다. Memory specifier __global (or global) 은 이 버퍼가 장치 글로벌 메모리에 저장되어 있음을 의미합니다.
- 단순 데이터 형식의 인수는 값별로 전달됩니다.
커널 본문은 C의 표준 코드와 전혀 다르지 않습니다.
중요: 문자열:
int i = get_global_id( 0 );
해당 셀 내의 계산 결과를 결정하는 GPU 내의 계산 셀 수입니다. 이 결과는 GPU 메모리에서 CPU 메모리로 어레이를 읽은 후 호스트 프로그램에 값이 추가되는 출력 어레이(예: out[])에 추가로 기록됩니다.
IOpenCL 프로그램 코드에는 두 개 이상의 기능이 있을 수 있습니다. 예를 들어, pi() 함수 외부에 위치한 간단한 인라인 함수를 "주요" 커널 함수 pi() 내부에서 호출할 수 있습니다. 이 경우는 앞으로 더 검토될 것입니다.
이제 MetaQuotes 구현에서 OpenCL API에 잠시 익숙해졌으므로 실험을 계속할 수 있습니다. 이 글에서 저자는 런타임을 최대한 최적화할 수 있는 하드웨어의 세부 사항에 대해서는 자세히 설명하지 않을 계획입니다. 현재 주요 작업은 OpenCL에서 프로그래밍의 시작점을 제공하는 것입니다.
다시 말해, 코드는 하드웨어 사양을 고려하지 않기 때문에 다소 순진합니다. 이와 동시에 CPU, AMD의 IGP(CPU에 통합된 GPU) 또는 AMD/NVidia의 이산형 비디오 카드 등 모든 하드웨어에서 실행할 수 있을 정도로 일반적입니다.
벡터 데이터 유형을 사용한 단순한 최적화를 고려하기 전에, 먼저 이러한 데이터 유형에 익숙해야 합니다.
4. 벡터 데이터 유형
벡터 데이터 유형은 OpenCL에만 적용되는 유형으로, C99와는 별도로 설정됩니다. 이러한 종류는 (u)charN, (u)shortN, (u)intN, (u)longN, floatN 이 있습니다, 여기서 N = {2|3|4|8|16}.
이러한 유형은 내장 컴파일러에서 계산을 추가로 병렬화할 수 있다는 것을 알고 있거나 가정할 때 사용되어야 합니다. 커널 코드가 N의 값만 다르고 다른 모든 면에서 동일하더라도(작성자가 직접 확인할 수 있음) 이러한 경우가 항상 있는 것은 아닙니다.
다음은 내장된 데이터 유형 목록입니다:

표 1. OpenCL에 내장된 벡터 데이터 유형
이러한 유형은 모든 장치에서 지원됩니다. 이러한 각 유형에는 커널과 호스트 프로그램 간의 통신을 위한 해당 유형의 API가 있습니다. 이것은 현재 MQL5 구현에서는 제공되지 않지만 큰 문제는 아닙니다.
추가 유형도 있지만 일부 장치에서 지원되지 않으므로 사용하려면 다음을 명시적으로 지정해야 합니다.

표 2. OpenCL에 내장된 벡터 데이터 유형
또한 아직 OpenCL에서 지원되지 않는 예약된 데이터 유형이 있습니다. 언어 사양에는 꽤 긴 목록이 있습니다.
벡터 유형의 상수 또는 변수를 선언하려면 단순하고 직관적인 규칙을 따라야 합니다.
아래에 몇 가지 예가 나와 있습니다.
float4 f = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f); uint4 u = ( uint4 ) ( 1 ); /// u is converted to a vector (1, 1, 1, 1). float4 f = ( float4 ) ( ( float2 )( 1.0f, 2.0f ), ( float2 )( 3.0f, 4.0f ) ); float4 f = ( float4 ) ( 1.0f, ( float2 )( 2.0f, 3.0f ), 4.0f ); float4 f = ( float4 ) ( 1.0f, 2.0f ); /// error
보시다시피 오른쪽에 있는 데이터 유형과 왼쪽에 선언된 변수의 "너비"를 합치면 충분합니다(여기서 4와 같음). 유일한 예외는 성분이 스칼라(줄 2)와 같은 벡터로 스칼라를 변환하는 것입니다.
모든 벡터 데이터 유형에 대해 벡터 성분을 다루는 간단한 메커니즘이 있습니다. 한편으로는 벡터(배열)이지만 다른 한편으로는 구조입니다. 예를 들어, 폭이 2인 벡터(예: float2 u)의 첫 번째 성분은 u.x로, 두 번째 성분은 u.y로 주소를 지정할 수 있습니다.
long3 u 유형의 벡터에 대한 세 가지 성분은 u.x, u.y, u.z 입니다.
float4 u 유형의 벡터의 경우, 따라서 .xyzw, 즉 u.x, u.y, u.z, u.w가 됩니다.
float2 pos; pos.x = 1.0f; // valid pos.z = 1.0f; // invalid because pos.z does not exist float3 pos; pos.z = 1.0f; // valid pos.w = 1.0f; // invalid because pos.w does not exist
한 번에 여러 구성요소를 선택하고 이를 순열할 수도 있습니다(그룹 표기법):
float4 c; c.xyzw = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); c.z = 1.0f; c.xy = ( float2 ) ( 3.0f, 4.0f ); c.xyz = ( float3 ) ( 3.0f, 4.0f, 5.0f ); float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 swiz= pos.wzyx; // swiz = ( 4.0f, 3.0f, 2.0f, 1.0f ) float4 dup = pos.xxyy; // dup = ( 1.0f, 1.0f, 2.0f, 2.0f )구성요소 그룹 표기법(예: 여러 구성요소의 사양)은 할당문 왼쪽(예: l-값)에서 발생할 수 있습니다.
float4 pos = ( float4 ) ( 1.0f, 2.0f, 3.0f, 4.0f ); pos.xw = ( float2 ) ( 5.0f, 6.0f ); // pos = ( 5.0f, 2.0f, 3.0f, 6.0f ) pos.wx = ( float2 ) ( 7.0f, 8.0f ); // pos = ( 8.0f, 2.0f, 3.0f, 7.0f ) pos.xyz = ( float3 ) ( 3.0f, 5.0f, 9.0f ); // pos = ( 3.0f, 5.0f, 9.0f, 4.0f ) pos.xx = ( float2 ) ( 3.0f, 4.0f ); // invalid as 'x' is used twice pos.xy = ( float4 ) (1.0f, 2.0f, 3.0f, 4.0f ); // mismatch between float2 and float4 float4 a, b, c, d; float16 x; x = ( float16 ) ( a, b, c, d ); x = ( float16 ) ( a.xxxx, b.xyz, c.xyz, d.xyz, a.yzw ); x = ( float16 ) ( a.xxxxxxx, b.xyz, c.xyz, d.xyz ); // invalid as the component a.xxxxxxx is not a valid vector type
개별 구성요소는 16진수 숫자 또는 그룹 표기법에서 여러 자리 앞에 삽입되는 문자(또는 S)를 사용하여 액세스할 수 있습니다.

표 3. 벡터 데이터 유형의 개별 구성요소에 액세스하는 데 사용되는 인덱스입니다.
벡터 변수 f를 선언하면,
float8 f;그러면 f.s0은 벡터의 첫 번째 성분이고 f.s7은 여덟 번째 성분입니다.
마찬가지로, 16차원 벡터 x를 선언하면,
float16 x;그런 다음 x.sa(또는 x.sA)는 벡터 x 의 11번째 성분이고 x.sf(또는 x.sF)는 벡터 x의 16번째 성분을 나타냅니다.
숫자 색인 (.s0123456789abcdef) and 문자 표기 (.xyzw) 는 성분 그룹 표기법과 동일한 식별자에서 혼용할 수 없습니다.
float4 f, a; a = f.x12w; // invalid as numeric indices are intermixed with the letter notations .xyzw a.xyzw = f.s0123; // valid
마지막으로, .lo, .hi, .even, .odd.를 사용하여 벡터 유형 구성요소를 조작할 수 있는 또 다른 방법이 있습니다.
이러한 접미사는 다음과 같이 사용됩니다:
- .lo 는 주어진 벡터의 하반부를 나타냅니다;
- .hi 는 주어진 벡터의 상반부를 나타냅니다;
- .even 은 벡터의 모든 짝수 성분을 말합니다;
- .odd 는 벡터의 모든 홀수 성분을 나타냅니다.
예를 들어 다음과 같습니다:
float4 vf; float2 low = vf.lo; // vf.xy float2 high = vf.hi; // vf.zw float2 even = vf.even; // vf.xz float2 odd = vf.odd; // vf.yw
이 표기법은 스칼라(벡터가 아닌 데이터 유형)가 나타날 때까지 반복적으로 사용할 수 있습니다.
float8 u = (float8) ( 1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f ); float2 s = u.lo.lo; // ( 1.0f, 2.0f ) float2 t = u.hi.lo; // ( 5.0f, 6.0f ) float2 q = u.even.lo; // ( 1.0f, 3.0f ) float r = u.odd.lo.hi; // 4.0f
상황은 3-성분 벡터 유형에서 약간 더 복잡합니다. 기술적으로 4번째 성분의 값이 정의되지 않은 4-성분 벡터 유형입니다.
float3 vf = (float3) (1.0f, 2.0f, 3.0f); float2 low = vf.lo; // ( 1.0f, 2.0f ); float2 high = vf.hi; // ( 3.0f, undefined );
간단한 산술 규칙(+, -, *, /)
지정된 모든 산술 연산은 동일한 차원의 벡터에 대해 정의되며 성분별로 수행됩니다.
float4 d = (float4) ( 1.0f, 2.0f, 3.0f, 4.0f ); float4 w = (float4) ( 5.0f, 8.0f, 10.0f, -1.0f ); float4 _sum = d + w; // ( 6.0f, 10.0f, 13.0f, 3.0f ) float4 _mul = d * w; // ( 5.0f, 16.0f, 30.0f, -4.0f ) float4 _div = w / d; // ( 5.0f, 4.0f, 3.333333f, -0.25f )
유일한 예외는 피연산자 중 하나는 스칼라이고 다른 하나는 벡터일 때입니다. 이 경우, 스칼라 유형은 벡터에 선언된 데이터 유형에 캐스팅되지만 스칼라 자체는 벡터 피연산자와 동일한 차원을 가진 벡터로 변환됩니다. 그 다음에는 산술 연산이 나옵니다. 관계형 연산자(<, >, <=, >=)도 마찬가지입니다.
파생된 C99 네이티브 데이터 유형(예: 구조, 결합, 배열 등)은 OpenCL 언어에서도 지원됩니다.
마지막으로, 정확한 계산을 위해 GPU를 사용하려면 불가피하게 이중 데이터 유형과 doubleN을 사용해야 합니다.
이를 위해, 그 줄을 삽입하기만 하면 됩니다:
#pragma OPENCL EXTENSION cl_khr_fp64 : enable 커널 코드의 시작 부분에 있습니다.
이 정보는 이미 다음에 나오는 많은 내용을 이해하기에 충분할 것입니다. 질문이 있으면 OpenCL 1.1 사양을 참조하십시오.
5. 벡터 데이터 유형을 사용한 커널 구현
솔직히 말해서, 저자는 벡터 데이터 형식을 사용하는 작업 코드를 즉시 작성하지 못했습니다.
처음에 저자는 벡터 데이터 유형(예: double8)이 커널 내에서 선언되는 즉시 모든 것이 저절로 해결될 것이라고 생각하며 언어 사양을 읽는 데 큰 관심을 기울이지 않았습니다. 또한, 작성자가 오직 하나의 출력 어레이만 이중 8 벡터의 배열로 선언하려고 시도한 시도도 실패했습니다.
커널을 효과적으로 벡터화하고 실제 가속화를 달성하기에는 이 방법이 절대적으로 충분하지 않다는 사실을 깨닫는 데 시간이 좀 걸렸습니다. 데이터를 빠르게 입력 및 출력할 필요가 없을 뿐만 아니라 빠르게 계산해야 하기 때문에 벡터 어레이에서 결과를 출력해도 문제가 해결되지 않습니다. 이러한 사실을 깨닫게 됨에 따라 프로세스 속도가 빨라지고 효율성이 향상되어 최종적으로 훨씬 더 빠른 코드를 개발할 수 있게 되었습니다.
하지만 그것보다 더 많은 것이 있습니다. 위에서 설명한 커널 코드를 거의 맹목적으로 디버깅할 수 있지만, 이제는 벡터 데이터의 사용으로 인해 오류를 찾는 것이 상당히 어려워졌습니다. 이 표준 메시지에서 얻을 수 있는 건설적인 정보는 무엇입니까?
ERR_OPENCL_INVALID_HANDLE - invalid handle to the OpenCL program
아니면 이것일까요
ERR_OPENCL_KERNEL_CREATE - internal error while creating an OpenCL object
?
따라서 저자는 SDK에 의존해야 했습니다. 이 경우 작성자가 사용할 수 있는 하드웨어 구성에 따라 Intel OpenCL SDK 오프라인 컴파일러(32비트)가 Intel OpenCL SDK로 제공되었습니다(Intel이 아닌 CPU/GPU의 경우 SDK에도 관련 오프라인 컴파일러를 포함해야 함). 호스트 API에 바인딩하지 않고 커널 코드를 디버그할 수 있기 때문에 편리합니다.
커널 코드를 컴파일러 창에 삽입하기만 하면 됩니다. 단, 외부 따옴표 문자와 "\r\n"(캐리지 리턴 문자)이 없는 대신, 커널 코드를 컴파일러 창에 삽입하고 기어 휠 아이콘이 있는 빌드 버튼을 누릅니다.
이렇게 하면 빌드 로그 창에 빌드 프로세스 및 진행률에 대한 정보가 표시됩니다:
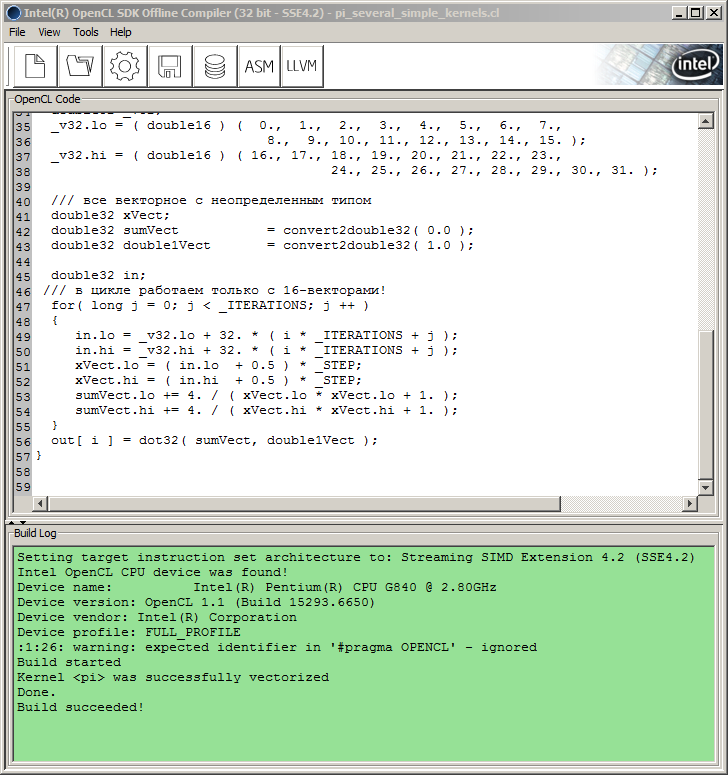
그림 9. Intel OpenCL SDK 오프라인 컴파일러에서 프로그램 컴파일
따옴표 문자 없이 커널 코드를 얻으려면, 커널 코드를 파일로 출력하는 단순 프로그램(MQL5)을 호스트 언어(WriteCLProgram())로 작성하는 것이 유용합니다. 이제 호스트 프로그램 코드에 포함됩니다.
컴파일러의 메시지가 항상 명확하지는 않지만 현재 MQL5보다 훨씬 많은 정보를 제공합니다. 오류는 컴파일러 창에서 즉시 수정할 수 있으며 오류가 더 이상 없는지 확인한 후에는 수정 사항을 MetaEditor의 커널 코드로 전송할 수 있습니다.
그리고 마지막입니다. 저자의 초기 아이디어는 단일 전역 매개변수 "채널 수"를 설정하여 double4, double8 및 double16 벡터로 작업할 수 있는 벡터화 코드를 개발하는 것이었습니다. 토큰 붙여넣기 연산자(token-pasting operator) ##을 사용하기 위해 며칠을 고생한 끝에, 몇가지 이유로, 커널 코드 내에서 작업을 거부하게 되었습니다.
이 기간 동안 작성자는 세 개의 커널 코드(4, 8 또는 16)를 각각 사용하여 스크립트의 작업 코드를 성공적으로 개발했습니다. 이 중간 코드는 기사에 제공되지 않지만 커널 코드를 작성하려는 경우 언급할 가치가 있습니다. 이 스크립트 구현의 코드 (OCL_pi_double_several_simple_kernels.mq5)는 아래 문서 끝에 첨부되어 있습니다.
다음은 벡터화된 커널의 코드입니다:
"/// enable extensions with doubles \r\n" "#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _intrnCnt ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" "#define _CH " + i2s( _ch ) + " \r\n" "#define _DOUBLETYPE double" + i2s( _ch ) + " \r\n" " \r\n" "/// extensions for 4-, 8- and 16- scalar products \r\n" "#define dot4( a, b ) dot( a, b ) \r\n" " \r\n" "inline double dot8( double8 a, double8 b ) \r\n" "{ \r\n" " return dot4( a.lo, b.lo ) + dot4( a.hi, b.hi ); \r\n" "} \r\n" " \r\n" "inline double dot16( double16 a, double16 b ) \r\n" "{ \r\n" " double16 c = a * b; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot4( c.lo.lo + c.lo.hi + c.hi.lo + c.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double16 v16 = ( double16 ) ( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ); \r\n" " double8 v8 = v16.lo; \r\n" " double4 v4 = v16.lo.lo; \r\n" " double2 v2 = v16.lo.lo.lo; \r\n" " \r\n" " /// all vector-related with the calculated type \r\n" " _DOUBLETYPE in; \r\n" " _DOUBLETYPE xVect; \r\n" " _DOUBLETYPE sumVect = ( _DOUBLETYPE ) ( 0.0 ); \r\n" " _DOUBLETYPE doubleOneVect = ( _DOUBLETYPE ) ( 1.0 ); \r\n" " _DOUBLETYPE doubleCHVect = ( _DOUBLETYPE ) ( _CH + 0. ); \r\n" " _DOUBLETYPE doubleSTEPVect = ( _DOUBLETYPE ) ( _STEP ); \r\n" " \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in = v" + i2s( _ch ) + " + doubleCHVect * ( i * _ITERATIONS + j ); \r\n" " xVect = ( in + 0.5 ) * doubleSTEPVect; \r\n" " sumVect += 4.0 / ( xVect * xVect + 1. ); \r\n" " } \r\n" " out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n" "} \r\n";
외부 호스트 프로그램은 "벡터화 채널"의 수를 설정하는 새로운 글로벌 constant _ch과 _ch 수를 작게하는 글로벌 constant _intrnCnt을 제외하고는 크게 변경되지 않았습니다. 그래서 저자는 여기에 호스트 프로그램 코드를 표시하지 않기로 했습니다. 아래 첨부된 스크립트 파일(OCL_pi_double_parallel_straight.mq5)에서 찾을 수 있습니다.
알 수 있듯이, 커널 pi()의 "메인" 함수 외에도, 이제 벡터 dotN(a, b )의 스칼라 곱을 결정하는 두 개의 인라인 함수와 매크로 대체를 하나 가지게 되었습니다. 이러한 함수는 차원이 4를 초과하지 않는 벡터와 관련하여 OpenCL의 dot() 함수가 정의된다는 사실과 관련이 있습니다.
dot() 함수를 재정의하는 dot4() 매크로는 계산된 이름으로 dotN() 함수를 호출하는 편의상 사용할 수 있습니다.
" out[ i ] = dot" + i2s( _ch ) + "( sumVect, doubleOneVect ); \r\n"
우리가 만약, 인덱스 4가 없는채로, 보통 유형인 dot() 함수를 사용했다면, _ch = 4 (벡터화 채널의 수가 4와 같음)일 때 여기서와 같이 쉽게 호출할 수 없었을 것입니다.
이 행은 호스트 프로그램 내에서 문자열로 취급되는 특정 커널 형식의 또 다른 유용한 기능을 보여줍니다. 함수뿐만 아니라 데이터 유형에도 커널에서 계산된 식별자를 사용할 수 있습니다!
이 커널이 포함된 전체 호스트 프로그램 코드는 아래에 첨부되어 있습니다 (OCL_pi_double_parallel_straight.mq5).
벡터 "width"가 16(_ch = 16)인 스크립트를 실행하면 다음이 나타납니다:
2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) ================================================== 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) CPUtime / GPUtime = 4.130 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The time to calculate PI was 8.830 seconds 2012.05.15 00:15:47 OCL_pi_double2_parallel_straight (EURUSD,H1) SMARTER: The value of PI is 3.141592653590 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The time to calculate PI was 8.002 seconds 2012.05.15 00:15:38 OCL_pi_double2_parallel_straight (EURUSD,H1) DULL: The value of PI is 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: gone = 2.138 sec. 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) OPENCL: pi = 3.141592653590 2012.05.15 00:15:30 OCL_pi_double2_parallel_straight (EURUSD,H1) read = 20000 elements 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) CLProgramCreate: unknown error. 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.15 00:15:28 OCL_pi_double2_parallel_straight (EURUSD,H1) ==================================================
벡터 데이터 유형을 사용한 최적화로도 커널의 속도가 빨라지지 않았음을 알 수 있습니다.
그러나 GPU에서 동일한 코드를 실행하면 속도가 훨씬 향상됩니다.
MetaDriver (비디오 카드 - HIS Radeon HD 6930, CPU - AMD Phenom II x6 1100T) 에서 제공하는 정보에 따르면, 동일한 코드가 다음과 같은 결과를 산출합니다:
2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) ================================================== 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) CPUtime / GPUtime = 84.983 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The time to calculate PI was 14.617 seconds 2012.05.14 11:36:07 OCL_pi_double2_parallel_straight (AUDNZD,M5) SMARTER: The value of PI is 3.141592653590 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The time to calculate PI was 14.040 seconds 2012.05.14 11:35:52 OCL_pi_double2_parallel_straight (AUDNZD,M5) DULL: The value of PI is 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: gone = 0.172 sec. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) read = 20000 elements 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) CLProgramCreate: unknown error. 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _intrnCnt = 3125 2012.05.14 11:35:38 OCL_pi_double2_parallel_straight (AUDNZD,M5) ==================================================
6. 마무리 터치
여기 또 다른 커널이 있습니다(아래에 첨부된 OCL_pi_double_several_simple_kernels.mq5 파일에서 찾을 수 있지만 여기에 나와 있지 않습니다).
이 스크립트는 작가가 일시적으로 "단일" 커널을 쓰려는 시도를 포기하고 다른 벡터 차원(4, 8, 16, 32)에 대해 4개의 간단한 커널을 쓰려고 했을 때 가졌던 아이디어를 구현한 것입니다.
"#pragma OPENCL EXTENSION cl_khr_fp64 : enable \r\n" "#define _ITERATIONS " + i2s( _itInKern ) + " \r\n" "#define _STEP " + d2s( _step, 12 ) + " \r\n" " \r\n" "typedef struct \r\n" "{ \r\n" " double16 lo; \r\n" " double16 hi; \r\n" "} double32; \r\n" " \r\n" "inline double32 convert2double32( double a ) \r\n" "{ \r\n" " double32 b; \r\n" " b.lo = ( double16 )( a ); \r\n" " b.hi = ( double16 )( a ); \r\n" " return b; \r\n" "} \r\n" " \r\n" "inline double dot32( double32 a, double32 b ) \r\n" "{ \r\n" " double32 c; \r\n" " c.lo = a.lo * b.lo; \r\n" " c.hi = a.hi * b.hi; \r\n" " double4 _1 = ( double4 ) ( 1., 1., 1., 1. ); \r\n" " return dot( c.lo.lo.lo + c.lo.lo.hi + c.lo.hi.lo + c.lo.hi.hi + \r\n" " c.hi.lo.lo + c.hi.lo.hi + c.hi.hi.lo + c.hi.hi.hi, _1 ); \r\n" "} \r\n" " \r\n" "__kernel void pi( __global double *out ) \r\n" "{ \r\n" " int i = get_global_id( 0 ); \r\n" " \r\n" " /// define vector constants \r\n" " double32 _v32; \r\n" " _v32.lo = ( double16 ) ( 0., 1., 2., 3., 4., 5., 6., 7., \r\n" " 8., 9., 10., 11., 12., 13., 14., 15. ); \r\n" " _v32.hi = ( double16 ) ( 16., 17., 18., 19., 20., 21., 22., 23., \r\n" " 24., 25., 26., 27., 28., 29., 30., 31. ); \r\n" " \r\n" " /// all vector-related with undefined type \r\n" " double32 xVect; \r\n" " double32 sumVect = convert2double32( 0.0 ); \r\n" " double32 double1Vect = convert2double32( 1.0 ); \r\n" " \r\n" " double32 in; \r\n" " /// work only with 16-vectors in the loop! \r\n" " for( long j = 0; j < _ITERATIONS; j ++ ) \r\n" " { \r\n" " in.lo = _v32.lo + 32. * ( i * _ITERATIONS + j ); \r\n" " in.hi = _v32.hi + 32. * ( i * _ITERATIONS + j ); \r\n" " xVect.lo = ( in.lo + 0.5 ) * _STEP; \r\n" " xVect.hi = ( in.hi + 0.5 ) * _STEP; \r\n" " sumVect.lo += 4. / ( xVect.lo * xVect.lo + 1. ); \r\n" " sumVect.hi += 4. / ( xVect.hi * xVect.hi + 1. ); \r\n" " } \r\n" " out[ i ] = dot32( sumVect, double1Vect ); \r\n" "} \r\n";
바로 이 커널은 벡터 차원 32를 구현합니다. 새로운 벡터 유형과 몇 가지 필요한 인라인 함수는 커널의 주 함수 외부에 정의됩니다. 이 외에도 주 루프 내의 모든 계산은 의도적으로 표준 벡터 데이터 유형만 사용하여 이루어집니다. 비표준 유형은 루프 외부에서 처리됩니다. 이를 통해 코드 실행 시간을 크게 단축할 수 있습니다.
계산 결과, 이 커널은 폭이 16인 벡터에 사용할 때보다 속도가 느리지는 않지만 속도가 그리 빠르지 않습니다.
MetaDriver에서 제공하는 정보에 따르면 , 이 커널(_ch=32)이 포함된 스크립트는 다음과 같은 결과를 제공합니다:
2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: gone = 0.156 sec. 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) OPENCL: pi = 3.141592653590 2012.05.14 12:05:33 OCL_pi_double32-01 (AUDNZD,M5) read = 10000 elements 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) CLProgramCreate: unknown error or no error. 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) GetLastError returned .. 0 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) DOUBLE2: _step = 0.000000001000; _itInKern = 3125; vectorization channels - 32 2012.05.14 12:05:32 OCL_pi_double32-01 (AUDNZD,M5) =================================================================
요약 및 결론
저자는 OpenCL 리소스를 시연하기 위해 선택한 작업이 이 언어의 일반적인 방식이 아니라는 것을 잘 이해하고 있습니다.
교과서를 가지고 큰 행렬의 곱셈의 표준적인 예를 여기에 게시하는 것이 훨씬 쉬웠을 것입니다. 그 예가 분명 인상적일 것 입니다. 그러나 대형 매트릭스의 곱셈이 필요한 재무 계산에 종사하는 mql5.com 포럼 사용자가 많습니까? 그것은 상당히 의심스럽습니다. 작가는 자신의 본보기를 택해 스스로 길을 가면서 부딪히는 모든 어려움을 극복하는 동시에 자신의 경험을 다른 사람들과 공유하고자 했습니다. 물론, 당신이 판단해야 할 사람입니다, 친애하는 포럼 사용자 여러분.
OpenCL 에뮬레이션("베어" CPU에서)의 효율성 향상은 MetaDriver 스크립트를 사용하여 얻은 수백 또는 수천 개에 비해 매우 적은 것으로 나타났습니다. 그러나 적절한 GPU에서는, CPU AMD를 사용하는 CPU에서 약간 긴 런타임은 무시하더라도, 에뮬레이션보다 적어도 한 단위는 더 큽니다. OpenCL은 컴퓨팅 속도의 이득이 그렇더라도, 여전히 배울 가치가 있습니다!
저자의 다음 기사에서는 실제 하드웨어에 OpenCL 추상 모델을 표시하는 것과 관련된 문제를 다룰 예정입니다. 이러한 지식을 통해 때때로 계산 속도를 상당히 높일 수 있습니다.
저자는 매우 귀중한 프로그래밍 및 성능 최적화 팁을 주신 MetaDriver와 Intel OpenCL SDK 사용 가능성에 대한 지원 팀에 특별히 감사의 뜻을 전합니다.
첨부된 파일의 내용:
- pi.mq5 - "pi" 값을 계산하는 두 가지 방법을 특징으로 하는 순수 MQL5의 스크립트;
- OCl_pi_float.mq5 - float 유형을 사용한 실제 계산을 포함하는 OpenCL 커널을 사용한 스크립트의 첫 번째 구현;
- OCL_pi_double.mq5 - 동일하며, 이중 유형의 실제 계산만 포함;
- OCL_pi_double_several_simple_kernels.mq5 - 다양한 벡터 "widths"(4, 8, 16, 32)에 대한 여러 특정 커널을 포함하는 스크립트;
- OCL_pi_double_parallel_straight.mq5 - 일부 벡터 "widths"(4, 8, 16)에 대한 단일 커널을 포함하는 스크립트.